1.先简单看一看JVM内存结构

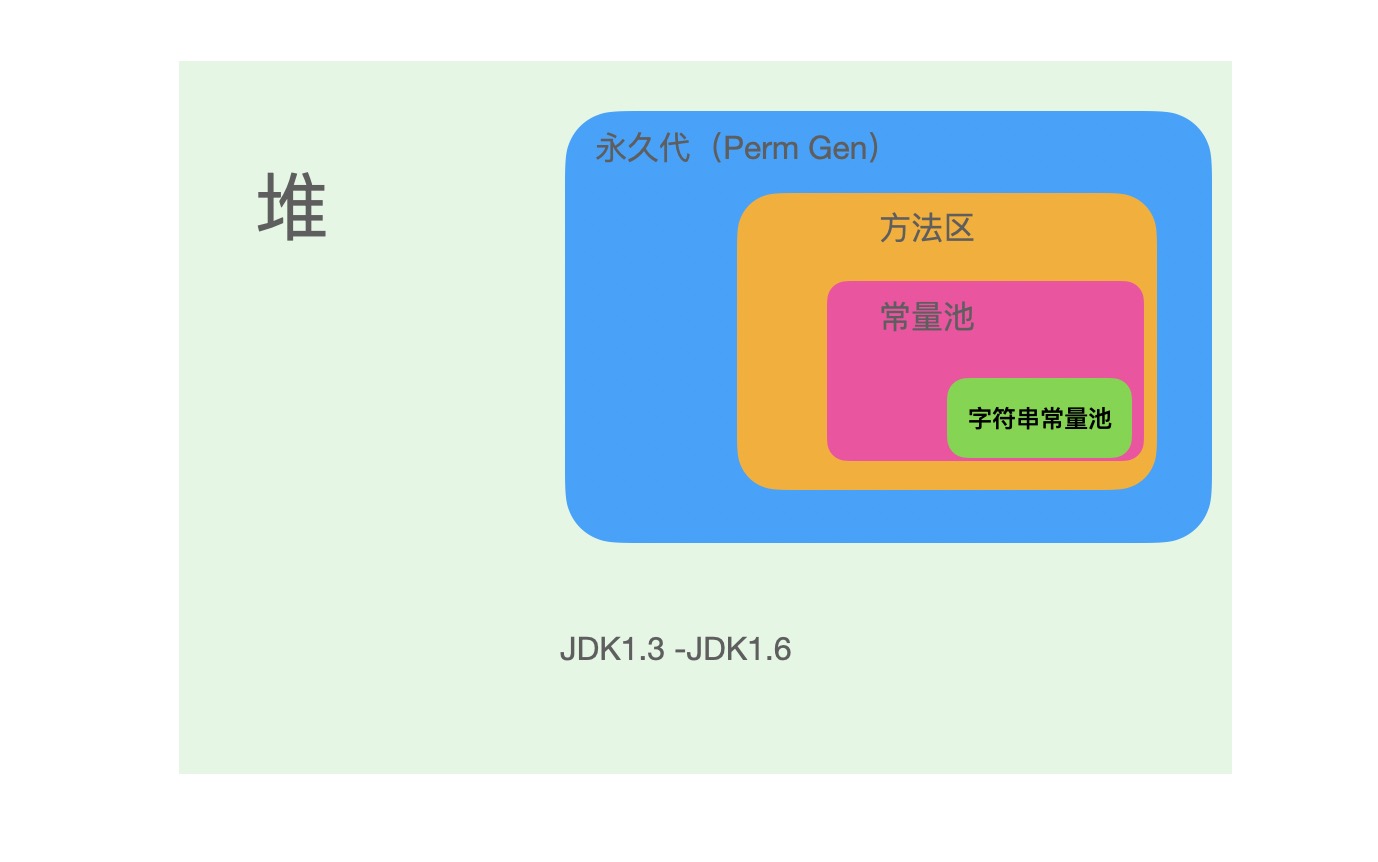
方法区&#xff1a; 该区为各个线程共享&#xff0c;用于存储已经被虚拟机加载的类信息、常量、静态变量、即时编译器编译出来的代码等数据。
常量池就在这个区域
堆&#xff1a; Heap区被所有的线程共享&#xff0c;在虚拟机启动时创建。此区的功能就是存放对象实例&#xff0c;几乎所有的对象实例都是在这里分配内容。Heap区垃圾回收器管理的主要区域。
2.创建字符串对象
public class TestDemo {public static void main(String[] args) {String a &#61; "1";String b &#61; "1";String c &#61; b;System.out.println(a &#61;&#61; b);System.out.println(c &#61;&#61; b);String d &#61; new String("test");String e &#61; new String("1");String f &#61; new String(a);System.out.println(d &#61;&#61; a);System.out.println(e &#61;&#61; d);String g &#61; "hello" &#43; "tomorrow";String h &#61; new String("hello") &#43; new String("world");}
}
首先&#xff0c;看一下
String a &#61; "1";String b &#61; "1";String c &#61; b;System.out.println(a &#61;&#61; b);System.out.println(c &#61;&#61; b);

控制台返回 true
分析上述代码的输出结果&#xff1a; 上述代码&#xff0c;只创建了一个对象
- 首先&#xff0c;jvm在编译阶段会判断方法区常量池中是否有 “1” 这个常量对象&#xff08;
String a &#61; "1";&#xff09;
如果有&#xff0c;a直接指向这个常量的引用
如果没有&#xff0c;就在常量池里创建这个常量对象 - 此过程并没有在堆中创建对象
String b &#61; "1"; 直接将 常量对象"1" 的地址交给了b&#xff0c;String c &#61; b; 将 b 指向的 常量对象"1" 的地址交给了c- 当使用
&#61;&#61;判断时&#xff0c;都是在对比 常量池中的 常量对象"1" 的地址&#xff0c;故而相同&#xff0c;返回true
接着来看看
String d &#61; new String("test");
分析&#xff1a; 上述代码&#xff0c;创建了两个对象
- 首先&#xff0c;jvm在编译阶段会判断方法区常量池中是否有 “test” 这个常量对象&#xff0c;没有就创建
- 其次&#xff0c;通过
new 在 堆 中创建 String对象&#xff0c;d 指向的就是这个String对象的地址
继续看
String e &#61; new String("1");String f &#61; new String(a);System.out.println(d &#61;&#61; a);System.out.println(e &#61;&#61; d);System.out.println(e &#61;&#61; f);

控制台返回 false
分析上述代码的输出结果&#xff1a; 上述代码&#xff0c;创建了2个对象
- 首先&#xff0c;常量池中已经有了 “1” &#xff0c;且 a 指向的也是 “1” 的地址
- 所以&#xff0c;此过程只在堆中用
new创建两个 String 对象 - 虽然他们的字符串常量值都是 1&#xff0c;但是 e和f 指向的是两个不同的String对象的地址&#xff0c;所以返回值都为false
最后看&#xff1a;
String g &#61; "hello" &#43; "tomorrow";String h &#61; new String("hello") &#43; new String("world");
首先来分析String g &#61; "hello" &#43; "tomorrow"; 只创建了1个对象
- jvm编译阶段过编译器优化后会把字符串常量直接合并成"hellotomorrow"&#xff0c;所以最终只在常量池中创建了一个 “hellotomorrow” 常量对象
接着来看String h &#61; new String("hello") &#43; new String("world"); 创建了6个对象
- 首先
new 创建了一个 StringBuilder() 对象 - 接着
h &#61; new String("hello") &#43; new String("world") 创建了 4 个对象&#xff08;和上述创建过程相同&#xff09; - 最终
new 创建了一个对象 String(“ab”)
3.补充
Integer m &#61; 3;String s &#61; m.toString(m);
注意&#xff1a; 此过程调用Object.toString()&#xff0c;并没有在常量池中创建新的对象。




 京公网安备 11010802041100号
京公网安备 11010802041100号