作者:奔跑的饼干的饼干桶_698 | 来源:互联网 | 2023-09-16 10:41
先言:阅读数篇论文后,发觉自己基础不牢固,心生困惑无法解决,故再查阅整理相关内容发布于此。自监督的创新主要基于三个方面:1.基于代理任务的自监督学习三个阶段:Prediction-
先言:阅读数篇论文后,发觉自己基础不牢固,心生困惑无法解决,故再查阅整理相关内容发布于此。
自监督的创新主要基于三个方面:
1.基于代理任务的自监督学习
三个阶段:
- Prediction-based Tasks:
基于预测的自监督学习任务属于视觉自监督学习中相对早期的工作。如patch relation prediction(预测图片中两个patch的相对位置),rotation prediction(判断图片旋转角度),color prediction(对灰色图片上色)
- Contrastive-based Tasks:
如MoCo,simCLR等系列工作,通过对图片进行随机两种增强操作(裁剪,翻转等)构造正例对,拉近同一张图片不同形态的特征距离,拉远不同图片之间的特征距离。基于对比学习的方法虽然在ImageNet图片分类任务上取得不错的表现,但对于更细粒度的图片相关任务表现则欠佳,其更偏向于学习全局的图片语义特征。
- Generative-based Tasks:
由于对比学习任务在细粒度知识表征学习方面存在缺陷,受NLP预训练模型的启发,近期很多工作将重点放在如何有效地将MLM任务迁移到CV自监督学习中。如mask region prediction, mask frame prediction等任务。
基于MLM任务引申的视觉自监督表征学习工作:
- MST: Masked Self-Supervised Transformer for Visual Representation
- BEiT: BERT Pre-Training of Image Transformers
- EsViT: Efficient Self-supervised Vision Transformers for Representation Learning
- iBOT: Image BERT Pre-training with Online Tokenizer
- Masked Autoencoders Are Scalable Vision Learners
- PeCo: Perceptual Codebook for BERT Pre-training of Vision Transformers
- Masked Feature Prediction for Self-Supervised Visual Pre-Training
2.基于对比学习的自监督学习
对比学习希望习得某个表示模型,它能够将图片映射到某个投影空间,并在这个空间内拉近正例的距离,推远负例距离。
如果从防止模型坍塌的不同方法角度,我们可大致把现有方法划分为四种:基于负例的对比学习方法、基于对比聚类的方法、基于不对称网络结构的方法,以及基于冗余消除损失函数的方法
基于负例的对比学习方法:
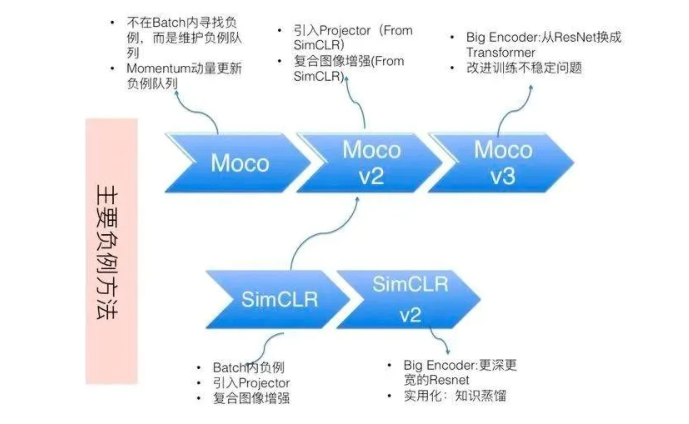
SimCLR系列及Moco系列;依靠负例(Uniformity属性)防止模型崩塌
基于对比聚类的方法:

SwAV;该方法要求某个投影点在超球面上,向另外一个投影点所属的聚类中心靠近,体现了Alignment原则;和其它聚类中心越远越好,这体现了Uniformity属性。SwAV面临模型坍塌问题,具体表现形式为:Batch内所有实例都聚类到同一个类里。所以为了防止模型坍塌,SwAV对聚类增加了约束条件,要求Batch内实例比较均匀地聚类到不同的类别中。本质上,它与直接采用负例的对比学习模型,在防止模型坍塌方面作用机制是类似的,是一种隐形的负例。
基于不对称网络结构的方法:

BYOL;只用正例来训练对比学习模型,靠上下分枝的结构不对称,防止模型坍塌。
基于冗余消除损失函数的方法:

Barlow Twins;既没有使用负例,也没有使用不对称结构,主要靠替换了一个新的损失函数,可称之为“冗余消除损失函数”,来防止模型坍塌。
对比学习Paper都会涉及到的一些关键点:
- 如何构造相似实例,以及不相似实例;
- 如何构造能够遵循上述指导原则的表示学习模型结构;
- 以及如何防止模型坍塌(Model Collapse);
评判对比学习的标准:

对比学习在做特征表示相似性计算时,要先对表示向量做L2正则,之后再做点积计算,或者直接采用Cosine相似性。
很多研究表明,把特征表示映射到单位超球面上,有很多好处。这里有两个关键,一个是单位长度,一个是超球面。首先,相比带有向量长度信息的点积,在去掉长度信息后的单位长度向量操作,能增加深度学习模型的训练稳定性。另外,当表示向量被映射到超球面上,如果模型的表示能力足够好,能够把相似的例子在超球面上聚集到较近区域,那么很容易使用线性分类器把某类和其它类区分开(参考上图)。在对比学习模型里,对学习到的表示向量进行L2正则,或者采用Cosine相似性,就等价于将表示向量投影到了单位超球面上进行相互比较。
Alignment和Uniformity:

Alignment:指的是相似的例子,也就是正例,映射到单位超球面后,应该有接近的特征,也即是说,在超球面上距离比较近
Uniformity:指的是系统应该倾向在特征里保留尽可能多的信息,这等价于使得映射到单位超球面的特征,尽可能均匀地分布在球面上,分布得越均匀,意味着保留的信息越充分。分布均匀意味着两两有差异,也意味着各自保有独有信息,这代表信息保留充分。
(这不就避免了模型崩塌的问题?)
模型坍塌(Collapse) :

Uniformity特性的极端反例,是所有数据映射到单位超球面同一个点上,所有数据经过特征表示映射过程后,都收敛到了同一个常数解,一般将这种异常情况称为模型坍塌(Collapse)。
以SimCLR为例解释:
见Reference:2(很不错,强推!)
3.基于掩码学习的自监督学习
自监督与预训练的关系:
1. 
2.常见的预训练方式分为生成式预训练与对比式预训练;
对比学习与聚类的关系:
声明:
本文中的所有参考内容均已在'Reference'中标注,仅供自己学习使用,如有侵权,立即删除。
Reference:
- 预训练中的自监督学习
- 对比学习(Contrastive Learning)在CV与NLP领域中的研究进展
2022-03-29 14:51:32 星期二








 京公网安备 11010802041100号
京公网安备 11010802041100号