作者:8o断情戒爱o8 | 来源:互联网 | 2023-09-03 13:23
VincentVanhoucke是Google的首席科学家,斯坦福大学电子工程学博士,目前在GoogleBrain主导机器人相关的项目。Vanhoucke主要的研究领域是语音识别、
Vincent Vanhoucke是Google的首席科学家,斯坦福大学电子工程学博士,目前在Google Brain主导机器人相关的项目。Vanhoucke主要的研究领域是语音识别、计算机视觉和机器人等领域,他还即将主持机器人领域的盛会CoRL 2017(Conference on Robot Learning)。
Vanhoucke认为,机器智能现在已经发展到一个相当的水准,在某些特定情境下的表现可以媲美(甚至超越)人类,比如机器视觉、机器翻译、语音识别,现在是时候让这些能力在物理世界中发挥效应了。他在今天的演讲中提到,robotics的研究现在也正面临着一场深度学习的革新,实现这一点,需要现在的机器学习从业者跳出监督学习的舒适区,面临一些棘手的问题:数据稀缺,如何使机器实现技能转换以及持续性的学习等等。Vanhoucke也提到,这也是人工智能从理论到实践的必经之路。
Vanhoucke分别介绍了他在图像、语音(及机器翻译)领域和机器人(主要是机械手抓取)的一些研究成果。雷锋网(公众号:雷锋网)作了部分节选。
Vanhoucke说,2011年,语音识别研究者采用神经网络技术降低语音识别,错误率大幅降低,是语音识别领域十多年来最大的进步;2016年,几乎就已经达到人类水准了。

而机器翻译,2014年机器学习的引入也让机器翻译有了质的进步,但要说达到人类水准,还是比较勉强……
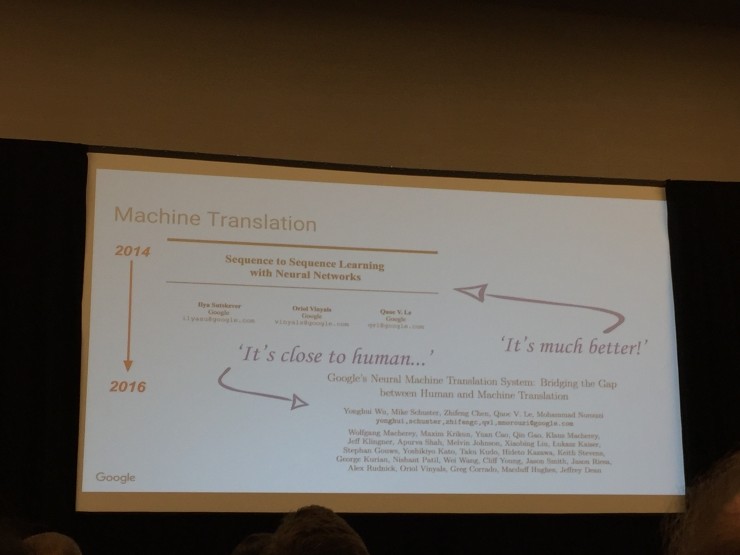
(看keynote上的名单,为Google的机器翻译做出贡献的,华人数量不少。)
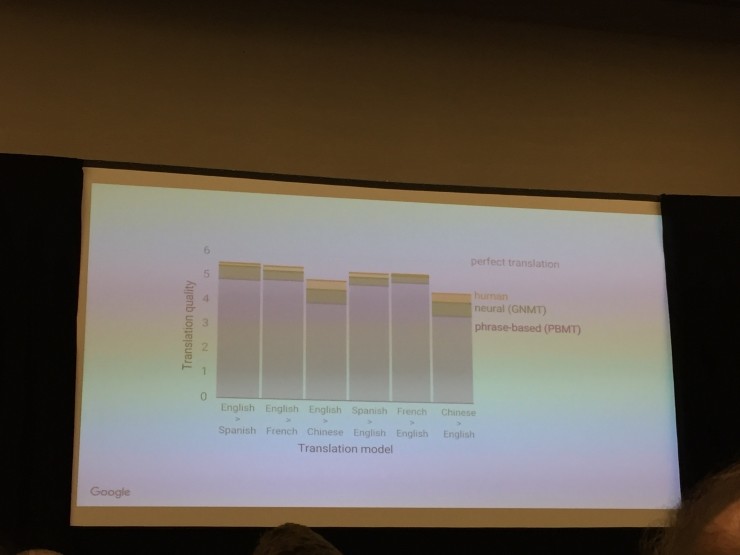
这个柱状图是人类翻译、神经网络翻译和PBMT翻译的质量差别,依次递减。
Vanhoucke认为,机器学习研究比过去更容易了,有更多的开源工具和模型,更多的网络教程(他自己就在Udacity上开了网络课程),GPU和高性能计算硬件门槛也变低了,研究者也比以前更多。

图片识别领域,除了底层技术的完善,Google已经将图片识别技术应用在医疗领域,帮助医生诊断病情,并且获得了一些成效。
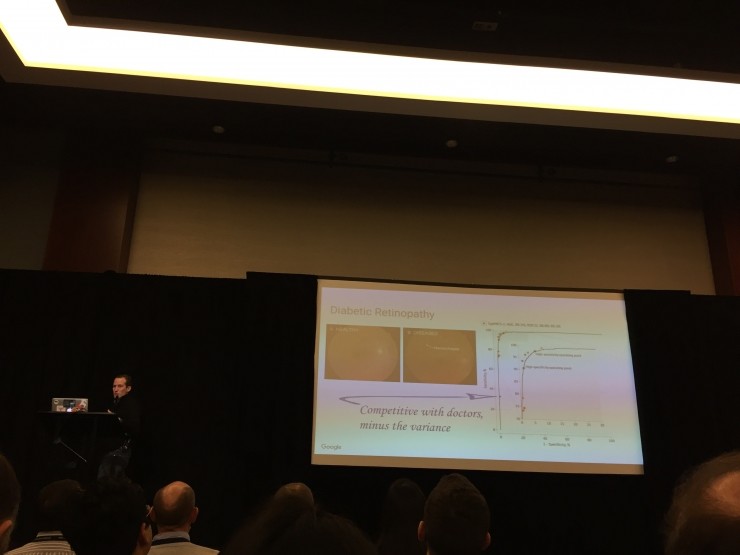
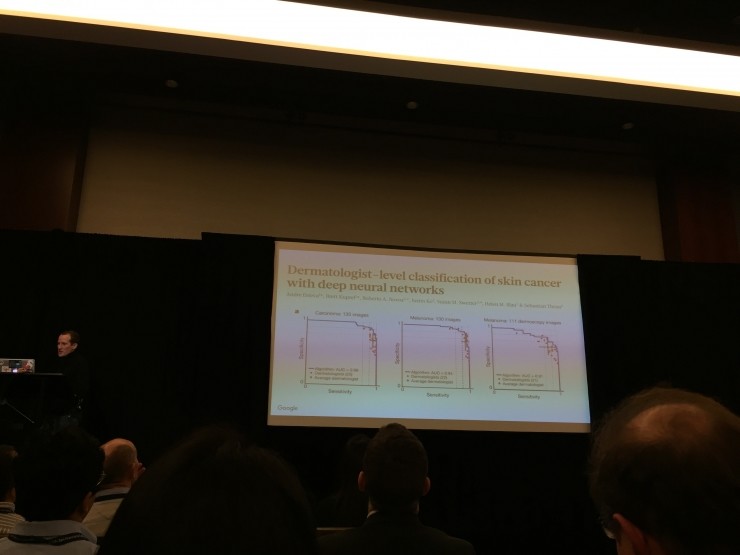
但他也说,图像识别现在远远没有到“succes”的地步,有40%基于图像监测做的决策,结果是很糟糕的。

接下来是机器人的部分。Vanhoucke是电子工程专业出身,在Google Brain主要的工作是机器人项目。他先强调了一个和很多人认知有出入的观点:目前的机器人研究其实跟深度学习没有多大关系。
他做了个示范,让手里的笔掉在地上,说,如果机器人的任务是抓取笔的话,那么抓住了和抓不住,从外部观察不到机器人的动作有什么差别(按:因此不能从中得到什么规律)。

机器抓取特定的物体是有迹可循的,抓取未知的物体尚无法解决。(Vanhoucke播了一段机器人摔跤集锦视频,说过去他觉得这些机器人摔跤很好笑,但是后来自己开始做机器人项目之后,看到这种画面就再也笑不出来了。研究机器抓取真的很难,但他很enjoy。)
越是少的图像识别技术介入,机器的鲁棒性就越好,能应对更复杂的物体。后续有听众问及抓取对象的数据库时,Vanhoucke说他们(Google)并不希望建立一个这样的知识图谱。

强化学习的引入对于机器人的研究可能有帮助,前提是先有一个能产生海量样本的参照模型。

最后的结论:

1、robotics和机器学习正在发生有意思的融合;
2、对于常规的robotics问题,要有做出不同答案的觉悟;
3、It hits all the right difficult problems on the road to practical AI。
。














 京公网安备 11010802041100号
京公网安备 11010802041100号