2019独角兽企业重金招聘Python工程师标准>>> 
Go语言内置以下这些基础类型:
- 布尔类型:bool,占1字节
- 整型:int8、byte(uint8)、int16、int、uint、uintptr等。
- 浮点类型:float32、float64。
- 复数类型:complex64、complex128。
- 字符串:string。
- 字符类型:rune(int32)。
- 错误类型:error。
此外,Go语言也支持以下这些复合类型:
- 指针(pointer)
- 数组(array)
- 切片(slice)
- 字典(map)
- 通道(chan)
- 结构体(struct)
- 接口(interface)
golang中,nil只能赋值给指针、channel、func、interface、map或slice类型的变量.
Go 也有基于架构的类型,例如:int、uint 和 uintptr。这些类型的长度都是根据运行程序所在的操作系统类型所决定的:
- int 和 uint 在 32 位操作系统上,它们均使用 32 位(4 个字节),在 64 位操作系统上,它们均使用 64 位(8 个字节)。
- uintptr 的长度被设定为足够存放一个指针即可。
Go 语言中没有 float 类型。
与操作系统架构无关的类型都有固定的大小,并在类型的名称中就可以看出来:
整数:
- int8(
-128 -> 127) - int16(
-32768 -> 32767) - int32(
-2,147,483,648 -> 2,147,483,647) - int64(
-9,223,372,036,854,775,808 -> 9,223,372,036,854,775,807)
无符号整数:
- uint8(
0 -> 255) - uint16(
0 -> 65,535) - uint32(
0 -> 4,294,967,295) - uint64(
0 -> 18,446,744,073,709,551,615)
浮点型(IEEE-754 标准):
- float32(
+- 1e-45 -> +- 3.4 * 1e38) - float64(
+- 5 * 1e-324 -> 107 * 1e308)
int 型是计算最快的一种类型。
float32 精确到小数点后 7 位,float64 精确到小数点后 15 位。由于精确度的缘故,你在使用 == 或者 != 来比较浮点数时应当非常小心.
你应该尽可能地使用 float64,因为 math 包中所有有关数学运算的函数都会要求接收这个类型。
各类型的最大值最小值在math包中定义。
类型声明可在builtin包中查看。
布尔类型
true、false
var v1 bool
v1 = true
v2 := (1 == 2) // v2也会被推导为bool类型
布尔类型不能接受其他类型的赋值,不支持自动或强制的类型转换。以下的示例是一些错误的用法,会导致编译错误:
var b bool
b = 1 // 编译错误
b = bool(1) // 编译错误
以下的用法才是正确的:
var b bool
b = (1!=0) // 编译正确
fmt.Println("Result:", b) // 打印结果为Result: true
整型
【注意1】int和int32在Go语言里被认为是两种不同的类型,编译器也不会帮你自动做类型转换,比如以下的例子会有编译错误:
var value2 int32
value1 := 64 // value1将会被自动推导为int类型
value2 = value1 // 编译错误
编译错误类似于:
cannot use value1 (type int) as type int32 in assignment。
使用强制类型转换可以解决这个编译错误:
value2 = int32(value1) // 编译通过
当然,开发者在做强制类型转换时,需要注意数据长度被截短而发生的数据精度损失(比如将浮点数强制转为整数)和值溢出(值超过转换的目标类型的值范围时)问题
【注意2】两个不同类型的整型数不能直接比较,比如int8类型的数和int类型的数不能直接比较,但各种类型的整型变量都可以直接与字面常量(literal)进行比较,比如:
var i int32
var j int64
i, j = 1, 2
if i == j { // 编译错误fmt.Println("i and j are equal.")
}
if i == 1 || j == 2 { // 编译通过fmt.Println("i and j are equal.")
}
进制
fmt.Println(0x10) // 十六进制 16
fmt.Println(010) // 八进制 8
e
2e3表示2*10^3=2000
前70个已经被缓存起来,可在math.Pow()中查看。
2e3或者2.0e3默认都是float64类型:
var i = 2e3
reflect.TypeOf(i) == float64
var i int = 2e3
reflect.TypeOf(i) == int
int64 和 uint64 的最大位赋值
var big int64 &#61; 1 <<63
fmt.Printf("%b\n", big)
报错&#xff1a;constant 9223372036854775808 overflows int64
var big uint64 &#61; 1 <<63
fmt.Printf("%b\n", big)
输出&#xff1a; 1000000000000000000000000000000000000000000000000000000000000000
这可能是因为 int64 中符号位也要占一个 bit。
int占多少位二进制
在 atoi.go 文件中&#xff1a;
const intSize &#61; 32 <<(^uint(0) >> 63)
位运算
x <x >> y右移x ^ y异或x & y与x | y或^x取反
位运算只能用于整数类型的变量&#xff0c;且需当它们拥有等长位模式时。
%b 是用于表示位的格式化标识符。
【&^】
位清除 &^&#xff1a;将指定位置上的值设置为 0
n1, n2 :&#61; 7, 3
fmt.Printf("%b &^ %b &#61; %b\n", n1, n2, n1&^n2) // 111 &^ 11 &#61; 100 末尾1,2位置零n1, n2 :&#61; 7, 2
fmt.Printf("%b &^ %b &#61; %b\n", n1, n2, n1&^n2) // 111 &^ 10 &#61; 101 末尾2位置零
【^x】
单独使用取反&#xff0c;结合使用异或。
该运算符与异或运算符一同使用&#xff0c;即 m^x&#xff0c;对于无符号 x 使用“全部位设置为 1”&#xff0c;对于有符号 x 时使用 m&#61;-1.
var n uint8 &#61; 2
fmt.Printf("^%b &#61; %b\n", n, ^n) // ^10 &#61; 11111101 即 253
var nn uint8 &#61; 0xFF
fmt.Printf("%b ^ %b &#61; %b\n", nn, n, nn^n) // 11111111 ^ 10 &#61; 11111101var n2 int8 &#61; 2
fmt.Printf("^%b &#61; %b\n", n2, ^n2) // ^10 &#61; -11 即 -3
var nn2 int8 &#61; -1
fmt.Printf("%b ^ %b &#61; %b\n", nn2, n2, nn2^n2) // -1 ^ 10 &#61; -11
对于无符号整型&#xff0c;取反相当于与 0xFF 异或
对于有符号整型&#xff0c;取反相当于与 -1 异或。
上面的操作都是以补码的形式进行的&#xff0c;正数的补码还是自身。
取反相当于补码和 11111111 异或&#xff0c;然后求补码。
【<<】
3<<2 &#61;> 11 <<2 &#61; 1100
-3<<1 &#61;> -11 <<1 &#61; -6(不求补码好像也可以)
【>>】
var n1 uint8 &#61; 7
var c uint8 &#61; 2
fmt.Printf("%b >> %d &#61; %b\n", n1, c, n1>>c) // 111 >> 2 &#61; 1var n2 int8 &#61; 7
fmt.Printf("%b >> %d &#61; %b\n", n2, c, n2>>c) // 111 >> 2 &#61; 1var n3 int8 &#61; -7
fmt.Printf("%b >> %d &#61; %b\n", n3, c, n3>>c) // -111 >> 2 &#61; -2
对于正数&#xff0c;右移时左边补0.
对于负数&#xff0c;以-7(-0111)为例&#xff0c;求补码(1 1001&#xff0c;第一位为1表示负数&#xff0c;其余位取反&#43;1&#xff0c;或者从右开始遇到第一个1&#xff0c;这个1之前的取反)&#xff0c;将补码右移2位&#xff0c;左边补1&#xff0c;变成1 1110&#xff0c;再求补码变成1 0010&#xff0c;即-2。
另外需要注意的是&#xff1a;-1 >> 1 &#61;&#61; -1, 避免陷入死循环。
【位左移常见实现存储单位的用例】
使用位左移与 iota 计数配合可优雅地实现存储单位的常量枚举&#xff1a;
type ByteSize float64
const (_ &#61; iota // 通过赋值给空白标识符来忽略值KB ByteSize &#61; 1<<(10*iota)MBGBTBPBEBZBYB
)
【在通讯中使用位左移表示标识的用例】
type BitFlag int
const (Active BitFlag &#61; 1 <
标志位操作
a :&#61; 0
a |&#61; 1 <<2 // 0000100: 在bit2设置标志位
a |&#61; 1 <<6 // 1000100: 在bit6设置标志位
a &#61; a &^ (1 <<6) // 0000100: 清除bit6标志位
移位操作右边的数不能是有符号数
bit :&#61; 2
a :&#61; 3 <
报错&#xff1a;invalid operation: 3 <
这样使用&#xff1a;
var bit uint &#61; 2
a :&#61; 3 <
浮点型
Go语言定义了两个类型float32和float64&#xff0c;其中float32等价于C语言的float类型&#xff0c;float64等价于C语言的double类型
var fvalue1 float32
fvalue1 &#61; 12
fvalue2 :&#61; 12.0 // 如果不加小数点&#xff0c;fvalue2会被推导为整型而不是浮点型
注意&#xff01;fvalue2默认被推导为float64
var val float32
val &#61; 3.0
val2 :&#61; 12.4 // val2被自动推导为float64
val &#61; val2 // 错误&#xff0c;不能将float64赋给float32
val &#61; float32(val2) // 使用强制转换
浮点数比较
浮点数不是一种精确的表达方式&#xff0c;所以像整型那样直接用&#61;&#61;来判断两个浮点数是否相等是不可行的&#xff0c;这可能会导致不稳定的结果。
下面是一种推荐的替代方案&#xff1a;
} import "math"
// p为用户自定义的比较精度&#xff0c;比如0.00001
func IsEqual(f1, f2, p float64) bool{ return math.Fdim(f1, f2)
通常应该优先使用float64类型&#xff0c;因为float32类型的累计计算误差很容易扩散&#xff0c;并且float32能精确表示的正整数并不是很大&#xff08;译注&#xff1a;因为float32的有效bit位只有23个&#xff0c;其它的bit位用于指数和符号&#xff1b;当整数大于23bit能表达的范围时&#xff0c;float32的表示将出现误差&#xff09;
var f float32 &#61; 16777216 // 1 <<24
fmt.Println(f &#61;&#61; f&#43;1) // "true"!
小数点前面或后面的数字都可能被省略&#xff08;例如.707或1.&#xff09;。 很小或很大的数最好用科学计数法书写&#xff0c;通过e或E来指定指数部分&#xff1a;
const Avogadro &#61; 6.02214129e23 // 阿伏伽德罗常数
const Planck &#61; 6.62606957e-34 // 普朗克常数
四舍五入
for _, n :&#61; range []float64{1.4, 1.5, 1.6, 2.0} {fmt.Println(n, "&#61;>", int(n&#43;0.5))}// 1// 2// 2// 2
复数类型
复数类型有complex64和complex128
复数表示
var value1 complex64 // 由2个float32构成的复数类型value1 &#61; 3.2 &#43; 12ivalue2 :&#61; 3.2 &#43; 12i // value2是complex128类型value3 :&#61; complex(3.2, 12) // value3结果同value2var value4 complex128 &#61; 3.2 &#43; 12i
实部和虚部
real(value1), imag(value1)
运算
复数的一些运算可在math/cmplx包中找到。
使用&#61;&#61;或!&#61;进行比较时注意精度。
字符串
- Go 中的字符串根据需要占用 1 至 4 个字节
- 和 C/C&#43;&#43; 一样&#xff0c;Go 中的字符串是根据长度限定&#xff0c;而非特殊字符。
- 获取字符串中某个字节的地址的行为是非法的&#xff0c;例如&#xff1a;&str[i]。
- str[i]的方式只对纯 ASCII 码的字符串有效。
- 和字符串有关的包&#xff1a;strings, strconv, unicode
var str string // 声明一个字符串变量str &#61; "Hello world" // 字符串赋值ch :&#61; str[0] // 取字符串的第一个字符fmt.Printf("The length of \"%s\" is %d \n", str, len(str))fmt.Printf("The first character of \"%s\" is %c.\n", str, ch)
输出结果为&#xff1a;
The length of "Hello world" is 11
The first character of "Hello world" is H.
【字符串嵌套】
var s &#61; "ni &#39;hao&#39;. "
var s &#61; &#96;ni "hao" .&#96;
【字符串修改】
字符串初始化后不能被改变
str :&#61; "Hello world" // 字符串也支持声明时进行初始化的做法
str[0] &#61; &#39;X&#39; // 编译错误
可以先将其转换成[]rune或[]byte&#xff0c;完成后再转换成string&#xff0c;无论哪种方式&#xff0c;都会重新分配内存&#xff0c;并复制字节数组。
s :&#61; "abc"
bs :&#61; []byte(s)
bs[1] &#61; &#39;B&#39;println(s, string(bs))u :&#61; "电脑"
us :&#61; []rune(u)
us[1] &#61; &#39;话&#39;println(u, string(us))
输出&#xff1a;
abc aBc
电脑 电话
【字符串连接】
s :&#61; "hello" &#43; " world"
s :&#61; "hello" &#43; " world " &#43; 3 // 错误
s :&#61; "hello" &#43; " world " &#43; string(31) // 正确&#xff0c;但不会输出31
&#43;的并不是最高效的做法&#xff0c;使用strings.Join()和bytes.Buffer更好些。
【字符串遍历】
方式一&#xff1a;
str :&#61; "hello,世界"for i, n :&#61; 0, len(str); i
输出&#xff1a;
0 &#61; &#39;h&#39; , 1 &#61; &#39;e&#39; , 2 &#61; &#39;l&#39; , 3 &#61; &#39;l&#39; , 4 &#61; &#39;o&#39; , 5 &#61; &#39;,&#39; , 6 &#61; &#39;ä&#39; , 7 &#61; &#39;¸&#39; , 8 &#61; &#39;&#39; , 9 &#61; &#39;ç&#39; , 10 &#61; &#39;&#39; , 11 &#61; &#39;&#39; ,
长度为12&#xff0c;每个中文字符在UTF-8中占3个字节。
方式二&#xff1a;
str :&#61; "hello,世界"for i, ch :&#61; range str {fmt.Print(i, "&#61; ")fmt.Print(ch, " ,") // ch的类型是runefmt.Printf("&#39;%c&#39; .", ch)}
输出&#xff1a;
0&#61; 104 ,&#39;h&#39; .1&#61; 101 ,&#39;e&#39; .2&#61; 108 ,&#39;l&#39; .3&#61; 108 ,&#39;l&#39; .4&#61; 111 ,&#39;o&#39; .5&#61; 44 ,&#39;,&#39; .6&#61; 19990 ,&#39;世&#39; .9&#61; 30028 ,&#39;界&#39; .
【中文字符截取】
strEn :&#61; "abcdef"strCn :&#61; "中文测试"fmt.Println(strEn[0:3]) // abcfmt.Println(strCn[0:3]) // 中fmt.Println(string([]rune(strCn)[0:3])) // 中文测func SubString(str string, begin, length int) (substr string) {// 将字符串的转换成[]runers :&#61; []rune(str)lth :&#61; len(rs)// 简单的越界判断if begin <0 {begin &#61; 0}if begin >&#61; lth {begin &#61; lth}end :&#61; begin &#43; lengthif end > lth {end &#61; lth}// 返回子串return string(rs[begin:end])
}fmt.Println(SubString("中文测试", 1, 3)) // 文测试fmt.Println(SubString("abcd", 1, 3)) // bcd
【中文字符串定位】
// 思路&#xff1a;首先通过strings库中的Index函数获得子串的字节位置&#xff0c;再通过这个位置获得子串之前的字节数组pre&#xff0c;
// 再将pre转换成[]rune&#xff0c;获得[]rune的长度&#xff0c;便是子串之前字符串的长度&#xff0c;也就是子串在字符串中的字符位置
// 这里用的是string.Index函数&#xff0c;类似的&#xff0c;也可以写中文字符串的类似strings中的IndexAny,LastIndex等函数
func UnicodeIndex(str, substr string) int {// 子串在字符串的字节位置result :&#61; strings.Index(str, substr)if result >&#61; 0 {// 获得子串之前的字符串并转换成[]byteprefix :&#61; []byte(str)[0:result]// 将子串之前的字符串转换成[]runers :&#61; []rune(string(prefix))// 获得子串之前的字符串的长度&#xff0c;便是子串在字符串的字符位置result &#61; len(rs)}return result
}fmt.Println(UnicodeIndex("中文测试", "文")) // 1fmt.Println(UnicodeIndex("abcd", "c")) // 2
【使用"&#96;"定义不做转义处理的原始字符串&#xff0c;支持跨行】
s :&#61; &#96;a
b\r\n\x00c&#96;println(s)
输出
a
b\r\n\x00c
注意上面第二行是顶行写的&#xff0c;不然缩进也是会如实反映的。
连接跨行字符串时&#xff0c;"&#43;" 必须在上一行末尾&#xff0c;否则导致编译错误
s :&#61; "hello, " &#43;"world!"s2 :&#61; "hello, "&#43;"World." // invalid operation: &#43; untyped string
【字符串和其他类型的转换】
strconv包。
- 不能用序号获取字节元素指针&#xff0c;&s[i]非法
- 不可变类型&#xff0c;无法修改字节数组
- 字节数组尾部不包含NULL
runtime.h
struct String{byte* str;intgo len;};
中文字符串长度
unicode/utf8 包中有一个RuneCountInString()
bytes包
- bytes 包和字符串包十分类似&#xff0c;而且它还包含一个十分有用的类型 Buffer。这是一个 bytes 的定长 buffer&#xff0c;提供 Read 和 Write 方法&#xff0c;因为读写不知道长度的 bytes 最好使用 buffer。
- Buffer 可以这样定义&#xff1a;
var buffer bytes.Buffer或者 new 出一个指针&#xff1a;var r *bytes.Buffer &#61; new(bytes.Buffer)或者通过函数&#xff1a;func NewBuffer(buf []byte) *Buffer&#xff0c;这就创建了一个 Buffer 对象并且用 buf 初始化好了&#xff1b;NewBuffer 最好用在从 buf 读取的时候使用。 - 通过 buffer 串联字符串&#xff1a;类似于 Java 的 StringBuilder 类 创建一个 Buffer&#xff0c;通过 buffer.WriteString(s) 方法将每个 string s 追加到后面&#xff0c;最后再通过 buffer.String() 方法转换为 string&#xff0c;下面是代码段&#xff1a;
var buffer bytes.Buffer
for {if s, ok :&#61; getNextString(); ok { //method getNextString() not shown herebuffer.WriteString(s)} else {break}
}
fmt.Print(buffer.String(), "\n")
这种实现方式比使用 &#43;&#61; 要更节省内存和 CPU&#xff0c;尤其是要串联的字符串数目特别多的时候。
字符类型
byte和rune
byte&#xff08;实际上是uint8的别名&#xff09;&#xff0c;代表UTF-8字符串的单个字节的值
rune&#xff08;int32&#xff09;&#xff0c;代表单个Unicode字符
var abc byteabc &#61; &#39;a&#39;fmt.Print(abc) // 97
如果abc &#61; ‘你’,会提示超出byte的范围
var abc runeabc &#61; &#39;你&#39;fmt.Print(abc) // 20320
字符数组
string &#61;> []byte
[]byte("hello")
[]byte &#61;> string
string([]byte)
可使用的库:bytes:
bytes.NewBuffer()
rune可做变量名
rune :&#61; rune(&#39;a&#39;)fmt.Println(rune) // 97
十六进制
var ch byte &#61; 65 或 var ch byte &#61; &#39;\x41&#39;
&#xff08;\x 总是紧跟着长度为 2 的 16 进制数&#xff09;
另外一种可能的写法是 \ 后面紧跟着长度为 3 的十进制数&#xff0c;例如&#xff1a;\377
一般使用格式 U&#43;hhhh 来表示&#xff0c;其中 h 表示一个 16 进制数。其实 rune 也是 Go 当中的一个类型&#xff0c;并且是 int32 的别名。
在书写 Unicode 字符时&#xff0c;需要在 16 进制数之前加上前缀 \u 或者 \U。
因为 Unicode 至少占用 2 个字节&#xff0c;所以我们使用 int16 或者 int 类型来表示。如果需要使用到 4 字节&#xff0c;则会加上 \U 前缀&#xff1b;前缀 \u 则总是紧跟着长度为 4 的 16 进制数&#xff0c;前缀 \U 紧跟着长度为 8 的 16 进制数。
var ch int &#61; &#39;\u0041&#39;var ch2 int &#61; &#39;\u03B2&#39;var ch3 int &#61; &#39;\U00101234&#39;fmt.Printf("%d - %d - %d\n", ch, ch2, ch3) // integerfmt.Printf("%c - %c - %c\n", ch, ch2, ch3) // characterfmt.Printf("%X - %X - %X\n", ch, ch2, ch3) // UTF-8 bytesfmt.Printf("%U - %U - %U", ch, ch2, ch3) // UTF-8 code point
输出&#xff1a;
65 - 946 - 1053236
A - β - r
41 - 3B2 - 101234
U&#43;0041 - U&#43;03B2 - U&#43;101234
一些常见的函数见unicode包
数组
[32]byte // 长度为32的数组&#xff0c;每个元素为一个字节
[2*N] struct{ x, y int32} // 复杂类型数组
[1000]*float64 // 指针数组
[3][5]int // 二维数组
[2][2][2]float64 // 等同于[2]([2]([2]float64))
数组长度在定义后就不可更改&#xff0c;在声明时长度可以为一个常量或者一个常量表达式&#xff08;常量表达式是指在编译期即可计算结果的表达式&#xff09;。
【数组长度】
var arr [10]byte
len(arr) // 10var arr [10][23]int
fmt.Println(len(arr)) // 10
【初始化】
arr :&#61; [5]int{1, 2, 3, 4, 5}
fmt.Println(arr[4]) // 5
b :&#61; [10]int{1, 2, 3}
声明了一个长度为10的int数组&#xff0c;其中前三个元素初始化为1、2、3&#xff0c;其它默认为0
如果不想写[5]&#xff0c;也可以使用[...]代替&#xff1a;
arr :&#61; [...]int{1, 2, 3, 4, 5}
也可以省略&#xff0c;什么都不写(这是数组还是切片&#xff1f;这是切片)
arr :&#61; []int{1, 2, 3}
指定索引来初始化
var names &#61; []string{1: "a",2: "b",4: "d",}
names[0]和names[3]都是""
数组指针
arr1 :&#61; new([3]int)fmt.Printf("arr1 type:%T\n", arr1) // arr1 type:*[3]intarr2 :&#61; [3]int{}fmt.Printf("arr2 type:%T\n", arr2) // arr2 type:[3]intfmt.Println(arr1, arr2) // &[0 0 0] [0 0 0]arr1[1] &#61; 4(*arr1)[2] &#61; 1arr2[1] &#61; 5fmt.Println(arr1, arr2) // &[0 4 1] [0 5 0]
【遍历】
方式一&#xff1a;
arr :&#61; [5]int{1, 3, 5, 7, 9}for i, n :&#61; 0, len(arr); i
方式二&#xff1a;
arr :&#61; [5]int{1, 3, 5, 7, 9}for i, v :&#61; range arr {fmt.Println(i, "&#61;>", v)}
方式三&#xff1a;&#xff08;range匿名变量&#xff09;
for i, v :&#61; range [5]int{1, 2, 3, 4} {fmt.Println(i, "&#61;>", v)}
【数组是值类型】
数组是一个值类型&#xff08;value type&#xff09;。所有的值类型变量在赋值和作为参数传递时都将产生一次复制动作。如果将数组作为函数的参数类型&#xff0c;则在函数调用时该参数将发生数据复制。因此&#xff0c;在函数体中无法修改传入的数组的内容&#xff0c;因为函数内操作的只是所传入数组的一个副本。
func main() {arr :&#61; [5]int{1, 2, 3, 4, 5}modify(arr)fmt.Println("in main() arr is: ", arr)
}func modify(arr [5]int) {arr[0] &#61; 10fmt.Println("in modify() arr is: ", arr)
}
输出结果&#xff1a;
in modify() arr is: [10 2 3 4 5]
in main() arr is: [1 2 3 4 5]
当然&#xff0c;也可以给函数传递一个数组的指针&#xff1a;
func sum(a *[3]float64) (sum float64) {for _, v :&#61; range *a {sum &#43;&#61; v}return
}arr :&#61; [...]float64{7.0, 5.4, 9.2}fmt.Println(sum(&arr))
不过&#xff0c;这种风格并不符合Go的语言习惯。相反的&#xff0c;应该使用切片。
优化
count[x] &#61; count[x] * scale可替换成count[x] *&#61; scale这样可以省去对变量表达式的重复计算
多维数组
// 声明了一个二维数组&#xff0c;该数组以两个数组作为元素&#xff0c;其中每个数组中又有4个int类型的元素doubleArray :&#61; [2][4]int{[4]int{1, 2, 3, 4}, [4]int{5, 6, 7, 8}}// 上面的声明可以简化&#xff0c;直接忽略内部的类型easyArray :&#61; [2][4]int{{1, 2, 3, 4}, {5, 6, 7, 8}}arr :&#61; [3][2]int{{1, 2},{3, 4},{5, 6}} // 如果最后的}放到下一行了&#xff0c;则需要使用,({5,6},)fmt.Println(arr[2]) // [5 6]towDimen :&#61; [][]string{[]string{"a", "b", "c"},[]string{"d", "e"},}
数组切片
数组切片的数据结构可以抽象为以下3个变量&#xff1a;
- 一个指向原生数组的指针&#xff1b;
- 数组切片中的元素个数&#xff1b;
- 数组切片已分配的存储空间
切片持有对底层数组的引用&#xff0c;如果你将一个切片赋值给另一个&#xff0c;二者都将引用同一个数组。如果函数接受一个切片参数&#xff0c;那么其对切片的元素所做的改动&#xff0c;对于调用者是可见的&#xff0c;好比是传递了一个底层数组的指针。因此&#xff0c;Read函数可以接受一个切片参数&#xff0c;而不是一个指针和一个计数&#xff1b;切片中的长度已经设定了要读取的数据的上限.
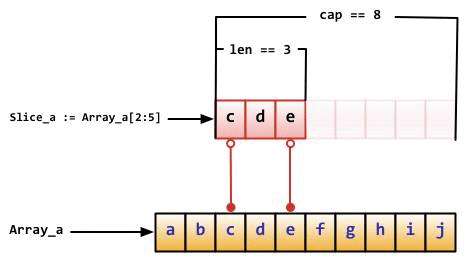
注意 绝对不要用指针指向 slice。slice 本身已经是一个引用类型&#xff0c;所以它本身就是一个指针!!
【创建切片】
方式一&#xff1a;在已有数组的基础上创建
arr :&#61; [5]int{1, 2, 3, 4, 5}
slice :&#61; arr[:4] // 前4个元素 0-3
fmt.Println(slice) // [1 2 3 4]slice :&#61; arr[1:] // 从1开始到结尾 [2 3 4 5]slice :&#61; arr[1:4] // 1-3 [2 3 4]slice :&#61; arr[:] // 全部
- 第一个数可以是0到len(arr)&#xff0c;包括len(arr)&#xff0c;此时切片是空的[],其余数则会报错
- 第二个数可以是0到len(arr),0时切片为[],其余报错
- 如果切arr[0:0]则切片len是0
切片的改变可影响原数组
arr :&#61; [3]int{1, 2, 3}slice :&#61; arr[:]slice[0] &#61; 5fmt.Printf("arr&#61;%v, slice&#61;%v", arr, slice) // arr&#61;[5 2 3], slice&#61;[5 2 3]
方式二&#xff1a;直接创建
创建一个初始元素个数为5的数组切片&#xff0c;元素初始值为0&#xff0c;cap为5&#xff1a;
mySlice1 :&#61; make([]int, 5)
创建一个初始元素个数为5的数组切片&#xff0c;元素初始值为0&#xff0c;并预留10个元素的存储空间&#xff1a;
mySlice2 :&#61; make([]int, 5, 10)
直接创建并初始化包含5个元素的数组切片(len和cap都为5)&#xff1a;
mySlice3 :&#61; []int{1, 2, 3, 4, 5}
当然&#xff0c;事实上还会有一个匿名数组被创建出来&#xff0c;只是不需要我们来操心而已
以下这两种方式可创建相同的slice&#xff1a;
s1 :&#61; make([]int, 5, 10)s2 :&#61; new([10]int)[:5]fmt.Printf("s1 type:%T, s2 type:%T\n", s1, s2) // s1 type:[]int, s2 type:[]intfmt.Printf("s1 len:%d,cap:%d, s2 len:%d,cap:%d\n", len(s1), cap(s1), len(s2), cap(s2))// s1 len:5,cap:10, s2 len:5,cap:10
方法三&#xff1a;基于切片创建切片
oldSlice :&#61; []int{1, 2, 3, 4, 5}newSlice :&#61; oldSlice[:3] // 基于oldSlice的前3个元素构建新数组切片fmt.Println(newSlice)
有意思的是&#xff0c;选择的oldSlicef元素范围甚至可以超过所包含的元素个数&#xff0c;比如newSlice可以基于oldSlice的前6个元素创建&#xff0c;虽然oldSlice只包含5个元素。只要这个选择的范围不超过oldSlice存储能力&#xff08;即cap()返回的值&#xff09;&#xff0c;那么这个创建程序就是合法的。newSlice中超出oldSlice元素的部分都会填上0。
然而在这里 oldSlice 的容量就是5&#xff0c;而 newSlice 的容量也是5&#xff0c;因为这俩用得是同一个数组。
这个和重新分片是一样的。
因为字符串是纯粹不可变的字节数组&#xff0c;它们也可以被切分成 slice
s :&#61; "hello,世界"s2 :&#61; s[6:9]fmt.Println(s2) // 世
【切片的第3个参数】
slice :&#61; [...]int{0, 1, 2, 3, 4, 5, 6}fmt.Println(slice)s :&#61; slice[1:2:4]fmt.Println(len(s), cap(s)) // 1 3s1 :&#61; slice[1:2]fmt.Println(len(s1), cap(s1)) // 1 6
第3个参数表示容量最大界索引&#xff0c;第三个参数减去第一个参数的差值就是容量。
【查看长度和容量】
slice :&#61; []int{1, 2, 3, 4, 5}fmt.Println(len(slice), cap(slice)) // 5 5slice2 :&#61; make([]int, 5, 10)fmt.Println(len(slice2), cap(slice2)) // 5 10
一个 slice s 可以这样扩展到它的大小上限&#xff1a;s &#61; s[:cap(s)]
s :&#61; make([]int, 5, 10)s &#61; s[:cap(s)]fmt.Println(len(s), cap(s)) // 10,10
【重新分片】
arr :&#61; [10]int{1, 2, 3, 4, 5, 6, 7, 8, 9, 0}s :&#61; arr[:5]fmt.Println(s) // [1 2 3 4 5]s &#61; arr[5:10]fmt.Println(s) // [6 7 8 9 0]
【新增元素】
slice :&#61; []int{1, 2, 3, 4, 5}slice2 :&#61; append(slice, 6, 7, 8)fmt.Println(slice) // [1 2 3 4 5]fmt.Println(slice2) // [1 2 3 4 5 6 7 8]
append()是产生了一个新的切片
append()的第二个参数其实是一个不定参数&#xff0c;我们可以按自己需求添加若干个元素&#xff0c;甚至直接将一个数组切片追加到另一个数组切片的末尾&#xff1a;
slice :&#61; []int{1, 2, 3, 4, 5}slice2 :&#61; []int{8, 9, 10}slice &#61; append(slice, slice2...)fmt.Println(slice)
第二个参数slice2后面加了三个点&#xff0c;即一个省略号&#xff0c;如果没有这个省略号的话&#xff0c;会有编译错误&#xff0c;因为按append()的语义&#xff0c;从第二个参数起的所有参数都是待附加的元素。因为slice中的元素类型为int&#xff0c;所以直接传递slice2是行不通的。加上省略号相当于把slice2包含的所有元素打散后传入。 上述调用等同于&#xff1a;
slice &#61; append(slice, 8, 9, 10)
数组切片会自动处理存储空间不足的问题。如果追加的内容长度超过当前已分配的存储空间&#xff08;即cap()调用返回的信息&#xff09;&#xff0c;数组切片会自动分配一块足够大的内存&#xff0c;然后返回指向新数组的切片。
append函数会改变slice所引用的数组的内容&#xff0c;从而影响到引用同一数组的其它slice。 但当slice中没有剩余空间&#xff08;即(cap-len) &#61;&#61; 0&#xff09;时&#xff0c;此时将动态分配新的数组空间。返回的slice数组指针将指向这个空间&#xff0c;而原数组的内容将保持不变&#xff1b;其它引用此数组的slice则不受影响
append interface{}时的坑
var slice []interface{} &#61; make([]interface{}, 0)slice &#61; append(slice, "hello")slice &#61; append(slice, 12)var arr []interface{} &#61; []interface{}{"one", "two"}slice &#61; append(slice, arr...)var arr2 []string &#61; []string{"three", "four"}slice &#61; append(slice, arr2...) // cannot use arr2 (type []string) as type []interface {} in appendfmt.Println(slice)
这里在append arr2时是想让go做一个隐式转换&#xff0c;把[]string转化成[]interface{}&#xff0c;但显然go现在还不支持。
数组是nil时依然可以append
var arr []string &#61; nilarr &#61; append(arr, "hello")
并不会报空指针异常&#xff0c;可能还是因为类型和值都为nil时才为nil&#xff0c;很明显&#xff0c;这里的类型不为nil。
【内容复制】
数组切片支持Go语言的另一个内置函数copy()&#xff0c;用于将内容从一个数组切片复制到另一个数组切片。如果加入的两个数组切片不一样大&#xff0c;就会按其中较小的那个数组切片的元素个数进行复制
slice1 :&#61; []int{1, 2, 3, 4, 5}slice2 :&#61; []int{5, 4, 3}copy(slice2, slice1) // 只会复制slice1的前3个元素到slice2中fmt.Println(slice2) // [1 2 3]slice2[0], slice2[1], slice2[2] &#61; 7, 8, 9copy(slice1, slice2) // 只会复制slice2的3个元素到slice1的前3个位置fmt.Println(slice1) // [7 8 9 4 5]
【删除】
func (m *MusicManager) Remove(index int) *MusicEntry {if index <0 || index >&#61; len(m.musics) {return nil}removedMusic :&#61; m.musics[index] // 这里不能加&&#xff0c;否则删除的时候会被后面的覆盖&#xff0c;所以需要把元素复制出来而不是只取地址// 从切片中删除len :&#61; len(m.musics)if len &#61;&#61; 0 || len &#61;&#61; 1 { // 删除仅有的一个m.musics &#61; m.musics[0:0]} else if index &#61;&#61; 0 { // 之后的长度至少为2// 删除开头的m.musics &#61; m.musics[1:]} else if index &#61;&#61; len { //最后一个m.musics &#61; m.musics[:len-1]} else { // 中间的&#xff0c;长度至少为3m.musics &#61; append(m.musics[:index], m.musics[index&#43;1:]...)}return &removedMusic
}
[start : end]操作并没有改变底层的数组&#xff0c;仅仅是改变了开始索引和长度&#xff0c;append操作会覆盖掉中间的元素&#xff0c;但底层数组还是没有改变&#xff0c;只是改变了索引位置和长度。
一般性的代码&#xff1a;
func DeleteString(slice []string, index int) []string {len :&#61; len(slice)if index <0 || index >&#61; len {return slice}if len &#61;&#61; 0 {return slice}if len &#61;&#61; 1 {return slice[0:0]}if index &#61;&#61; 0 {return slice[1:]}if index &#61;&#61; len-1 {return slice[:len-1]}return append(slice[:index], slice[index&#43;1:]...)
}
上面代码有些啰嗦了&#xff0c;下面是简洁版的&#xff1a;
func DeleteString2(slice []string, index int) []string {if index <0 || index >&#61; len(slice) {return slice}return append(slice[:index], slice[index&#43;1:]...)
}
二维切片
Go的数组和切片都是一维的。要创建等价的二维数组或者切片&#xff0c;需要定义一个数组的数组或者切片的切片&#xff0c;类似这样&#xff1a;
type Transform [3][3]float64 // A 3x3 array, really an array of arrays.
type LinesOfText [][]byte // A slice of byte slices.
因为切片是可变长度的&#xff0c;所以可以将每个内部的切片具有不同的长度。这种情况很常见&#xff0c;正如我们的LinesOfText例子中&#xff1a;每一行都有一个独立的长度。
text :&#61; LinesOfText{[]byte("Now is the time"),[]byte("for all good gophers"),[]byte("to bring some fun to the party."),
}
有时候是需要分配一个二维切片的&#xff0c;例如这种情况可见于当扫描像素行的时候。有两种方式可以实现。一种是独立的分配每一个切片&#xff1b;另一种是分配单个数组&#xff0c;为其 指定单独的切片们。使用哪一种方式取决于你的应用。如果切片们可能会增大或者缩小&#xff0c;则它们应该被单独的分配以避免覆写了下一行&#xff1b;如果不会&#xff0c;则构建单个分配 会更加有效。作为参考&#xff0c;这里有两种方式的框架。首先是一次一行&#xff1a;
// Allocate the top-level slice.
picture :&#61; make([][]uint8, YSize) // One row per unit of y.
// Loop over the rows, allocating the slice for each row.
for i :&#61; range picture {picture[i] &#61; make([]uint8, XSize)
}
然后是分配一次&#xff0c;被切片成多行&#xff1a;
// Allocate the top-level slice, the same as before.
picture :&#61; make([][]uint8, YSize) // One row per unit of y.
// Allocate one large slice to hold all the pixels.
pixels :&#61; make([]uint8, XSize*YSize) // Has type []uint8 even though picture is [][]uint8.
// Loop over the rows, slicing each row from the front of the remaining pixels slice.
for i :&#61; range picture {picture[i], pixels &#61; pixels[:XSize], pixels[XSize:]
}
map
key可以为任何定义了等于操作符的类型&#xff0c;例如整数&#xff0c;浮点和复数&#xff0c;字符串&#xff0c;指针&#xff0c;接口&#xff08;只要其动态类型支持等于操作&#xff09;&#xff0c;结构体和数组。切片不能 作为map的key&#xff0c;因为它们没有定义等于操作。和切片类似&#xff0c;map持有对底层数据结构的引用。如果将map传递给函数&#xff0c;其对map的内容做了改变&#xff0c;则这 些改变对于调用者是可见的。
key可以是任意数据类型&#xff0c;只要该类型能够用&#61;&#61;来进行比较
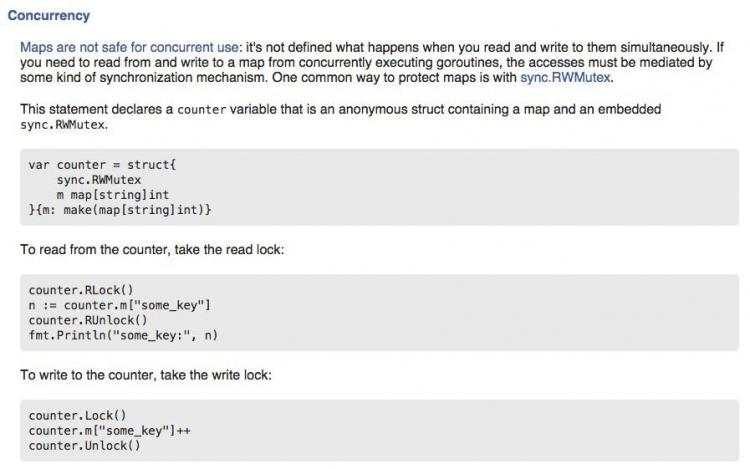
map和其他基本型别不同&#xff0c;它不是thread-safe&#xff0c;在多个go-routine存取时&#xff0c;必须使用mutex lock机制
【变量声明】
var person map[string] string
[]内是键的类型&#xff0c;后面是值类型
【创建】
person &#61; make(map[string]string)
声明加&#43;创建&#xff1a;
var person map[string]string &#61; make(map[string]string)person :&#61; make(map[string]string)
指定该map的初始存储能力&#xff1a;
person &#61; make(map[string]string, 100)
创建并初始化map&#xff1a;
var person map[string]stringperson &#61; map[string]string{"a": "haha","b": "ni", // 最后的逗号是必须的}
【元素赋值/添加元素】
var person map[string]string &#61; make(map[string]string)person["1"] &#61; "abc"
m :&#61; make(map[string]int)
m["a"]&#43;&#43;
不用担心map在没有当前的key时就对其进行&#43;&#43;操作会有什么问题&#xff0c;因为go语言在碰到这种情况时&#xff0c;会自动将其初始化为0&#xff0c;然后再进行操作。
【元素删除】
delete(person, "1")
如果传入的map是nil&#xff0c;则报错&#xff0c;如果键不存在&#xff0c;则什么都不发生
【元素查找】
value, ok :&#61; person["2"]if ok {fmt.Println(value)} else {fmt.Println("does not find!")}
或者&#xff1a;
if value, ok :&#61; person["2"]; ok {fmt.Println(value)
} else {fmt.Println("does not find!")
}
即便是nil也是可以查找的&#xff1a;
var m map[string]int &#61; nilif v, ok :&#61; m["a"]; ok {fmt.Println(v)} else {fmt.Println("!ok")}// 输出!ok
map中的元素不会出现nil的现象&#xff08;很神奇&#xff09;&#xff1a;
func main() {m :&#61; make(map[string]entry)fmt.Println(m["a"].name &#61;&#61; "") // true
}type entry struct {name string
}
m[“a”]返回的并不是nil&#xff0c;而是{}&#xff0c;如果map的元素是指针&#xff0c;则是nil
m :&#61; make(map[string]*entry)fmt.Println(m["a"] &#61;&#61; nil) // true
【遍历】
for k, v :&#61; range person {fmt.Println("key&#61;", k, "value&#61;", v)}
map也是一种引用类型&#xff0c;如果两个map同时指向一个底层&#xff0c;那么一个改变&#xff0c;另一个也相应的改变&#xff1a;
m :&#61; make(map[string]string)
m["Hello"] &#61; "Bonjour"
m1 :&#61; m
m1["Hello"] &#61; "Salut" // 现在m["hello"]的值已经是Salut了
【清空map】
for k, _ :&#61; range m {delete(m, k)}
或者重新赋值&#xff1a;
m &#61; make(map[string]string)
【线程安全的map】
【map中的对象是个拷贝问题】
直接对map对象使用[]操作符获得的对象不能直接修改状态&#xff1a;
type Person struct {age int}m :&#61; map[string]Person{"c": {10}}m["c"].age &#61; 100 // 编译错误&#xff1a;cannot assign to m["c"].age
通过查询map获得的对象是个拷贝&#xff0c;对此对象的修改不影响原有对象的状态&#xff1a;
type Person struct {age int}m :&#61; map[string]Person{"c": {10}}p :&#61; m["c"]p.age &#61; 20fmt.Println(p.age) // 20fmt.Println(m["c"].age) // 10
解决方法
- map中存储指针而不是结构体
type Person struct {age int}m :&#61; map[string]*Person{"c": {10}}p :&#61; m["c"]p.age &#61; 20fmt.Println(p.age) // 20fmt.Println(m["c"].age) // 20
- 修改了对象状态以后重新加到map里
type Person struct {age int}m :&#61; map[string]Person{"c": {10}}p :&#61; m["c"]p.age &#61; 20fmt.Println(p.age) // 20m["c"] &#61; pfmt.Println(m["c"].age) // 20
【分拆map】
分拆map&#xff0c;提高并发能力

Go数据底层的存储
下面这张图来源于Russ Cox Blog中一篇介绍Go数据结构的文章&#xff0c;大家可以看到这些基础类型底层都是分配了一块内存&#xff0c;然后存储了相应的值。
指针
- 在 32 位机器上占用 4 个字节&#xff0c;在 64 位机器上占用 8 个字节&#xff0c;并且与它所指向的值的大小无关。
- 整形的指针
var p *int &#61; new(int)*p &#61; 5fmt.Println(*p, p) // 5 0xc0820001d0q :&#61; 6var pq *int &#61; &qfmt.Println(*pq, pq) // 6 0xc082000200
- 不能得到文字或常量的地址
const i &#61; 5
ptr :&#61; &i //error: cannot take the address of i
ptr2 :&#61; &10 //error: cannot take the address of 10
- 对一个空指针的反向引用是不合法的&#xff0c;并且会使程序崩溃&#xff1a;
package main
func main() {var p *int &#61; nil*p &#61; 0
}
// in Windows: stops only with:
// runtime error: invalid memory address or nil pointer dereference
- 可以在 unsafe.Pointer 和任意类型指针间进行转换
x :&#61; 0x12345678p :&#61; unsafe.Pointer(&x) // *int -> Pointern :&#61; (*[4]byte)(p) // Pointer -> *[4]byte, 3,5也可以for i :&#61; 0; i
输出&#xff1a;
78 56 34 12
- 返回局部变量指针是安全的&#xff0c;编译器会根据需要将其分配在 GC Heap 上
func test() *int {x :&#61; 100return &x // 在堆上分配x内存&#xff0c;但在内联时&#xff0c;也可以直接分配在目标栈}
- 将 Pointer 转换成 uintptr, 可变相实现指针运算
d :&#61; struct {s stringx int}{"abc", 100}p :&#61; uintptr(unsafe.Pointer(&d)) // *struct -> Pointer -> uintptrp &#43;&#61; unsafe.Offsetof(d.x) // uintptr &#43; offsetp2 :&#61; unsafe.Pointer(p) // uintptr -> Pointerpx :&#61; (*int)(p2) // Pointer -> *int*px &#61; 200 // d.x &#61; 200fmt.Printf("%#v\n", d)
输出&#xff1a;
struct { s string; x int }{s:"abc", x:200}
注意&#xff1a;GC 把 uintptr 当成普通整数对象&#xff0c;它无法阻止"关联"对象被回收。










 京公网安备 11010802041100号
京公网安备 11010802041100号