作者:海蓝透了我的心 | 来源:互联网 | 2023-09-02 12:08
LuaJIT有两种执行模式,解释模式和即时编译(JIT)模式。这里暂且抛开JIT模式,主要介绍解释器模式的技术实现。解释器模式的主要模块关系如下图所示:
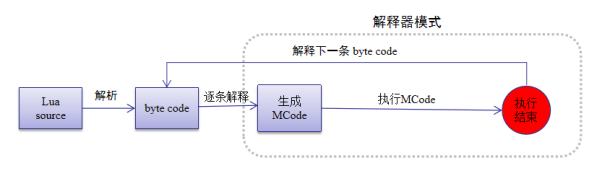
解释器模式基本上可以分为两个阶段:第一个阶段词法分析器提取分析Lua source字符流构成token(这一过程在src/lj_lex.c中),语法分析器再使用token流进行语法分析、语义分析,最后生成可供LuaJIT虚拟机识别的Bytecode中间码(src/lj_parse.c)。第二个阶段解释器对Bytecode一条条的按字节码逻辑进行解析执行(src/vm_loongarch64.dasc)。根据对源码的梳理,做出以下时序图:
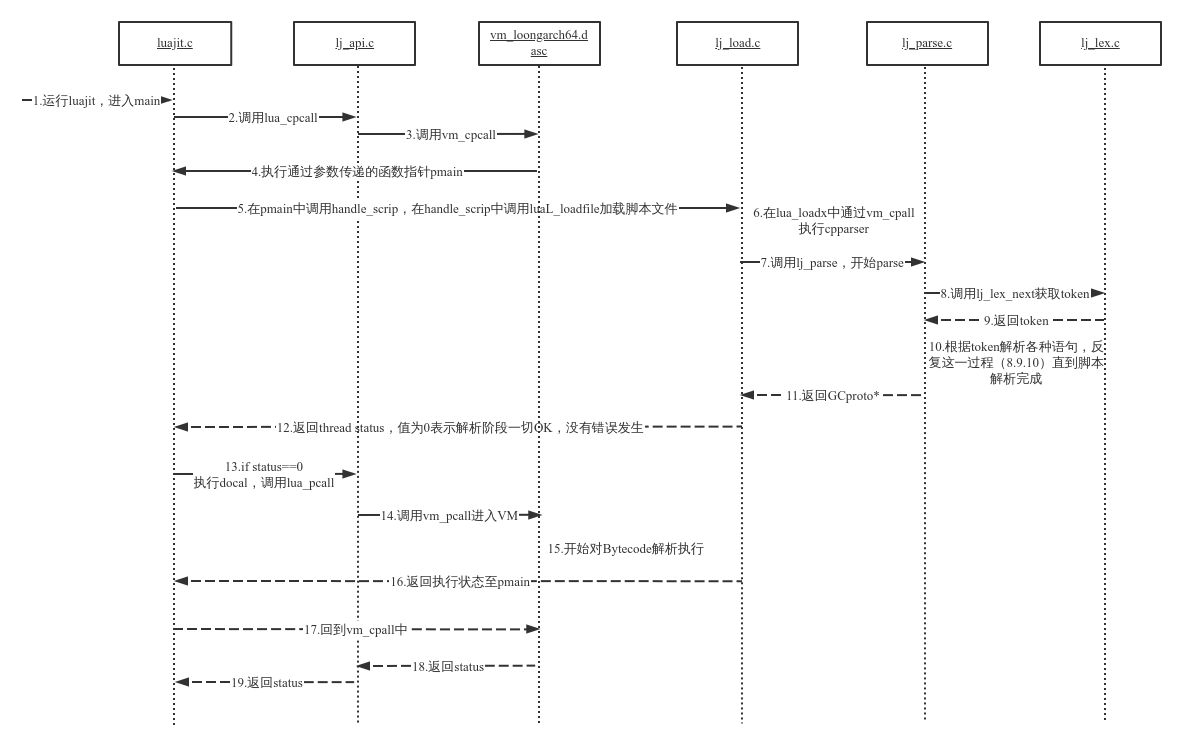
LuaJIT开始于main函数,在main中调用lua_open()创建虚拟机(VM),然后在lua_cpcall中调用lj_vm_cpcall(L, func, ud, cpcall)函数进入VM,该函数对应这汇编代码中的vm_cpcall。参数func是函数pmain的指针,加载source文件至VM解释执行就是其发起的,参数cpcall是函数cacall的指针,cpcall函数主要为执行pmain做了一个准备工作。
在pmain中,首先检查执行命令中的参数,根据参数做相应动作,如./luajit -v,会输出luajit的版本信息。luaL_openlibs(L)会打开所有的Lua标准库,调用handle_script发起加载source文件解释执行。
在lua_loadx中,再次通过lj_vm_cpcall执行函数cpparser,cpparser则是真正的开始为source code -> bytecode这一过程做准备。这里有三个类型需注意:
LexState是词法解析的上下文,通过该类型的对象可以获取所有词法相关的信息,包括Current token及其位置、token value、Current character等;GCproto是函数的原型,存放函数paser完生成的bytecode和中间结构的信息,包括常量数组、bytecode指令等;GCfunc是union,封装了Lua函数和C函数,也就是一个该类型的对象只能表示为一个Lua函数或一个C函数。
区分GCproto(原型)和GCfunc(函数)的区别,GCproto中存放的是函数生成的bytecode指令集及其相关的中间结构信息,会以此去创建闭包,将创建的闭包信息存放到GCfunc中,从而让VM执行Lua或C函数。bc ? lj_bcread(ls) : lj_parse(ls)根据bc的值选择是parse Lua source还是直接执行bytecode,bc的值根据脚本文件中的前几个字符确定。
lj_parse进入parse阶段,在parse时会创建FuncState对象。FuncState是当前正在parse的函数上下文信息,如*prev指向父函数或者外部函数,nactvar表示当前局部变量在stack上的位置,freereg表示第一个可用的stack slot,vbase是当前函数stack的base等。首先bcemit_AD(&fs, BC_FUNCV, 0, 0)生成一条BC_FUNCV指令,这条指令并不是最终的指令,如果是JIT模式,后面会被BC_IFUNCV执行替换。从这里已经可以看出来,从source->bytecode这一过程是直译的,没有生成AST或其他中间码。
parse_chunk被用于block级别的parse,这个block可以是函数或者复合语句(if、for等)的block,如:
function fname() block
endif cond then block
end
从parse_chunk中循环调用parse_stmt做语句级别的parse,直到遇到return语句或者标志某条复合语句block结束的token后(如else、elseif和end标志着if then后面的block结束)结束。
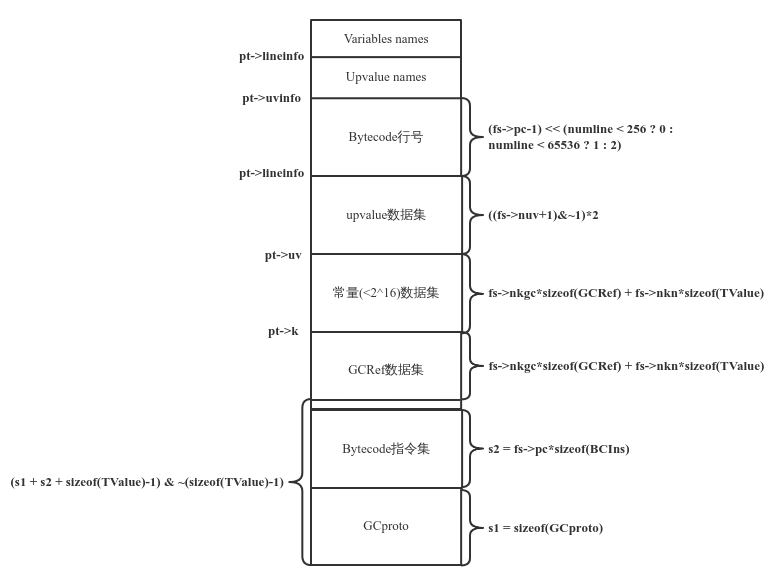
parse完成后,会执行fs_finish函数,将parse阶段生成的Bytecode和中间结构,以及收集到的函数context信息重新组织为一个新的数组结构,放到紧跟在GCproto之后的位置,并将这些数组结构的基地址和size存放到GCproto或lua_State对象中,供VM解释器做解释计算时使用。下图为重新组织的数组结构图,其中pt为GCproto,fs为FuncState:
至此parse过程已经完成,如果source没有错误,会返回GCproto*。执行函数lj_func_newL_empty(L, pt, tabref(L->env))创建一个GCfunc,并将其存放到Stack的第一个free slot上(L->top所指位置),供VM解释器执行使用。待cpparser函数执行完,PC(程序计数器,别跟VM的PC混淆)返回到VM的函数vm_cpcall的or BASE, CRET1, r0指令,此时寄存器CRET1的值为0,vm_cpcall会返回到进入它的C函数lua_loadx,再lua_loadx由一直返回到handle_script函数中。返回值status为0(LUA_OK = 0),所以会按照执行路径docall(L, narg, 0)、lua_pcall(L, narg, (clear ? 0 : LUA_MULTRET), base)、lj_vm_pcall(L, api_call_base(L, nargs), nresults+1, ef)进入VM开始对生成的Bytecode解释执行。
首先执行vm_pcall,其中参数 TValue *base 指针指向VM Stack的base地址,L->top指向VM Stack的第一个free slot,所以即将要执行的函数的参数个数可通过L->top - base获得。该函数的主要作用是将进入VM之前的C函数的保存寄存器(callee寄存器)的值保存在运行时栈上,等VM执行结束返回时再取出恢复C的运行环境。
接着执行vm_call,这部分主要准备VM函数的运行环境,如为寄存器BASE、PC、DISPATCH赋相应的值,当前要运行的Lua函数的闭包存放在FRAME_FUNC(BASE)中,这里将其存放在了寄存器RB中,在ins_call中会使用,跳到要执行的函数Bytecode相关指令对应的函数中执行。具体如何执行,会在根据源码梳理LuaJIT解释器模式(二) 中详细介绍。
待Bytecodeui对应的函数执行完之后,会Return handling相关的函数回到C函数中,最终回到main中。返回到C函数中后,VM Stack的结构如下:
| ret1 | ... | retn | |
base n-1 L->top




![基于Linux开源VOIP系统LinPhone[四]](https://img.php1.cn/3cd4a/1eebe/cd5/ed19db63ee478b98.png)


 京公网安备 11010802041100号
京公网安备 11010802041100号