 |导|读|
|导|读|
BY:AI-Beetle
完全图解人工智能、NLP、机器学习、深度学习、大数据!这份备忘单涵盖了上述领域几乎全部的知识点,并使用信息图、脑图等多种可视化方式呈现,设计精美,实用性强。
今天,我们要为大家推荐一个超实用、颜值超高的神经网络+机器学习+数据科学和Python的完全图解,文末附有高清PDF版链接,支持下载、打印,推荐大家可以做成鼠标垫、桌布,或者印成手册等随手携带,随时翻看。
这是一份非常详实的备忘单,涉及具体内容包括:
1.2神经网络
3.神经网络基础知识
4.神经网络图谱
5.机器学习
6.机器学习基础知识
7.著名Python库Scikit-Learn
8.Scikit-Learn算法
9.机器学习算法选择指南
10.数据科学
11.TensorFlow
12.Python基础
13.PySpark基础
14.Numpy基础
15.Bokeh
16.Keras
17.Pandas
18.使用Pandas进行Data Wrangling
19.使用dplyr和tidyr进行Data Wrangling
20.SciPi
21.MatPlotLib
22.使用ggplot进行数据可视化
23.Big-O

神经网络Cheat Sheet

神经网络基础知识
人工神经网络(ANN),俗称神经网络,是一种基于生物神经网络结构和功能的计算模型。 它就像一个人工神经系统,用于接收,处理和传输计算机科学方面的信息。
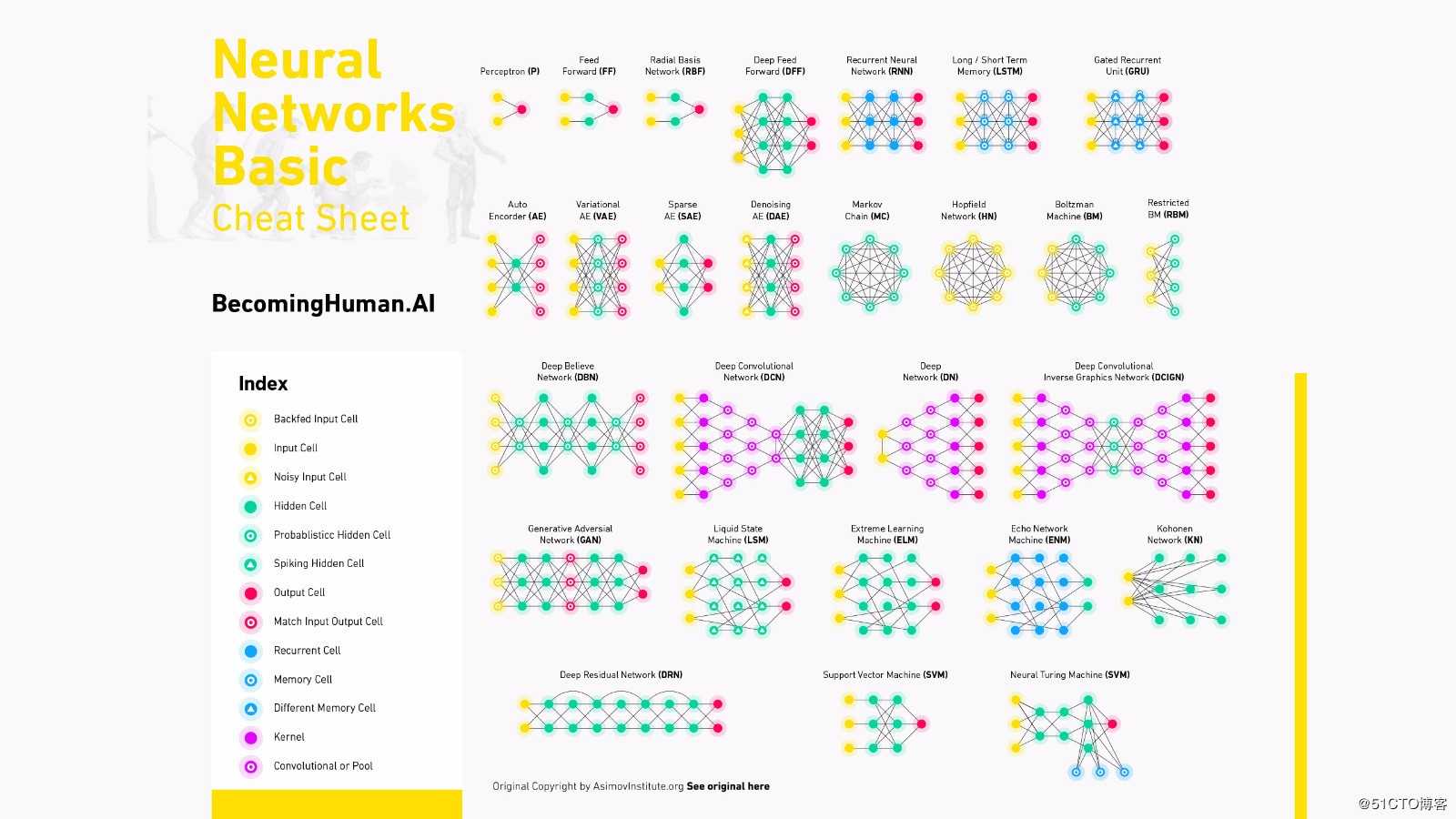
基本上,神经网络中有3个不同的层:
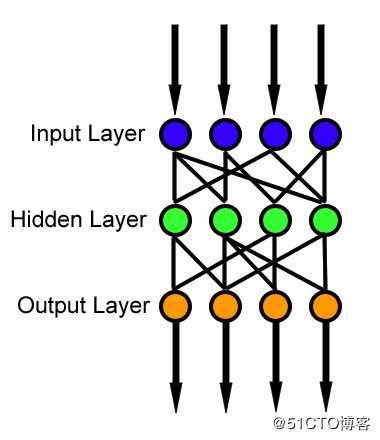
输入层(所有输入都通过该层输入模型)
隐藏层(可以有多个隐藏层用于处理从输入层接收的输入)
输出层(处理后的数据在输出层可用)
神经网络图谱

图形数据可以与很多学习任务一起使用,在元素之间包含很多丰富的关联数据。例如,物理系统建模、预测蛋白质界面,以及疾病分类,都需要模型从图形输入中学习。图形推理模型还可用于学习非结构性数据,如文本和图像,以及对提取结构的推理。
机器学习Cheat Sheet

用Emoji解释机器学习

Scikit-Learn基础
Scikit-learn是由Python第三方提供的非常强大的机器学习库,它包含了从数据预处理到训练模型的各个方面,回归和聚类算法,包括支持向量机,是一种简单有效的数据挖掘和数据分析工具。在实战使用scikit-learn中可以极大的节省代码时间和代码量。它基于NumPy,SciPy和matplotlib之上,采用BSD许可证。

Scikit-Learn算法
这张流程图非常清晰直观的给出了Scikit-Learn算法的使用指南。
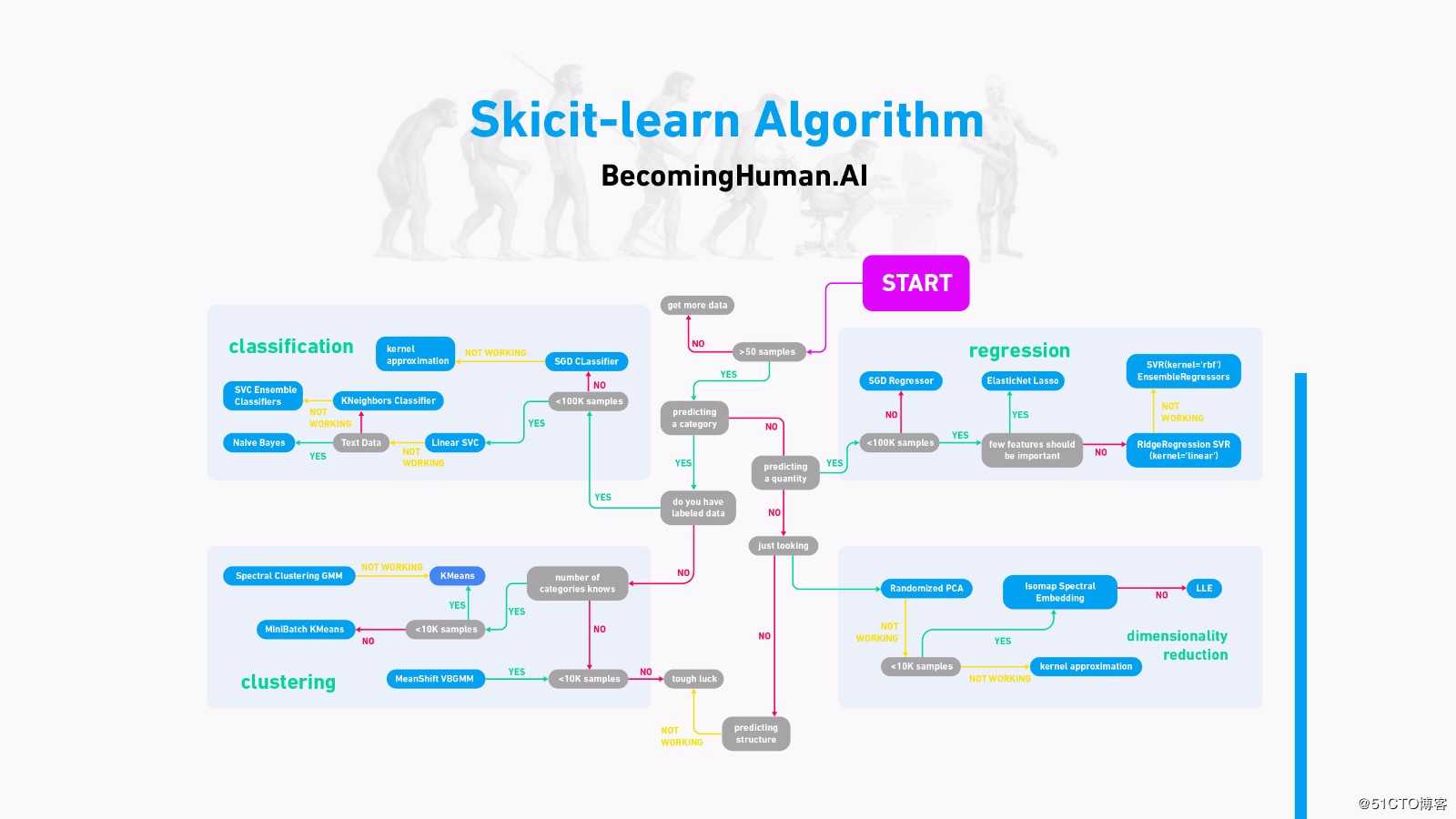
针对Azure Machine Learning Studios的Scikit-Learn算法
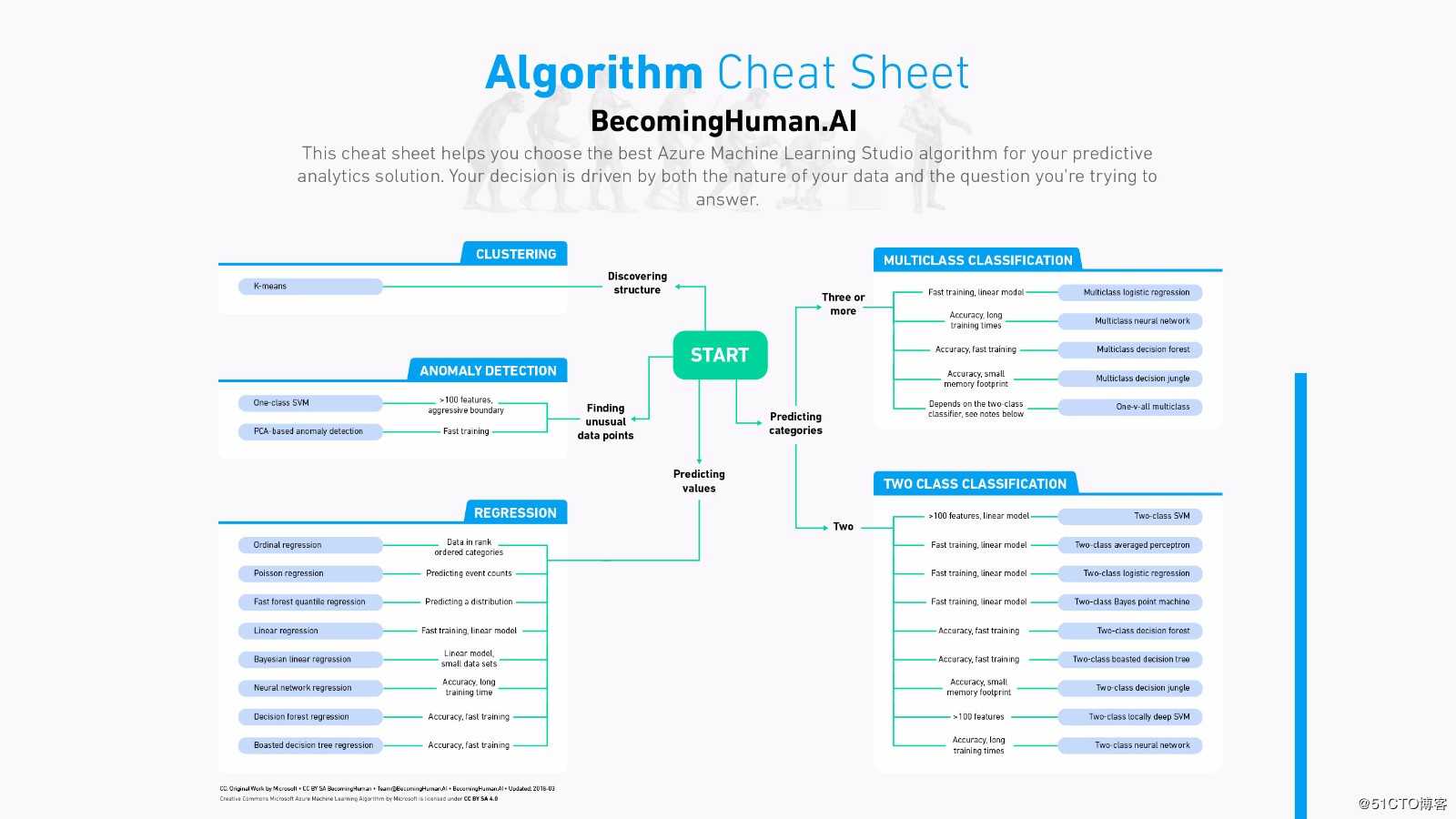
被Python武装起来的数据科学Cheat Sheet

TensorFlow

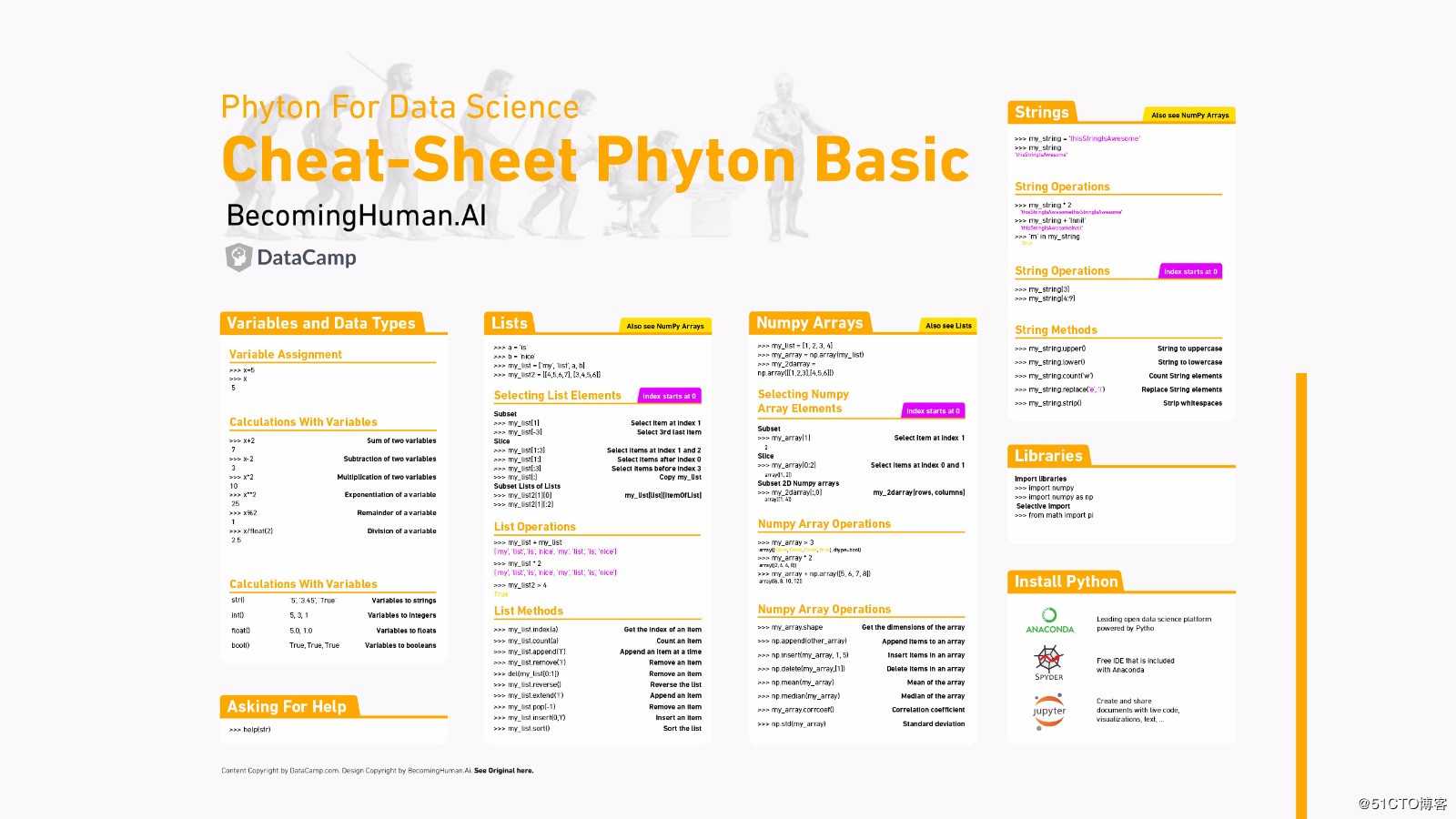
Python基础
温馨提示,本图配合《100天从Python萌新到王者》食用,效果更佳。
PySpark RDD基础
Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎,通过Scala语言实现,拥有Hadoop MapReduce所具有的优点,不同的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。PySpark是Spark 为 Python开发者提供的 API。

NumPy基础
NumPy是Python语言的一个扩展程序库。支持高端大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库,前身Numeric,主要用于数组计算。它实现了在Python中使用向量和数学矩阵、以及许多用C语言实现的底层函数,并且速度得到了极大提升。

Bokeh
Bokeh是一个交互式可视化库,面向现代Web浏览器。目标是提供优雅、简洁的多功能图形构造,并通过非常大或流数据集的高性能交互来扩展此功能。Bokeh可以实现快速轻松地创建交互式图表、仪表板和数据应用程序。

Keras
Keras 是一个用 Python 编写的高级神经网络 API,它能够以 TensorFlow, CNTK, 或者 Theano 作为后端运行。Keras 的开发重点是支持快速的实验。能够以最小的时延把你的想法转换为实验结果,是做好研究的关键。

Pandas
pandas是一个为Python编程语言编写的软件库,用于数据操作和分析,基于NumPy,纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。Pandas提供了大量快速便捷地处理数据的函数和方法。

使用Pandas进行Data Wrangling
Data Wrangling通常被翻译成数据整理,这个词最开始火起来是因为2017年的电影《金刚·骷髅岛》,演员马克·埃文·杰克逊扮演的角色之一被介绍为“我们的Data Wrangler史蒂夫伍德沃德”。

使用ddyr和tidyr进行Data Wrangling
为什么使用tidyr和dplyr呢?因为虽然R中存在许多基本数据处理功能,但都有点复杂并且缺乏一致的编码,导致可读性很差的嵌套功能以及臃肿的代码。使用ddyr和tidyr可以获得:
更高效的代码
更容易记住的语法
更好的语法可读性
Scipy线性代数
SciPy是一个开源的Python算法库和数学工具包。 SciPy包含的模块有最优化、线性代数、积分、插值、特殊函数、快速傅里叶变换、信号处理和图像处理、常微分方程求解和其他科学与工程中常用的计算。 与其功能相类似的软件还有MATLAB、GNU Octave和Scilab。

Matplotlib
Matplotlib是Python编程语言及其数值数学扩展包NumPy的可视化操作界面。 它为利用通用的图形用户界面工具包,如Tkinter, wxPython, Qt或GTK+向应用程序嵌入式绘图提供了应用程序接口(API)。

使用ggplot2进行数据可视化

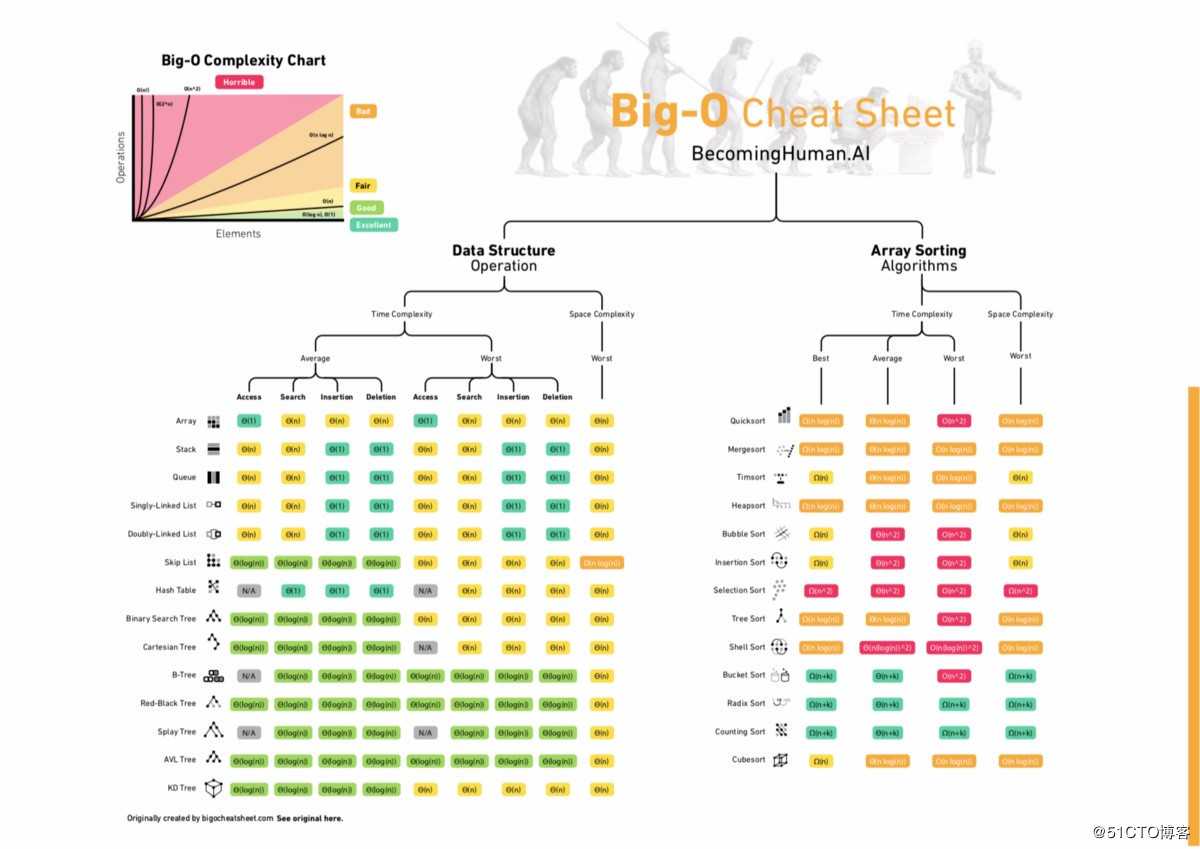
Big-O
大O符号(英语:Big O notation),又稱為漸進符號,是用于描述函数渐近行为的数学符号。 更确切地说,它是用另一个(通常更简单的)函数来描述一个函数数量级的渐近上界。 ... 阶)的大O,最初是一个大写希腊字母“Ο”(omicron),现今用的是大写拉丁字母“O”。
想要获取更多人工智能方面的资料
可以加V、、信:hcgx0904(备注“人工智能”)
点击《深度学习&计算机视觉精讲》,开始学起来吧!
高清图解:神经网络、机器学习、数据科学一网打尽





 京公网安备 11010802041100号
京公网安备 11010802041100号