作者:许更剑_725 | 来源:互联网 | 2023-08-16 17:41
为什么要聊负载均衡系统,因为服务都做了无状态化目的不就是为了扩容缩容吗?没有负载均衡系统怎么做扩容缩容?
负载均衡系统分类
负载均衡系统可以分为两大类:
硬件负载
软件负载
硬件负载设备常见的有F5、Array,硬件负载设备的优点在于能够直接通过智能交换机实现,处理能力更强,而且与系统无关,负载性能强更适用于一大堆设备、大访问量、应用简单。但是硬件负载均衡设备成本都比较高,反正到目前为止我没有见过F5。
软件负载均衡常见的有LVS、Nginx、HAProxy,LVS是四层负载,Nginx是七层负载,而HAProxy则同时支持四层或者七层负载。四层负载和七层负载的概念大家可以自行去了解下网络的OSI7层模型,大致上就是四层负载是根据ip和端口号信息进行转发,七层负载就是在四层负载的基础上(一定要记住七层不可能脱离四层单独存在,这是TCP/IP报文处理的机制决定的)再根据url信息或者其它应用关键信息进行转发。
这里还有个概念要给大家解释清楚,我们都说Nginx是个反向代理软件,那什么是反向代理呢?有反向是不是还有正向呢?有的。那怎么去理解呢?先说正向代理,你就理解为当请求某个服务时,如果请求自己能决定请求到服务集群的某个节点,这就叫正向代理。反之,如果这一系列操作是在服务端或者在某个中间件完成的,对请求来说是透明的,这就叫反向代理。
负载均衡算法
负载均衡的算法有很多,我们拿SpringCloud核心组件Ribbon来说,其内置的算法有:
RoundRobinRule:轮询
RandomRule:随机
AvailabilityFilteringRule: 会先过滤掉由于多次访问故障而处于断路器跳闸状态的服务,以及并发的连接数量超过阈值的服务,然后对剩余的服务列表按照轮询策略进行访问。
WeightedResponseTimeRule: 根据平均响应时间计算所有服务的权重,响应时间越快,服务权重越大,被选中的机率越高。刚启动时,如果统计信息不足,则使用RoundRobinRule策略,等统计信息足够时,会切换到WeightedResponseTimeRule。
RetryRule: 先按照RoundRobinRule的策略获取服务,如果获取服务失败,则在指定时间内会进行重试,获取可用的服务。
BestAvailableRule: 会先过滤掉由于多次访问故障而处于断路器跳闸状态的服务,然后选择一个并发量最小的服务。
ZoneAvoidanceRule: 默认规则,复合判断server所在区域的性能和server的可用性选择服务器。
其实Ribbon的AvailabilityFilteringRule负载均衡算法就支持简单的熔断策略在里面了,只不过熔断是在客户端做的。
那讲到这里咱们负载均衡是不是就讲完了,NO。我们从相对论的角度来分析,以上这些都是狭义上的负载均衡,都不需要我们动脑子,买个设备装个软件学个API就行了。有狭义是不是就有广义?广义上的负载均衡怎么说呢?那就是负载均衡系统嘛,就以上这些是不是顶到天就只算负载均衡设备、软件介绍。
负载均衡系统
什么是负载均衡系统?我们可以这么认为拥有一整套完整的故障处理恢复机制的软硬件结合体就叫负载均衡系统,负载均衡系统应该包括以下特性:
故障自动发现
故障服务自动剔除
故障服务熔断
请求自动重试
服务恢复自动发现
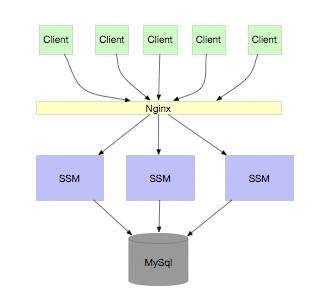
我们还是拿水平分层的架构来分析:

首先我有以下假设:
注册中心使用Zookeeper
网关层有业务逻辑层的服务信息缓存
网关层与业务逻辑层之间保持tcp长连接
网关层有rsp队列
其实Zookeeper不适合做注册中心,因为其是CP模型,而对于服务注册中心来说夸机房出现网络分区的情况下CP模型会导致服务不可用,但是对于服务来说我们要保持高可用,即AP模型,也就是说我宁愿调用一个旧的服务缓存也比直接报错好。Eureka是目前比较合适做服务注册中心的,这个后续再聊,现在我们就假设我们拿Zookeeper做服务注册中心。
故障自动发现
故障自动发现我们要怎么做?即假如我的业务逻辑层1挂了后网关层怎么自动发现。其实很简单,因为我们的业务逻辑层服务起来后都会把name、ip、端口信息注册到Zookeeper,并且会不停的向Zookeeper发送心跳报文,所以我们可以利用Zookeeper的watch机制向网关层更新服务信息。
故障服务自动剔除
服务自动剔除与服务故障自动发现其实同步的,按照故障自动发现的思路来处理就行了。
请求自动重试
请求自动重试也很简单,现在开源的rpc框架(Dubbo、Dubbox、brpc、grpc、RPC Over HTTP)基本上都自带请求超时重试,跟着API来就完事。
服务故障熔断
很多朋友会好奇,为什么我们有了服务自动剔除还需要服务故障熔断。我这里说的服务故障熔断是客户端的服务故障熔断,因为我们业务逻辑层向Zookeeper发送心跳报文肯定不是业务服务线程去做的,对吧?肯定会另外起一个单独的线程去做这个事,那如果服务出现假死,即我们的业务服务线程死循环了或者其他的乱八七糟的故障,但是我们的心跳报文线程是好的,这个时候其实Zookeeper是不会主动向网关层推送故障服务信息的,所以网关层还是会继续请求出现故障的服务,那这个时候怎么办呢?其实很简单,我们可以在网关层维护一个rsp队列,记录1分钟或者5分钟之内(这个时间根据业务实际PV去调整)的请求相应状态,我们可以拿count(失败) + count(超时)/count(失败) + count(超时) + count(正常)算出一个比例,如果超过10%或者20%(这个比例可以根据业务实际PV去调整)那我就在网关层主动剔除服务缓存中对应的服务节点。
服务恢复自动发现
服务怎么自动恢复呢?很简单,重启服务就行了,重启服务后Zookeeper就会重新向网关层推送最新的服务信息。当然如果是物理机直接kill进程再重启,如果是容器我们除了要kill进程还要kill docker和pod。






 京公网安备 11010802041100号
京公网安备 11010802041100号