>(){})); 上述代码使用匿名内部类来获取泛型信息,其中new TypeHint>(){} 就是用来在类型擦除的情况下来获取泛型信息的。
3、Lambda函数的类型提取
Flink 类型提取依赖于继承等机制,但Lambda函数比较特殊,其类型提取是匿名的,也没有与之相关的类,所以其类型信息较难获取。
1)Java类型擦除的原因
a:避免JVM的重构。如果JVM将泛型类型延续到运行期,那么到运行期时JVM就需要进行大量的重构工作。
b:版本兼容。在编译期擦除可以更好地支持原生类型(Raw Type)。
2)Java泛型类型擦除规则
a:如果是继承基类而来的泛型,就用getGenericSuperclass(),转型为ParameterizedType来获得实际类型。
b:如果是实现接口而来的泛型,就用getGenericSuperclass(),针对其中的元素转型为ParameterizedType来获得实际类型。
c:Java泛型在字节码中会被擦除,并不总是擦除为Object类型,而是擦除到上限类型。
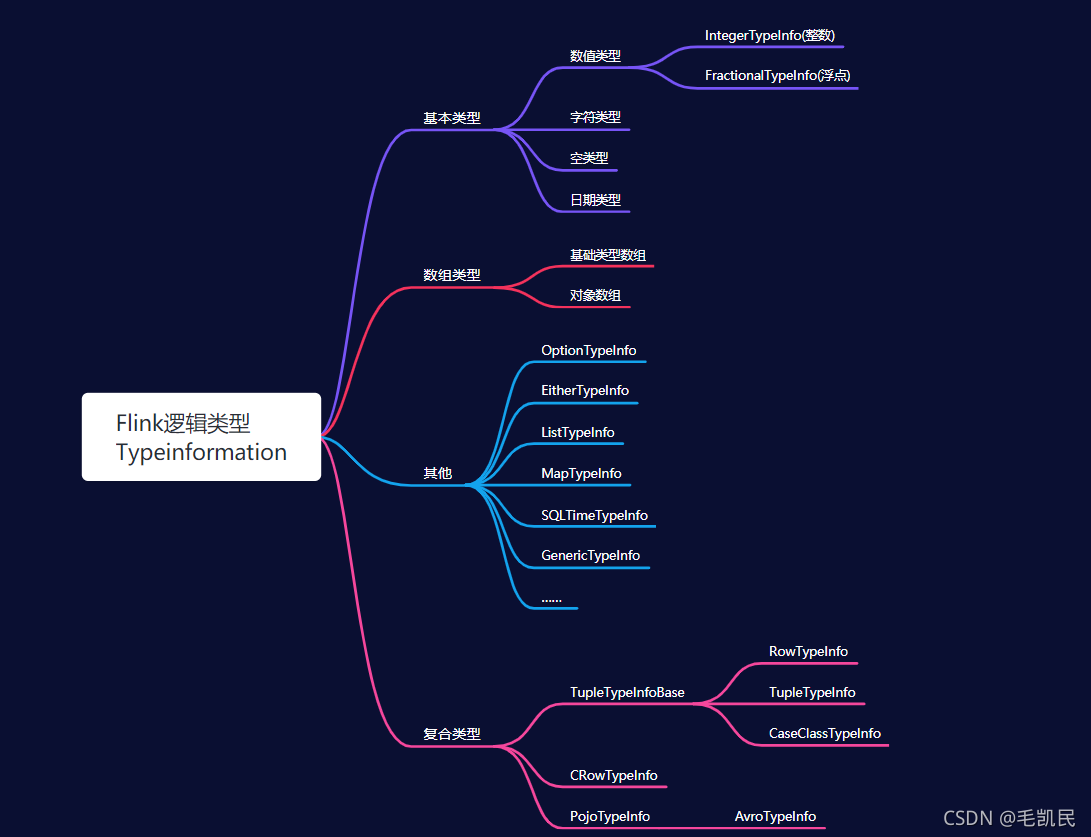
1.4 显示类型
Flink 提供了两层简化的类型使用方式:
BasicTypeInfo这个类定义了基本类型的TypeInformation的快捷声明,如String、Boolean、Byte、Short\Integer、Long、Float、Double、Char等。
Types类(org.apache.flink.api.common.typeinfo.Types)
二、SQL类型系统
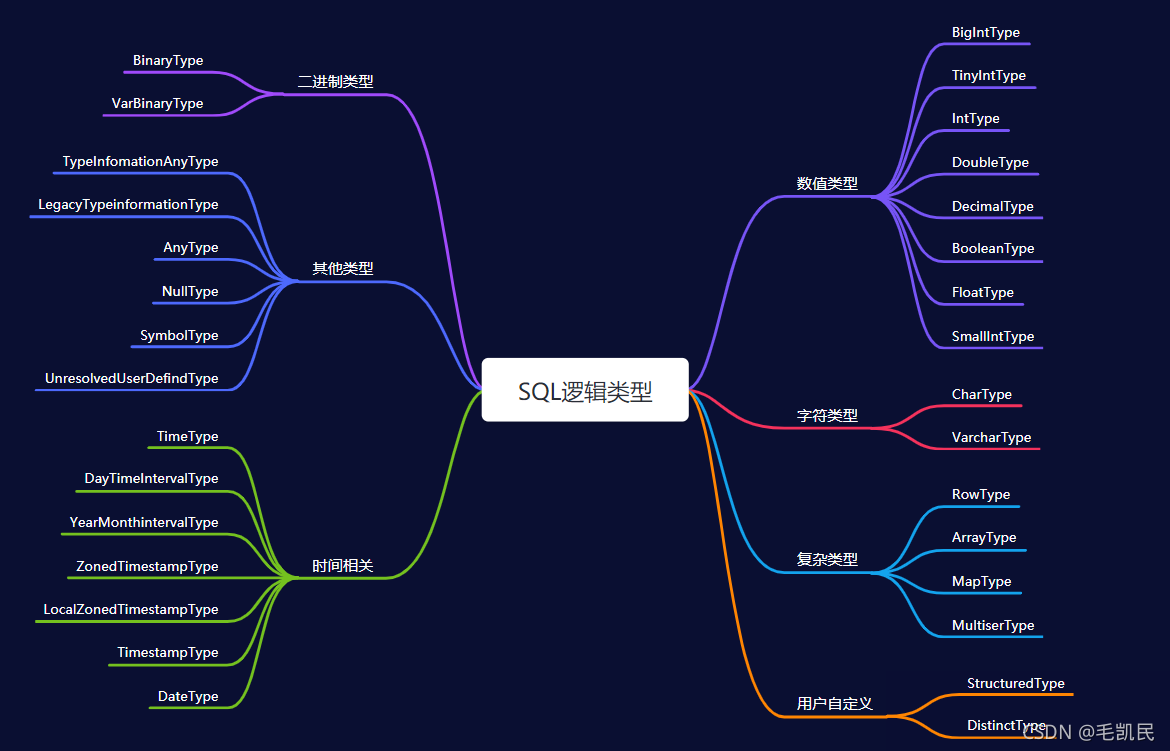
2.1 SQL逻辑类型
在目前版本的Flink存在两套Row结构:
- org.apache.flink.types.Row:在Flink Planner中使用,是1.9版本之前Flink SQL使用的Row结构,在SQL相关的算子、UDF函数、代码生成中都是使用该套Row结构。
- org.apache.flink.table.dataformat.BaseRow及其子类:是在Blink Runtime和Blink Planner中使用的新的Row类型数据结构,在Blink算子、UDF函数和代码生成中使用此结构。
2.2 Blink Row
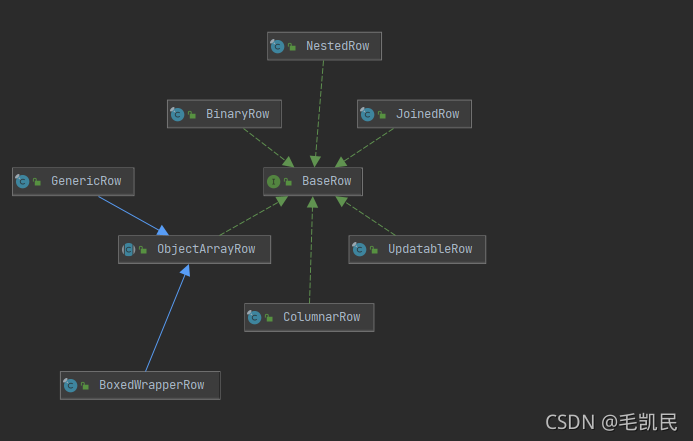
Blink 中的行式存储结构
- BinaryRow:表数据的二进制行式存储,分为定长部分和不定长部分,定长部分只能在一个MemorySegment内。
- NestedRow:与BinaryRow的内存结构一样,区别在于NestedRow的定长部分可以跨MemorySegment。
- UpdatableRow:该类型的Row比较特别,其保存了该行所有字段的数据,更新字段数据的时候不修改原始数据,而是使用一个数组记录被修改字段的最新值。读取数据的时候,首先判断数据是否被更新过,如果更新过则读取最新值,如果没有则读取原始值。
- ObjectArrayRow:使用对象数据保存数据,比二进制结构存储形式多了对象的序列化/反序列化,理论上来说成本更高。其中两个实现类GenericRow和BoxedWrapperRow。GenericRow中存储的数据类型是原始类型(如int等),BoxedWrapperRow中存储的数据类型是可序列化和可比较大小的对象类型。
- JoinedRow:表示Join或者关联运算中的两行数据的逻辑结构,如Row1、Row2,两行数据并没有进行物理上的合并,物理合并成本高。但是从使用者的角度来说,看起来就是一行数据,无须关注底层。
- ColumnarRow:是一种内存列式存储结构,每一列的抽象结构为ColumnVector。在当前的实现中,只支持堆上ColumnVector,对外的ColumnVector尚不被支持。堆上ColumnVector本质上是使用Java原始类型数据保存一列的数据。Orc类型的列式存储使用了ColumnarRow。
为了提升Flink SQL的性能,在1.9版本实现了BinaryRow,BinaryRow直接使用MemorySegment来存储和计算,计算过程中直接对二进制数据结构进行操作,避免了序列化/反序列化的开销。
BinaryRow 存储结构中包含两个部分:定长部分和变长部分。
定长部分包含了3个内容:头信息区(Header)、空值索引(Null Bit Set)、字段值区(Field Values)。
1)头信息区:占用一个字节。
2)空值索引:用于标记行中Null值字段,在内存中使用8字节进行对齐。在实际的存储中,该区域的第一个字节就是行的头信息区,剩下的才是Null值字段标识位。
3)字段值区:保存基本类型和8个字节长度以内的值,如果某个字段值超过了8个字节,则保存该字段的长度与offset偏移量。在目前的实现中,一般的Bool类型、数值类型和长度较短的时间类型、精度低一些的Decimal类型可以宝UC你在定长部分。
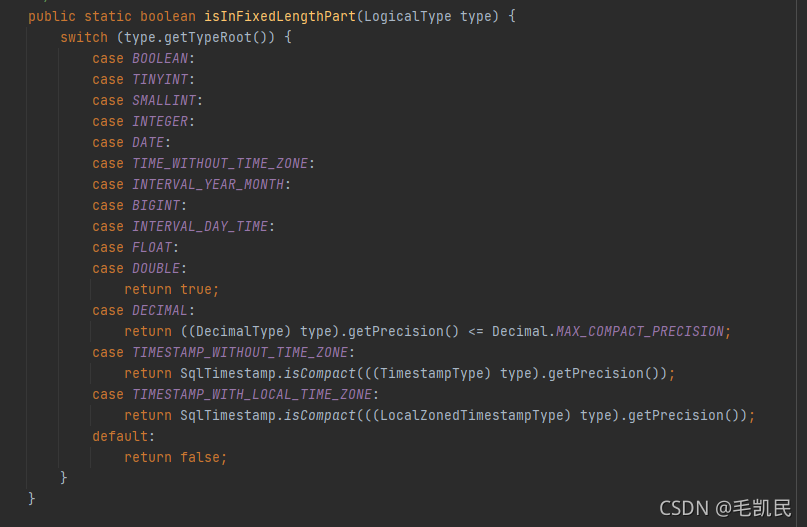
在目前的设计中,定长部分全部保存在1个MemorySegment中,以提升读写BinaryRow中字段的速度。在写入阶段,如果BinaryRow中定长部分超过单个MemorySegment的存储容量,确实有非常多的字段,建议增加MemorySegment的大小。
变长部分用来保存超过8个字节长度的字段的值,可能会保存跨越多个MemorySegment的字段。
BinaryRow实际上是参照Spark的UnsageRow 来设计的,两者的区别在于Flink的BinaryRow不在保存在连续内存中的,如果不定长部分足够小,可以保存在一个固定长度的内存中。
三、数据序列化
3.1 数据序列化/反序列化
数据序列化、反序列化的概要过程:
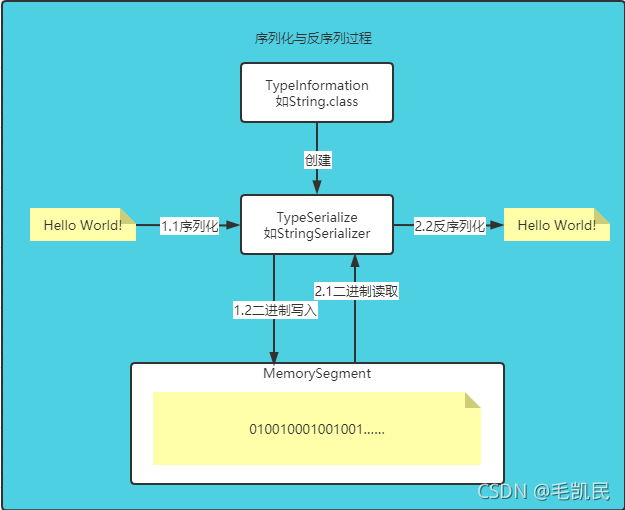
对于嵌套类型的数据结构,从最内层的原子字段开始进行序列化,外层的TypeSerialize负责将内层的序列化结果组装到一起。
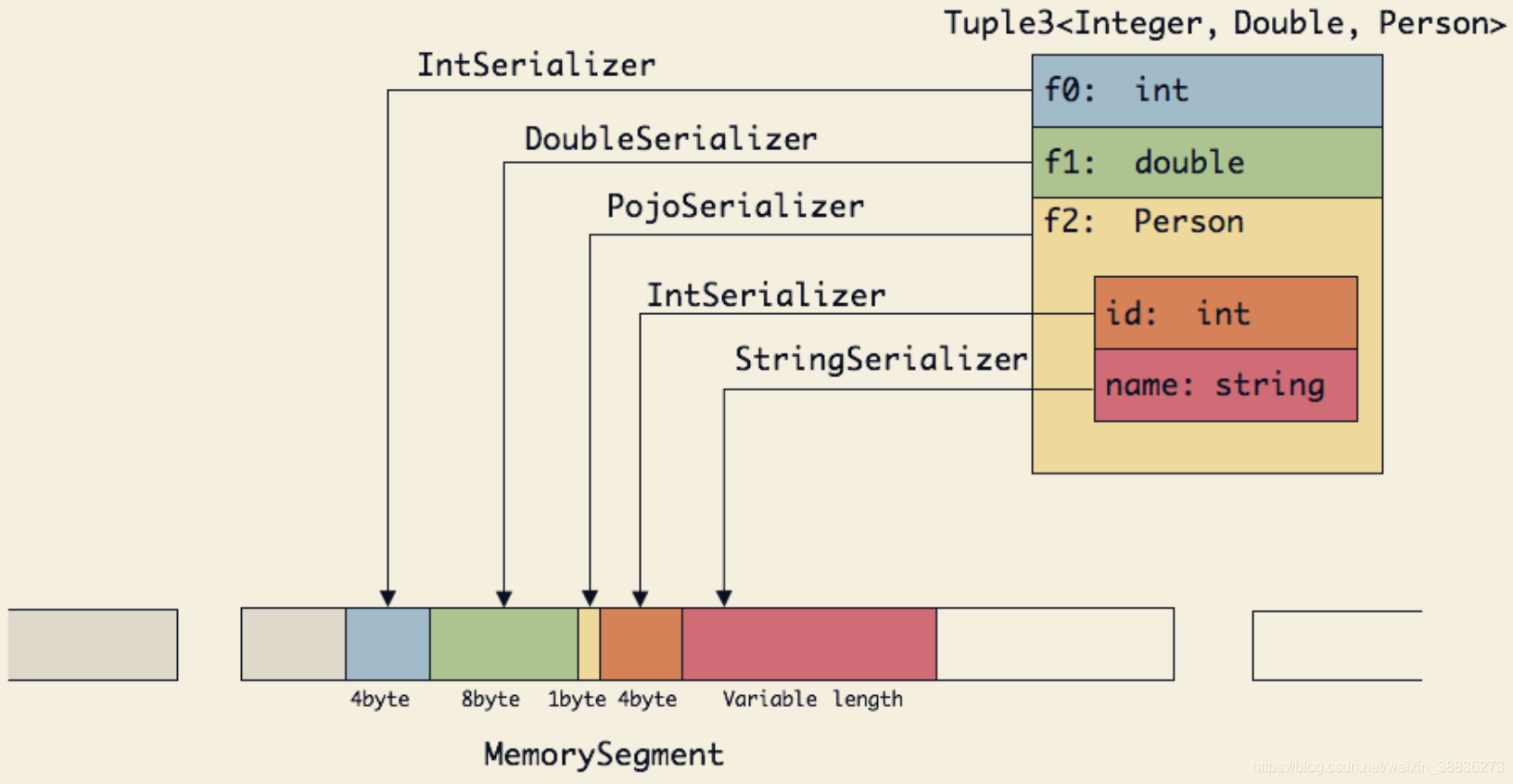
反序列化的时候,Tuple中的每个子序列化器能够自动识别应该读取到多少字节的数据,如对于int类型,读取32字节,对于String类型,则会首先读取长度部分,根据长度的数值计算出字符串的起始内存地址和应该读取的字节长度。
3.2 String的序列化过程
StringSerializer中实现了serialize和deserializer方法,调用StringValue.class实现了数据的序列化和反序列化。
#StringSerializer.java

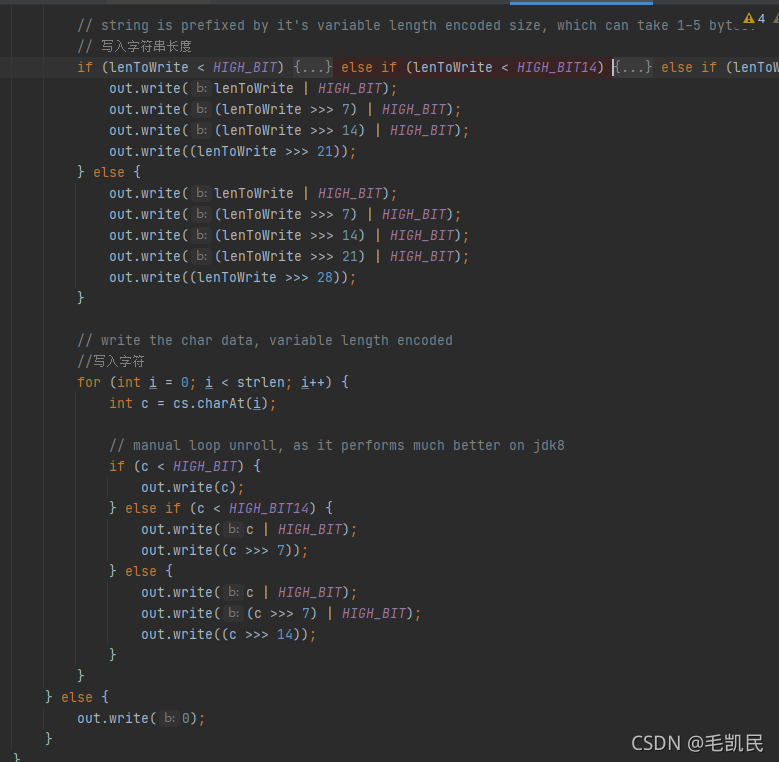
最终的实际序列化动作交给了StringValue.class执行,写入String的长度和String的值到java.io.DataOutput,实际上就是写入MemorySegment中。
#StringValue.java#writeString
 Fink中的序列化实际上都调用了DataOutputView接口,DataOutputView接口继承自DataOutput接口。
Fink中的序列化实际上都调用了DataOutputView接口,DataOutputView接口继承自DataOutput接口。
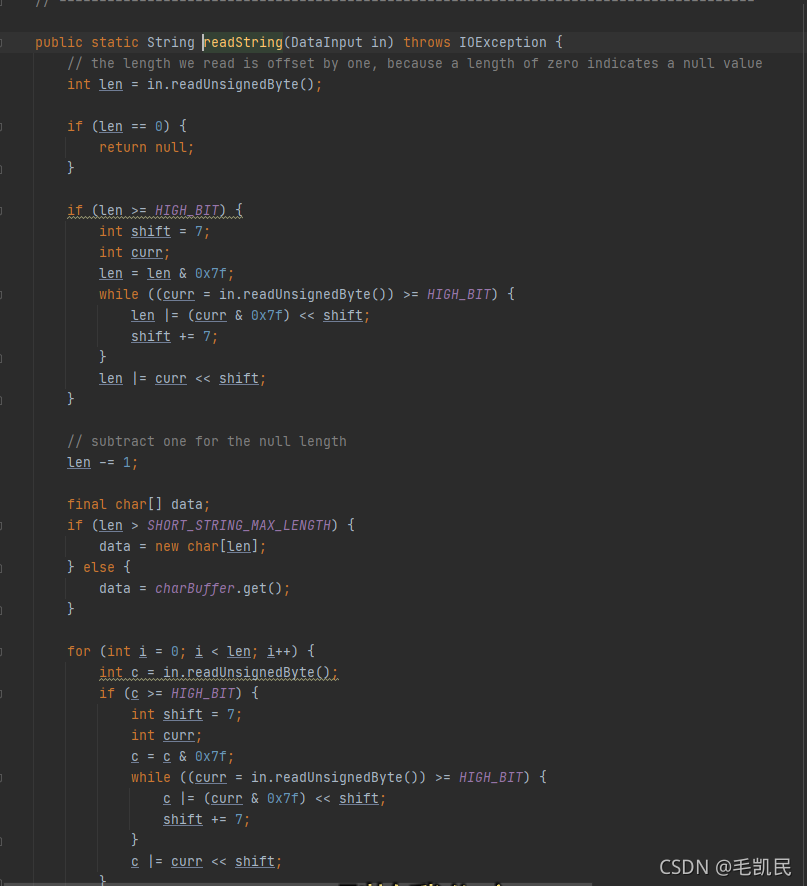
反序列hue的逻辑是相反的,将二进制数据流转换为UTF8编码的字符串。
#StringValue.class#readString
接下来Flink内存管理篇,如果对Flink感兴趣或者正在使用的小伙伴,可以加我入群一起探讨学习。
参考书籍《Flink 内核原理与实现》




 京公网安备 11010802041100号
京公网安备 11010802041100号