在流处理中,数据是连续不断到来的。每个任务进行计算处理时,可以基于当前数据直接转换得到输出结果,也可以依赖一些其他数据。这些由一个任务维护,并且用来计算输出结果的所有数据,就叫作这个任务的状态。
算子任务可以分为无状态和有状态。
无状态的算子任务只需要观察每个独立事件,根据当前输入的数据直接转换输出结果,如 map、filter、flatMap。
有状态的算子任务,除当前数据之外,还需要一些其他数据(状态)来得到计算结果,如聚合算子和窗口算子。

Flink 将状态直接保存在内存中来保证性能,并通过分布式扩展来提高吞吐量。可以认为是子任务实例上的一个本地变量,能够被任务的业务逻辑访问和修改。
public interface ValueState
// 获取当前状态
T value() throws IOException;
// 对状态进行更新
void update(T var1) throws IOException;
}
为了让运行时上下文清楚到底是哪个状态,需要一个状态描述器 ValueStateDescriptor 来提供状态的基本信息。
public interface ListState
// 传入一个列表values,直接对状态进行覆盖
void update(List
// 向列表中添加多个元素,以列表values形式传入。
void addAll(List
}
列表状态的状态描述器是 ListStateDescriptor。
public interface MapState
// 传入一个Key,查询对应的Value值
UV get(UK var1) throws Exception;
// 传入一个键值对,更新Key对应的Value值
void put(UK var1, UV var2) throws Exception;
// 将传入的映射map中所有键值对全部添加到映射状态中
void putAll(Map
// 将指定Key的键值对删除
void remove(UK var1) throws Exception;
// 判断是否存在指定Key
boolean contains(UK var1) throws Exception;
// 获取映射状态中所有的键值对
Iterable
// 获取映射状态中所有的键
Iterable
// 获取映射状态中所有的值
Iterable
// 获取映射状态的迭代器
Iterator
// 判断映射状态是否为空
boolean isEmpty() throws Exception;
}
// 这个接口保存的是一个聚合值,调用add方法时是将新数据和之前的状态进行归约,并且用结果来更新状态。
public interface ReducingState
}
// 第二个参数就是定义了归约聚合逻辑的ReduceFunction,另外两个参数则是状态的名称和类型。
public ReducingStateDescriptor(String name, ReduceFunction
// 聚合逻辑是由在描述器中传入一个更加一般化的聚合函数
public AggregatingStateDescriptor(String name, AggregateFunction
SingleOutputStreamOperator
.withTimestampAssigner(new SerializableTimestampAssigner
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
})
);
stream.keyBy(event -> event.user).flatMap(new MyFlatMap()).print();
// 用于Keyed State测试
public static class MyFlatMap extends RichFlatMapFunction
// 定义状态
ValueState
ListState
MapState
ReducingState
AggregatingState
@Override
public void open(Configuration parameters) throws Exception {
myValueState = getRuntimeContext().getState(new ValueStateDescriptor
myListState = getRuntimeContext().getListState(new ListStateDescriptor
myMapState = getRuntimeContext().getMapState(new MapStateDescriptor
myReducingState = getRuntimeContext().getReducingState(new ReducingStateDescriptor
new ReduceFunction
@Override
public Event reduce(Event event, Event t1) throws Exception {
return new Event(event.user, event.url, t1.timestamp);
}
},
Event.class));
myAggregatingState = getRuntimeContext().getAggregatingState(new AggregatingStateDescriptor
new AggregateFunction
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(Event event, Long aLong) {
return aLong + 1;
}
@Override
public String getResult(Long aLong) {
return "count:" + aLong;
}
@Override
public Long merge(Long aLong, Long acc1) {
return aLong + acc1;
}
},
Long.class));
}
@Override
public void flatMap(Event event, Collector
// 访问和更新状态
myValueState.update(event);
myListState.add(event);
myMapState.put(event.user, myMapState.get(event.user) == null ? 1: myMapState.get(event.user) + 1);
System.out.println(event.user + myMapState.get(event.user));
myReducingState.add(event);
System.out.println(event.user + myReducingState.get());
myAggregatingState.add(event);
System.out.println(myAggregatingState.get());
}
}
在实际应用中,很多状态会随着时间的推移而增长,如果不加以限制,最终会导致存储空间的耗尽。
可以在代码中调用 clear() 方法来清除状态,但是有时候逻辑要求不能这么做,这时就需要配置一个状态生存时间,当状态存在时间超过这个值就将它清除。
状态创建的时候,设置失效时间 = 当前时间 + TTL,之后如果有对状态的访问或修改,可以再对失效时间进行更新。配置状态的 TTL 时,需要创建一个 StateTtlConfig 配置对象,然后调用状态描述器的 enableTimeToLive() 方法启动 TTL 功能。
ValueStateDescriptor
// 配置状态TTL
StateTtlConfig ttlCOnfig= StateTtlConfig.newBuilder(Time.hours(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp)
.build();
valueStateDescriptor.enableTimeToLive(ttlConfig);
myValueState = getRuntimeContext().getState(valueStateDescriptor);
算子状态就是一个算子并行实例上定义的状态,作用范围被限定为当前算子任务。算子状态跟数据的 Key 无关,所以不同 Key 的数据只要被分发到同一个并行子任务,就会访问到同一个算子状态。
当算子的并行度发生变化时,算子状态也支持在并行的算子任务实例之间做重组分配。根据状态的类型不同,重组分配的方案也会不同。
因为不存在 Key,所有数据发往哪个分区是不能预测的。所以当发生故障重启之后,我们不能保证某个数据跟之前一样,进入同一个并行子任务、访问同一个状态。所以需要自行设计状态的快照保存和恢复逻辑。
public interface CheckpointedFunction {
// 保存状态快照到检查点,调用这个方法
void snapshotState(FunctionSnapshotContext var1) throws Exception;
// 初始化状态时调用这个方法,也会在恢复状态时调用
void initializeState(FunctionInitializationContext var1) throws Exception;
}
SingleOutputStreamOperator
.withTimestampAssigner(new SerializableTimestampAssigner
@Override
public long extractTimestamp(Event event, long l) {
return event.timestamp;
}
})
);
// 批量缓存输出
stream.addSink(new BufferSink(10));
public static class BufferSink implements SinkFunction
// 定义当前类的属性,批量
private final int threshold;
public BufferSink(int threshold) {
this.threshold = threshold;
}
private List
// 定义一个算子状态
private ListState
@Override
public void invoke(Event value, Context context) throws Exception {
// 缓存到列表
bufferedElements.add(value);
// 判断是否到达阈值,如果达到,就批量写入
if (bufferedElements.size() == threshold) {
// 用打印到控制台模拟写入外部系统
for (Event event: bufferedElements) {
System.out.println(event);
}
System.out.println("========输出完毕========");
bufferedElements.clear();
}
}
@Override
public void snapshotState(FunctionSnapshotContext functionSnapshotContext) throws Exception {
// 清空状态
checkPointedState.clear();
// 对状态进行持久化,复制缓存的列表到列表状态
for (Event event: bufferedElements) {
checkPointedState.add(event);
}
}
@Override
public void initializeState(FunctionInitializationContext functionInitializationContext) throws Exception {
// 定义算子状态
ListStateDescriptor
checkPointedState = functionInitializationContext.getOperatorStateStore().getListState(stateDescriptor);
// 如果从故障恢复,需要将ListState中的所有元素复制到列表中
if (functionInitializationContext.isRestored()) {
for (Event event: checkPointedState.get()) {
bufferedElements.add(event);
}
}
}
}
将状态广播出去,所有并行子任务的状态都是相同的,并行度调整时只要直接复制就可以了。
由于配置或者规则数据是全局有效的,我们需要把它广播给所有的并行子任务。而子任务需要把它作为一个算子状态保存起来,以保证故障恢复后处理结果是一致的。这时的状态,就 是一个典型的广播状态。
在代码上,可以直接调用 DataStream 的 broadcast() 方法,传入一个“映射状态描述器”说明状态的名称和类型,就可以得到一个“广播流”,进而将要处理的数据流与这条广播流进行连接,就会得到“广播连接流”。注意广播状态只能用在广播连接流中。
电商应用中,往往需要判断用户先后发生的行为的“组合模式”,比如“登录-下单”,检测出这些连续的行为进行统计,就可以了解平台的运用状况以及用户的行为习惯。
patternStream = env.fromElements( broadcastStream = patternStream.broadcast(descriptor);// 用户的行为数据流
DataStreamSource
new Action("Alice", "login"),
new Action("Alice", "pay"),
new Action("Bob", "login"),
new Action("Bob", "order")
);
// 行为模式流,基于它构建广播流
DataStreamSource
new Pattern("login", "pay"),
new Pattern("login", "order")
);
// 定义广播状态描述器
MapStateDescriptor
BroadcastStream
// 连接两条流进行处理
SingleOutputStreamOperator
.connect(broadcastStream)
.process(new PatternDetector());
matches.print();
// 实现自定义的KeyedBroadcastProcessFunction
public static class PatternDetector extends KeyedBroadcastProcessFunction
// 定义一个keyedState,保存上一次用户行为
ValueState
@Override
public void open(Configuration parameters) throws Exception {
preActiOnState= getRuntimeContext().getState(new ValueStateDescriptor
}
@Override
public void processElement(Action action, KeyedBroadcastProcessFunction
// 从广播状态中获取匹配模式
ReadOnlyBroadcastState
Pattern pattern = patternState.get(null);
// 拿到上一次行为
String preAction = preActionState.value();
// 判断是否匹配
if (preAction != null && pattern != null) {
if (pattern.action1.equals(preAction) && pattern.action2.equals(action.action)) {
collector.collect(new Tuple2<>(readOnlyContext.getCurrentKey(), pattern));
}
}
// 更新状态
preActionState.update(action.action);
}
@Override
public void processBroadcastElement(Pattern pattern, KeyedBroadcastProcessFunction
// 从上下文中获取广播状态,并用当前数据更新状态
BroadcastState
patternState.put(null, pattern);
}
}
// 定义用户行为事件和模式的POJO类
public static class Action {
public String userId;
public String action;
public Action() {
}
public Action(String userId, String action) {
this.userId = userId;
this.action = action;
}
@Override
public String toString() {
return "Action{" +
"userId='" + userId + '\'' +
", action='" + action + '\'' +
'}';
}
}
public static class Pattern {
public String action1;
public String action2;
public Pattern() {
}
public Pattern(String action1, String action2) {
this.action1 = action1;
this.action2 = action2;
}
@Override
public String toString() {
return "Pattern{" +
"action1='" + action1 + '\'' +
", action2='" + action2 + '\'' +
'}';
}
}
Flink 对状态进行持久化的方式,就是将当前所有分布式状态迸行“快照”保存,写入一个检查点或者保存点,保存到外部存储系统中。具体的存储介质,一般是分布式文件系统。
有状态流应用中的检查点,其实就是所有任务的状态在某个时间点的一个快照(一份拷贝)。Flink 会定期保存检查点,在检查点中会记录每个算子的 id 和状态。
默认情况下,检查点是被禁用的,需要在代码中手动开启。直接调用执行环境的 enableCheckpointin() 方法就可以开启检查点。
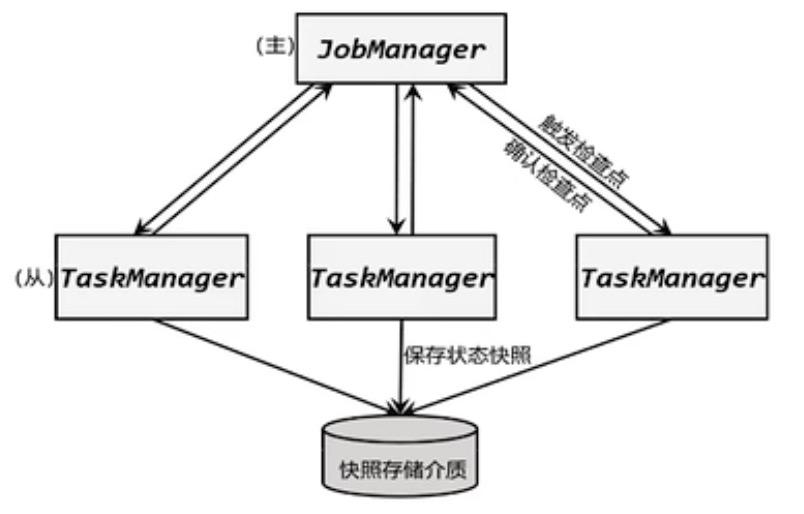
检查点的保存离不开 JobManager 和 TaskManager,以及外部存储系统的协调。在应用进行检查点保存时,首先会由 JobManager 向所有 TaskManager 发出触发检查点的命令,TaskManger 收到之后,将当前任务的所有状态进行快照保存,持久化到远程的存储介质中,完成之后向 JobManager 返回确认信息。这个过程是分布式的, JobManger 收到所有 TaskManager 的返回信息后,就会确认当前检查点成功保存。
在 Flink 中,状态的存储、访问以及维护,都是由一个可插拔的组件决定的,这个组件就叫作状态后端。
状态后端主要负责两件事:一是本地的状态管理,二是将检查点写入远程的持久化存储。







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 ![[大整数乘法] java代码实现](https://img1.php1.cn/3cd4a/24c6f/9f3/0133bb25da242824.jpeg)