1. strand bias 简介
2. Fisher's exact test 理解
3. Fisher's exact test 估计链偏差
overview
Strand bias(链偏差),当由正向链和反向链提供的信息推断出的基因型不一致时,链偏差就发生了。当reads映射到正向和反向链显著不同,出现一种不平衡链映射现象。
Strand bias(链偏倚),链偏倚是一种测序偏倚,其中一条DNA链比另一条更受青睐,这可能导致对一个等位基因与另一个等位基因观测到的证据量的不正确评估。
当然,也不能简单对Strand bias简单地定义,如下:

Strand bias scores
Strand bias scores 的测量是基于2x2的二联表,二联表中每个单元格代表的意义详细如下:
a. Forward strand reference allele.
b. Forward strand non reference allele.
c. Reverse strand reference allele.
d. Reverse strand non reference allele
按文献讲述,测量Strand bias scores 有如下3种方式:

SB和GATK-SB分数的范围都是0到无穷,而Fisher分数的范围是0到1。对于我们定义的所有3个分数,较低的值意味着较少的Strand bias ,较高的分数意味着更严重的Strand bias。
Cause of strand bias
以下罗列可能引入Strand bias的情况:
1. 分析时局部重新排列和BAQ;
2. 由于文库准备如PCR扩增;
3. 上机测序测序错误;
4. 测序过程中的取样变化引起。
见《第5章 - 假设检验-Pearson卡方检验与Fisher精确检验》
实现
按上面描述的有三种方法可以可以估算链偏差的值,这里讲述第三种Fisher's exact test实现过程。
R实现,调用函数fisher.test()
Usage:
fisher.test(x, y = NULL, workspace = 200000, hybrid = FALSE,
control = list(), or = 1, alternative = "two.sided",
conf.int = TRUE, conf.level = 0.95,
simulate.p.value = FALSE, B = 2000)
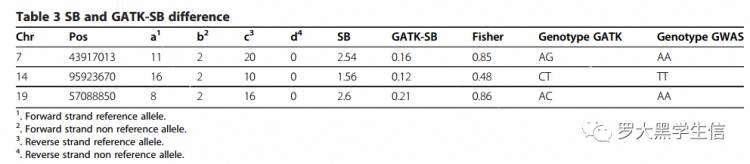
x <- matrix(c(11,2,20,0),nrow=2)
Ftest <- fisher.test(x)
Fisher's Exact Test for Count Data
data: x
p-value = 0.1477
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
0.000000 3.374997
sample estimates:
odds ratio
0
pvalue= round(Ftest$p.value, 5) = 0.14773
oddsRatio= round(Ftest$estimate, 5) = 0
python实现,第三方包scipy.stats中,有直接表达Fisher's exact test的函数fisher_exact()
import scipy.stats
fisher = scipy.stats.fisher_exact([[20, 11], [0, 2]])
fisher
(inf, 0.14772727272727287)
oddsRatio = fisher[0]
pvalue = fisher[1]
解读
由Fisher's exact test的函数执行后,可得到两个相关值,一个为pvalue,另一个为oddsRatio。
pvalue
pvalue= 0.14773
意义:由于P>α(显著性水平α=0.01),表示链不存在显著性的偏差。(也可以理解为 p值为 0.14773 ,即有14.773%的可能性没有统计上令人信服的偏差证据,)
Fisher Scores = 1 - pvalue = 0.85227
意义:较低的值意味着较少的Strand bias ,较高的分数意味着更严重的Strand bias。
回顾假设检验相关知识点:
p值为各样本统计量的差异来自抽样误差的概率
显著水平α为犯第一类错误(H0为真时却被拒绝,即实验没有效果却被判定为有效果)的概率,一般设置阈值为0.05,0.01,0.001。
若P>α,就没有理由怀疑H0的真实性,结论为不拒绝H0,不否定此样本是来自于该总体的结论,也即差别无显著意义。
若P≤α,则拒绝H0,接受H1,也就是这些统计量来自不同的总体,其差别不能仅由抽样误差来解释,结论为差别有显著性意义。
oddsRatio

参考:
The effect of strand bias in Illumina short-read sequencing data an Guo,
Jiang Li,Chung-I Li,Jirong Long,David C Samuels &Yu Shyr BMC Genomics volume 13, Article number: 666 (2012) Cite this article
https://gatk.broadinstitute.org/hc/en-us/articles/360035532152-Fisher-s-Exact-Test
https://mathworld.wolfram.com/FishersExactTest.html
https://gitee.com/ChitandaSatou/VarDict/blob/master/teststrandbias.R
https://www.biostars.org/p/16033/


![[二分图]JZOJ 4612 游戏](https://img.php1.cn/3cd4a/1eebe/cd5/2fdc212433a29829.png)







 京公网安备 11010802041100号
京公网安备 11010802041100号