作者:仔仔衰才_887 | 来源:互联网 | 2023-09-16 14:51

本文首发于Ressmix个人站点:https://www.tpvlog.com
我们在搭建Redis的主从架构时,主节点一旦由于故障不能提供服务,需要人工将从节点晋升为主节点,同时还要通知应用方更新主节点地址,对于很多应用场景这种故障处理的方式是无法接受的。
要实现Redis的真正高可用,我们需要完成主从架构下的故障自动转移。Redis官方提供了一套Redis Sentinel机制,用于当主节点出现故障时,自动完成故障发现和故障转移。
一、基本架构
哨兵模式下,我们需要配置一些哨兵节点(为了保证哨兵自身高可用,至少部署3个哨兵节点),这些哨兵节点构成了一个集群,监控着普通的主从节点的状态:
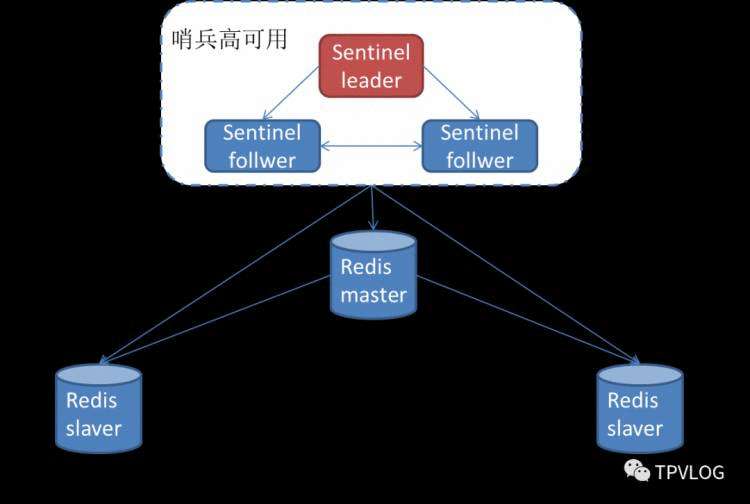
Redis Sentinel包含了若干个Sentinel节点,这样做也带来了两个好处:①对于节点的故障判断是由多个Sentinel节点共同完成,这样可以有效地防止误判;②即使个别Sentinel节点不可用,整个Sentinel集群依然是可用的。
哨兵模式提供了以下核心功能:
监控:每个Sentinel节点会对数据节点(Redis master/slave 节点)和其余Sentinel节点进行监控;
通知:Sentinel节点会将故障转移的结果通知给应用方;
故障转移:实现slave晋升为master,并维护后续正确的主从关系;
配置中心:在Redis Sentinel模式中,客户端在初始化的时候连接的是Sentinel节点集合,从中获取主节点信息。
二、基本原理
2.1 监控
Sentinel节点需要监控master、slave以及其它Sentinel节点的状态。这一过程是通过Redis的pub/sub系统实现的。Redis Sentinel一共有三个定时监控任务,完成对各个节点发现和监控:
监控主从拓扑信息:每隔10秒,每个Sentinel节点,会向master和slave发送 INFO
命令获取最新的拓扑结构;
Sentinel节点信息交换:每隔2秒,每个Sentinel节点,会向Redis数据节点的 __sentinel__:hello
频道上,发送自身的信息,以及对主节点的判断信息。这样,Sentinel节点之间就可以交换信息;
节点状态监控:每隔1秒,每个Sentinel节点,会向master、slave、其余Sentinel节点发送 PING
命令做心跳检测,来确认这些节点当前是否可达。
2.2 主观下线(sdown)
每个Sentinel节点,每隔1秒会对数据节点发送 ping
命令做心跳检测,当这些节点超过 down-after-milliseconds
没有进行有效回复时,Sentinel节点会对该节点做失败判定,这个行为叫做主观下线。
2.3 客观下线(odown)
客观下线,是指当大多数Sentinel节点,都认为master节点宕机了,那么这个判定就是客观的,叫做客观下线。
Sentinel认为主观下线之后通过发送 sentinelis-master-down-by-addr*
来确认主节点是否客观下线。
| 参数 | 意义 |
|---|
| ip/port | 当前认为下线的主节点的ip和端口 |
| current_epoch | 配置纪元 |
| run_id | *标识仅用于查询是否下线
有值标识该哨兵节点希望对方将自己设置为leader
询问时用*,选举时用run_id |
那么这个大多数是指多少呢?
这其实就是分布式协调中的quorum判定了,大多数就是过半数,比如哨兵数量是3,那么大多数就是3/2+1=2个,哨兵数量是5,大多数就是5/2+1=3个。Redis有一个参数 quorum
用于配置这个大多数数量。
Sentinel节点的数量至少为3个,否则不满足quorum判定条件。
2.4 哨兵选举
如果发生了客观下线,那么哨兵节点会选举出一个Leader来进行实际的故障转移工作。Redis使用了Raft算法来实现哨兵领导者选举,大致思路如下:
每个Sentinel节点都有资格成为领导者,当它认为主节点客观下线后,会向其他Sentinel节点发送 sentinelis-master-down-by-addr
命令,携带 run_id
要求自己成为领导者;
收到命令的Sentinel节点,如果没有同意过其他Sentinel节点的 sentinelis-master-down-by-addr
命令,将同意该请求,否则拒绝(每个Sentinel节点只有1票);
如果该Sentinel节点发现自己的票数已经大于等于 MAX(quorum,num(sentinels)/2+1)
,那么它将成为领导者;
如果此过程没有选举出领导者,将进入下一次选举。
2.5 故障转移
选举出的Leader Sentinel节点将负责故障转移,也就是进行master/slave节点的主从切换。故障转移,首先要从slave节点中筛选出一个作为新的master,主要考虑以下slave信息:
跟master断开连接的时长:如果一个slave跟master的断开连接时长已经超过了 down-after-milliseconds
的10倍,外加master宕机的时长,那么该slave就被认为不适合选举为master;
slave的优先级配置: slave priority
参数值越小,优先级就越高;
复制offset:当优先级相同时,哪个slave复制了越多的数据(offset越靠后),优先级越高;
run id:如果offset和优先级都相同,则哪个slave的run id越小,优先级越高。
接着,筛选完slave后, 会对它执行 slaveofnoone
命令,让其成为主节点。最后,Sentinel领导者节点会向剩余的slave节点发送命令,让它们成为新的master节点的从节点,复制规则与 parallel-syncs
参数有关。
Sentinel节点集合会将原来的master节点更新为slave节点,并保持着对其关注,当其恢复后命令它去复制新的主节点。
Leader Sentinel节点,会从新的master节点那里得到一个 configuration epoch
,本质是个version版本号,每次主从切换的version号都必须是唯一的。其他的哨兵都是根据vetsion来更新自己的master配置。
三、总结
本章,我介绍了Redis哨兵模式的原理。在生产环境中,哨兵模式非常常用,一般都会按照一主多从+哨兵模式来部署Redis。








 京公网安备 11010802041100号
京公网安备 11010802041100号