Flink作为主流的分布式计算框架,满足批流一体、高吞吐低时延、大规模复杂计算、高可靠的容错和多平台部署能力。前文中介绍了Flink的数据流处理流程以及基本部署架构和概念,本文将对Flink中的核心基石进行深入介绍。
在流处理场景中,数据源源不断的流入系统,衡量流处理快和量两方面的性能,一般使用延迟(Latency)和吞吐(Throughput)两个指标。
延迟和吞吐是衡量流处理引擎的重要指标,在Flink流式计算引擎中,引入4个核心的机制以满足低延迟高吞吐的指标。这四个基石是Checkpoint、State、Time和Window:
Flink中定义了State,用来保存中间计算结果或者缓存数据。根据是否需要保存中间结果分为无状态计算和有状态计算。在批处理过程中,数据是划分为块分片去完成的,然后每一个Task去处理一个分片。当分片执行完成后,把输出聚合起来就是最终的结果。在这个过程当中,对于state的需求还是比较小的。对于流计算而言,事件持续不断的产生,如果每次计算都是相互独立的,不依赖上下游的事件,则是无状态计算;如果计算需要依赖于之前或者后续的事件,则是有状态的计算。
在Flink中使用State的典型场景如下:
Flink中提供了对State操作的接口,用户在开发Flink应用的时候,可以将临时数据保存在State中,同时利用checkpoint机制对state进行备份,一旦出现异常能够从保存的State中恢复状态,实现Exactly-Once。另外,对state的管理还需要注意以下几点:
Flink中有两种类型的State:Keyed State和Operator State。每种State有两种基本的形式:Managed State和Raw State,Managed State是由Flink管理的,Flink负责存储、恢复和优化;Raw State是由开发者管理的,需要用户自己进行序列化。通常,在DataStream上的状态,推荐使用Managed State,当实现一个用户自定义的Operator的时候,会使用到Raw State。
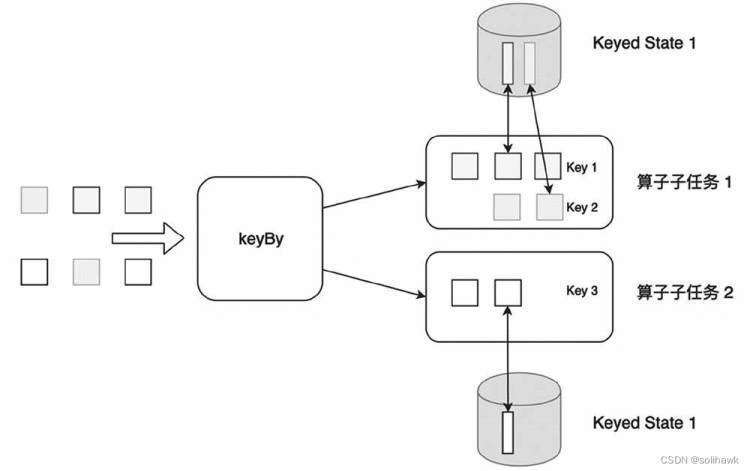
1)Keyed State
Keyed State是KeyedStream上的状态,其中state是以Key/Value的方式存储,并严格按照state operator操作的数据流进行划分和分布。假如输入流按照ID为key进行keyBy()分组,形成一个KeyedStream,数据流中所有keyID为1的数据共享一个状态,可以访问和更新这个状态,以此类推,每个Key对应一个状态。
2)Operator State
Operator State可以用在所有算子上,每个算子子任务共享一个状态,流入这个算子的子任务的所有数据都可以访问和更新这个状态。
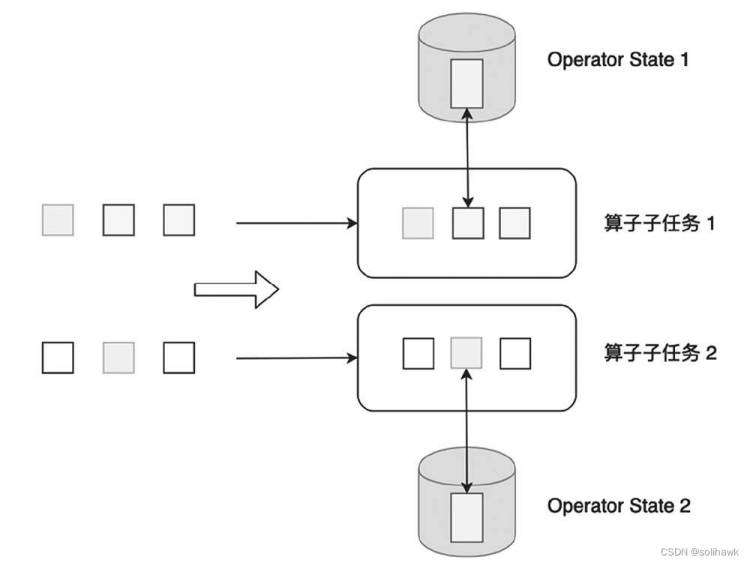
无论是Keyed State还是Operator State,Flink的状态都是基于本地的,即每个算子子任务维护着自身的状态,不能访问其它算子子任务的状态。Keyed State和Operator State的区别总结如下:
| 特点 | Keyed State | Operator State |
|---|---|---|
| 适用算子类型 | 只适用于KeyedStream上算子 | 适用于所有算子 |
| 状态分配 | 每个Key对应一个状态 | 一个算子Task对应一个状态 |
| 创建和访问方式 | 重写Rich Function,通过里面的RuntimeContext访问 | 实现CheckpointedFunction等接口 |
| 横向扩展 | 状态随着Key自动在多个算子子任务上迁移 | 有多种状态重新分配的方式 |
| 支持的数据类型 | ValueState、ListState、MapState等 | ListState、BroadcaseState等 |
Flink定期将状态数据持久化到存储,故障发生后从之前的备份中恢复数据,这个过程称为Checkpoint。Checkpoint为Flink提供了exactly-once的保障,可以理解为Flink在某一特定时刻的全局状态快照,包含了所有的Task/operator的状态。
Flink基于Chandy-Lamport算法实现了一个分布式的一致性快照,从而提供了一致性的语义。Checkpoint大致流程如下:
默认情况下Checkpoint机制是关闭的,需要调用env.enableCheckpointing(n)来开启,表示每隔n毫秒进行一次Checkpoint。Checkpoint是一个高负载的任务,需要设置合理的频率,设置过小可能上次checkpoint尚未完成下次的checkpoint已经开始;如果设置过大,checkpoint的频率更少消耗的系统资源也会更少,但是故障重启或恢复时,需要处理更多的数据。
在Checkpoint过程中有个Checkpoint Barrier的概念,checkpoint分界线是插入到数据流中将数据流切分成不同的段,并作为数据流的一部分向下流动。Flink中的Checkpoint逻辑是,算子接收到Barrier后,会对状态进行snapshot,每个Checkpoint Barrier有一个ID,表示该段数据属于哪个checkpoint。
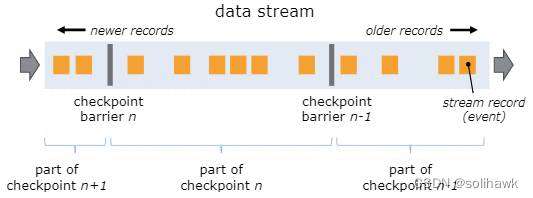
Barriers是Flink快照的核心要素,它们inject到数据流中而不会影响流量,并且barriers永远不会超过记录。同时来自不同快照的多个barriers可以同时在流中出现,这意味着可以同时发生各种快照。如上图所示:
Barrier根据是否缓存channel中的数据又分为两类:Barrier buffer和Barrier Track
基于Stream Aligning操作能够实现Exactly Once语义,但是也会给流处理应用带来延迟,因为aligned Barrier,会暂时缓存一部分Stream的记录到Buffer中,尤其是在数据流并行度很高的场景下可能更加明显,通常以最迟对齐Barrier的一个Stream为处理Buffer中缓存记录的时刻点。在Flink中,提供了一个开关,选择是否使用Stream Aligning,如果关掉则Exactly Once会变成At least once。
Checkpoint机制是为了故障重启的时候,使得作业中的状态数据与故障重启之前报错一致,是一种故障恢复的保护能力。Savepoints则是手动备份数据,以便进行调试、迁移,是协助开发调试的功能。Savepoints相关操作是有计划的,一般由开发者手动触发、管理和删除,比如将当前状态保存下来后,可以更新并行度、修改逻辑代码,甚至进行A/B测试等。
在流处理中,时间是一个核心的概念,是整个系统的基石。在Flink中,时间有三种类型:
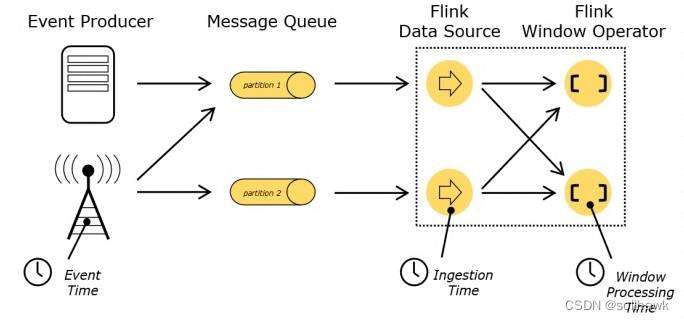
在Flink的流式处理中,绝大部分的业务都会使用EventTime,一般只在EventTime无法使用时,才会被迫使用ProcessingTime 或者IngestionTime。
Flink的三种时间语义中,只有Event Time需要设置Watermark。流式数据从产生到处理中间经过了很多过程,中间因为网络等原因可能会出现乱序,导致Flink接收到的事件的先后顺序不是严格按照Event Time的先后顺序排了的。一旦出现乱序,如果只根据EventTime决定window的运行,不能明确数据是否全部到位,但又不能无限期的等下去,此时必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了,这个特别的机制,就是 Watermark。Watermark本质上是Flink插入到数据流中的一种特殊的数据结构,它包含一个时间戳,并假设后续不会有小于该时间戳的数据。
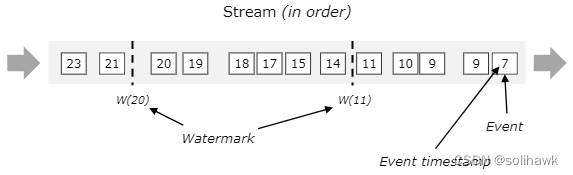
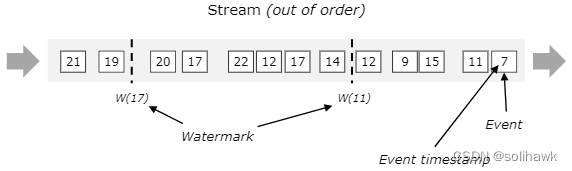
在实际的流计算中一个作业往往会处理多个Source的数据,每个并行的子任务会生成单独的watermark。这些不同的watermark在各自的source内是单调递增的,但是汇聚到一起时可能不是单调递增的。此时,Flink会选择所有流入的EventTime中最小的一个向下游流出,从而保证Watermark的单调递增和数据完整性。
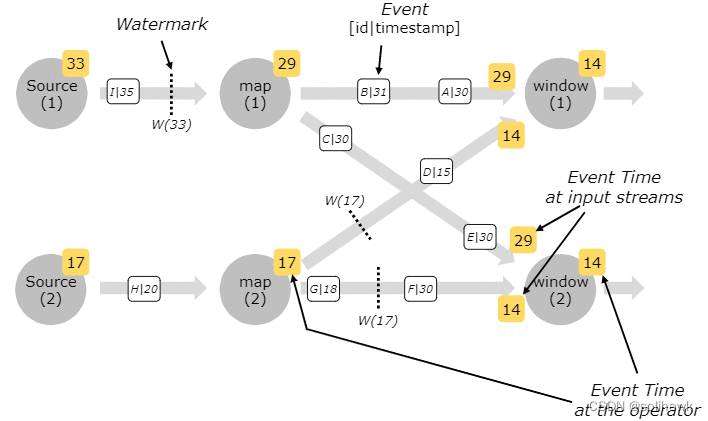
如图所示,Source算子生成各自的Watermark,并随着数据流向下游的map算子,map算子是无状态计算,所以会将Watermark向下透传。Window算子收到上游两个输入的watermark后,选择其中一个较小的发送给下游。Window(1)算子比较Watermark 29和Watermark 14,选择Watermark 14作为算子当前的Watermark发送给下游,Window(2)算子采用同样的处理逻辑。
流式数据中对事件的汇总统计不同于一般的批处理,比如说统计流式数据中的事件总数是不现实的,因为数据是无边界的。但是使用Window将一个无限stream切割为有限大小的窗口,然后在这些窗口内进行计算,因此window是一种切割无限数据为有限块进行处理的手段。通常划分window有两种方式:time-driven-window和data-driven-window

在Flink中提供了三种默认的Windows类型:滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)和会话窗口(Session Window)
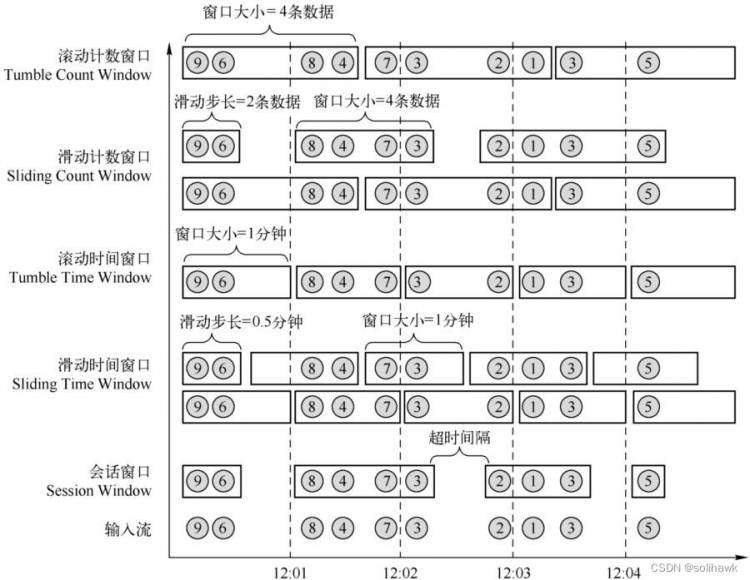
1)滚动窗口
将数据依据固定的长度对数据进行切分。滚动窗口分配器将每个元素分配到一个指定窗口大小的窗口中,滚动窗口有一个固定的大小,并且不会出现重叠。这个固定的大小可以是固定的时间范围或者固定的数据量大小
val tumblingCnts: DataStream[(Int, Int)] = vehicleCnts
// key stream by sensorId
.keyBy(0)
// tumbling count window of 100 elements size
.countWindow(100)
// compute the carCnt sum
.sum(1)
val tumblingCnts: DataStream[(Int, Int)] = vehicleCnts
// key stream by sensorId
.keyBy(0)
// tumbling time window of 1 minute length
.timeWindow(Time.minutes(1))
// compute sum over carCnt
.sum(1)
2)滑动窗口
由固定的窗口长度和滑动间隔组成。滑动窗口分配器将元素分配到固定长度的窗口中,与滚动窗口类似,窗口的大小由窗口大小参数来配置,另一个窗口滑动参数控制滑动窗口开始的频率。因此,滑动窗口如果滑动参数小于窗口大小的话,窗口是可以重叠的,在这种情况下元素会被分配到多个窗口中。
val slidingCnts: DataStream[(Int, Int)] = vehicleCnts
.keyBy(0)
// sliding count window of 100 elements size and 10 elements trigger interval
.countWindow(100, 10)
.sum(1)
val slidingCnts: DataStream[(Int, Int)] = vehicleCnts
.keyBy(0)
// sliding time window of 1 minute length and 30 secs trigger interval
.timeWindow(Time.minutes(1), Time.seconds(30))
.sum(1)
3)会话窗口
一种特殊的窗口,当超过一段时间该窗口没有收到新的数据,则视为该窗口结束,所以无法事先确定窗口的长度、元素个数,窗口之间也不会相互重叠。
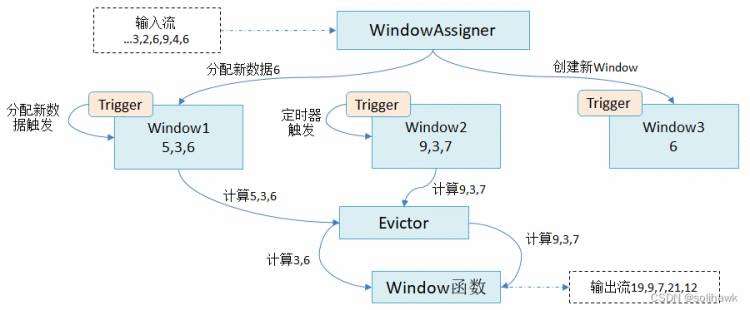
Flink中提供了很多窗口算子负责处理窗口,在整个处理过程中可能会存在多个窗口。窗口机制如上图所示:
// create windowed stream using a WindowAssigner
var windowed: WindowedStream[IN, KEY, WINDOW] = keyed
.window(myAssigner: WindowAssigner[IN, WINDOW])
// override the default trigger of the WindowAssigner
windowed = windowed.trigger(myTrigger: Trigger[IN, WINDOW])
// specify an optional evictor
windowed = windowed.evictor(myEvictor: Evictor[IN, WINDOW])
// apply window function to windowed stream
val output: DataStream[OUT] = windowed
.apply(myWinFunc: WindowFunction[IN, OUT, KEY, WINDOW])
分布式计算框架从最早的Hadoop MapReduce批量处理,到第二代的DAG框架,再到第三代的Spark批量和流式处理以及Storm流式处理,发展到第四代的Flink批流一体的处理架构,实现了低时延高吞吐、高可靠以及可扩展的分布式计算平台。
参考资料:



 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有