索引文档写入和近实时搜索原理
基本概念
Segments in Lucene
众所周知,Elasticsearch存储的基本单元是shard,ES种一个index可能分为多个shard,事实上每个shard都是一个Lucence的Index,并且每个Lucence Index由多个Segment组成,每个Segment事实上是一些倒排索引的集合,每次创建一个新的Document,都会归属一个新的Segment,而不会去修改原来的Segment。且每次的文档删除操作,仅仅会标记Segment的一个删除状态,而不会真正立马物理删除。所以说ES的Index可以理解为一个抽象的概念。如下图所示:
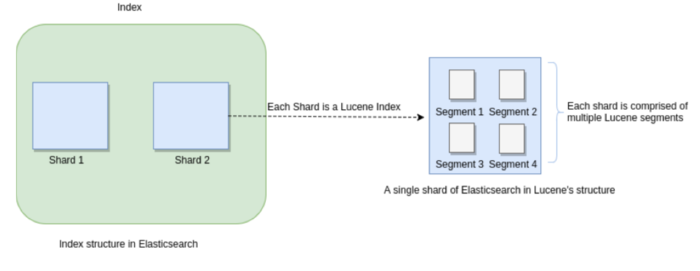
Commits in Lucene
Commit操作意味着将Segment合并,并写入磁盘。保证内存数据不丢失。但刷盘是很重的IO操作,所以为了性能不会刷盘那么及时。
Translog
新文档被索引意味着文档首先写入内存buffer和translog文件。每个shard都对应一个translog文件。
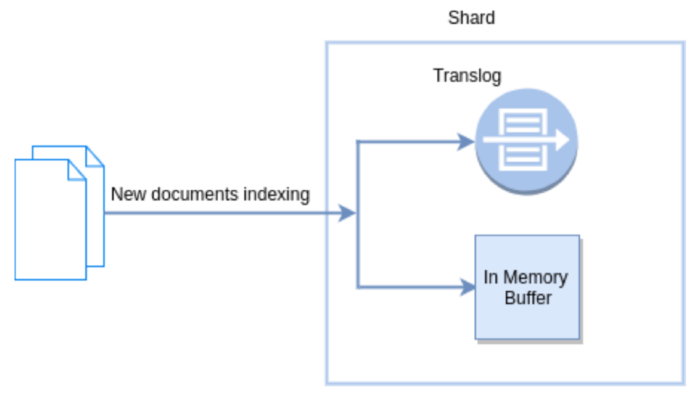
Refresh in Elasticsearch
在Elasticsearch种,_refresh操作默认每秒执行一次,意味着将内存buffer的数据写入到一个新的Segment中,这个时候索引变成了可被检索的。写入新Segment后会清空内存。
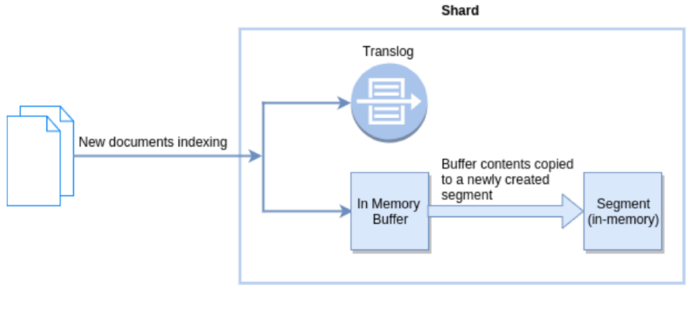
Flush in Elasticsearch
Flush操作意味着内存buffer的数据全都写入新的Segment中,并将内存中所有的Segments全部刷盘,并且清空translog日志的过程。
近实时搜索
提交一个新的段到磁盘需要一个fsync来确保段被物理性的写入磁盘,这样在断电的时候就不会丢数据。但是fsync操作代价很大,如果每次索引一个文档都去执行一次的话就会造成很大的性能问题。
像之前描述的一样,在内存索引缓冲区中的文档会被写入到一个新的段中。但是这里新段会被先写入到文件系统缓存--这一步代价会比较低,稍后再被刷新到磁盘(这一步代价比较高)。不过只要文件已经在系统缓存中,就可以像其它文件一样被打开和读取了。
原理:
当一个写请求发送到es后,es将数据写入memory buffer中,并添加事务日志(translog)。如果每次一条数据写入内存后立即写到硬盘文件上,由于写入的数据肯定是离散的,因此写入硬盘的操作也就是随机写入了。硬盘随机写入的效率相当低,会严重降低es的性能。
因此es在设计时在memory buffer和硬盘间加入了Linux的高速缓存(Filesy stemcache)来提高es的写效率。当写请求发送到es后,es将数据暂时写入memory buffer中,此时写入的数据还不能被查询到。默认设置下,es每1秒钟将memory buffer中的数据refresh到Linux的Filesy stemcache,并清空memory buffer,此时写入的数据就可以被查询到了。
Refresh API
在Elasticsearch中,写入和打开一个新段的轻量的过程叫做refresh。默认情况下每个分片会每秒自动刷新一次。这就是为什么我们说Elasticsearch是近实时搜索:文档的变化并不是立即对搜索可见,但会在一秒之内变为可见。
这些行为可能会对新用户造成困惑:他们索引了一个文档然后尝试搜索它,但却没有搜到。这个问题的解决办法是用refresh API执行一次手动刷新:
- 刷新所有索引
POST /_refresh
- 只刷新某一个索引
POST /索引名/_refresh
- 只刷新某一个文档
PUT /索引名/_doc/{id}?refresh
{"test":"test"}
并不是所有的情况都需要每秒刷新。可能你正在使用Elasticsearch索引大量的日志文件,你可能想优化索引速度而不是近实时搜索,可以通过设置refresh_interval,降低每个索引的刷新频率。
PUT /my_logs
{
"settings": { "refresh_interval": "30s" }
}
refresh_interval可以在既存索引上进行动态更新。在生产环境中,当你正在建立一个大的新索引时,可以先关闭自动刷新,待开始使用该索引时,再把它们调回来。
PUT /my_logs/_settings
{ "refresh_interval": -1 }
持久化变更
如果没有用fsync把数据从文件系统缓存刷(flush)到硬盘,我们不能保证数据在断电甚至是程序正常退出之后依然存在。为了保证Elasticsearch的可靠性,需要确保数据变化被持久化到磁盘。
在动态更新索引时,我们说一次完整的提交会将段刷到磁盘,并写入一个包含所有段列表的提交点。Elasticsearch在启动或重新打开一个索引的过程中使用这个提交点来判断哪些段隶属于当前分片。
即使通过每秒刷新(refresh)实现了近实时搜索,我们仍然需要经常进行完整提交来确保能从失败中恢复。但在两次提交之间发生变化的文档怎么办?我们也不希望丢失掉这些数据。Elasticsearch增加了一个translog,或者叫事务日志,在每一次对Elasticsearch进行操作时均进行了日志记录。
整个流程如下:
- 一个文档被索引之后,就会被添加到内存缓冲区,并且追加到了translog。如下图:

-
分片每秒refres一次,refresh完成后,缓存被清空
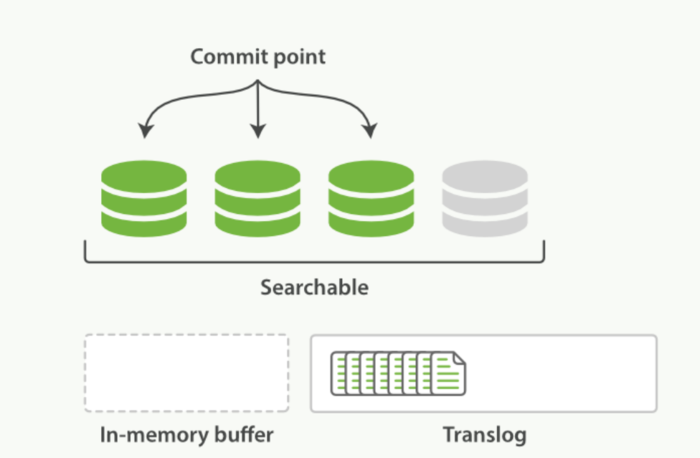
-
这个进程继续工作,更多的文档被添加到内存缓冲区和追加到事务日志
-
每隔一段时间--例如translog变得越来越大--索引被刷新(flush);一个新的translog被创建,并且一个全量提交被执行。
- 所有在内存缓冲区的文档被写入一个新的段
- 缓冲区被清空
- 一个提交点被写入磁盘
- 文件系统缓存通过fsync被刷新(flush)
- 老的translog被删除
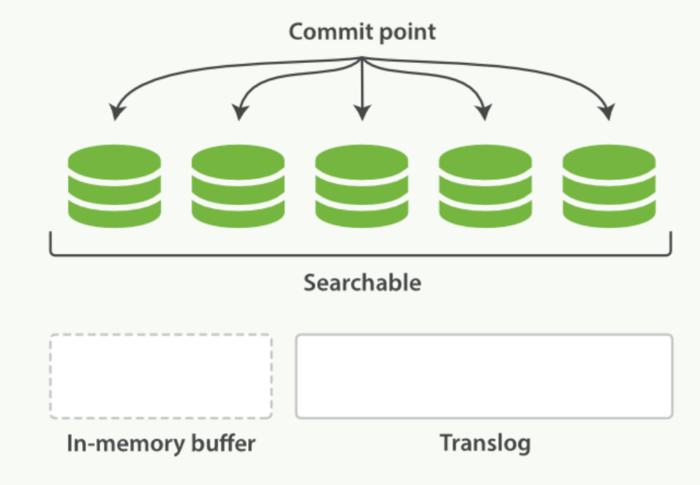
translog提供所有还没有被刷到磁盘的操作的一个持久化纪录。当Elasticsearch启动的时候,它会从磁盘中使用最后一个提交点去恢复已知的段,并且会重放translog中所有在最后一次提交后发生的变更操作。
Flush API
这个执行一个提交并且截断translog的行为在Es中被称为一次flush。分片每30分钟被自动刷新(flush),或者在translog太大的时候也会刷新。
flush API 可以被用来执行手工的刷新
POST /索引名称/_flush
#刷新(flush)所有的索引并且等待所有刷新在返回前完成
POST /_flush?wait_for_ongoin
我们知道用fsync把数据从文件系统缓存flush到硬盘是安全的,那么如果我们觉得偶尔丢失几秒数据也没关系,可以启用async。
PUT /索引名/_settings {
"index.translog.durability": "async",
"index.translog.sync_interval": "5s"
}
索引文档存储段合并机制
由于自动刷新流程每秒会创建一个新的段,这样会导致短时间内的段数量暴增。而段数目太多会带来较大的麻烦。每一个段都会消耗文件句柄、内存和CPU运行周期。更重要的是,每个搜索请求都必须轮流检查每个段;所以段越多,搜索也就越慢。
Elasticsearch通过在后台进行段合并来解决这个问题。小的段被合并到大的段,然后这些大的段再被合并到更大的段。段合并的时候会将那些旧的已删除文档从文件系统中清除。被删除的文档(或被更新文档的旧版本)不会被拷贝到新的大段中。
合并大的段需要消耗大量的I/O和CPU资源,如果任其发展会影响搜索性能。Elasticsearch在默认情况下会对合并流程进行资源限制,所以搜索仍然有足够的资源很好地执行。默认情况下,归并线程的限速配置indices.store.throttle.max_bytes_per_sec是20MB。对于写入量较大,磁盘转速较高,甚至使用SSD盘的服务器来说,这个限速是明显过低的。对于ELKStack应用,建议可以适当调大到100MB或者更高。
PUT /_cluster/settings
{
"persistent" : {
"indices.store.throttle.max_bytes_per_sec" : "100mb"
}
}
归并策略
归并线程是按照一定的运行策略来挑选 segment 进行归并的。主要有以下几条:
index.merge.policy.floor_segment默认2MB,小于这个大小的segment,优先被归并。
index.merge.policy.max_merge_at_once默认一次最多归并10个segment
index.merge.policy.max_merge_at_once_explicit默认optimize时一次最多归并30个segment。
index.merge.policy.max_merged_segment默认5GB,大于这个大小的segment,不用参与归并。optimize除外
optimize API
optimizeAPI大可看做是强制合并API。它会将一个分片强制合并到max_num_segments参数指定大小的段数目。这样做的意图是减少段的数量(通常减少到一个),来提升搜索性能。
在特定情况下,使用optimizeAPI颇有益处。例如在日志这种用例下,每天、每周、每月的日志被存储在一个索引中。老的索引实质上是只读的;它们也并不太可能会发生变化。在这种情况下,使用optimize优化老的索引,将每一个分片合并为一个单独的段就很有用了;这样既可以节省资源,也可以使搜索更加快速。
api:
POST /logstash-2014-10/_optimize?max_num_segments=1
java api:
forceMergeRequest.maxNumSegments(1)
Es乐观锁
Es的后台是多线程异步的,多个请求之间没有顺序,可能后发起修改请求的先被执行。Es的并发是基于自己的_version版本号进行并发控制的。
1. 基于seq_no
乐观锁示例:
先新增一条数据
PUT /item/_doc/4
{
"date":"2022-07-01 01:00:00",
"images":"aaa",
"price":22,
"title":"先"
}
查询:
GET /item/_doc/4
可以查出我们的seq_no和primary_term
{
"_index" : "item",
"_type" : "_doc",
"_id" : "4",
"_version" : 5,
"_seq_no" : 12,
"_primary_term" : 5,
"found" : true,
"_source" : {
"date" : "2022-07-01 01:00:00",
"images" : "aaa",
"price" : 33,
"title" : "先"
}
}
然后两个客户端都根据这个seq_no和primary_term去修改数据,会有一个提示异常的。
PUT /item/_doc/4?if_seq_no=12&if_primary_term=5
{
"date":"2022-07-01 01:00:00",
"images":"aaa",
"price":33,
"title":"先"
}
2. 基于external version
es提供了一个功能,不用它内部的_version来进行并发控制,你可以根据你自己维护的版本号进行并发控制。
?version=1&version_type=external
区别在于,version方式,只有当你提供的version与es中的version一模一样的时候,才可以进行修改,只要不一样,就报错。当version_type=external的时候,只有当你提供的version比es中的_version大的时候,才能完成修改
示例:
我先查出目前的version为7
{
"_index" : "item",
"_type" : "_doc",
"_id" : "4",
"_version" : 7,
"_seq_no" : 14,
"_primary_term" : 5,
"found" : true,
"_source" : {
"date" : "2022-07-01 01:00:00",
"images" : "aaa",
"price" : 33,
"title" : "先"
}
}
只有设置为8才能成功修改了
PUT /item/_doc/4?version=8&version_type=external
{
"title":"先"
}
分布式数据一致性如何保证
es5.0版本后
PUT /test_index/_doc/1?wait_for_active_shards=2&timeout=10s
{
"name":"xiao mi"
}
这代表着所有的shard中必须要有2个处于active状态才能执行成功,否则10s后超时报错。







 京公网安备 11010802041100号
京公网安备 11010802041100号