引言:在学习Match查询之前,一定要先了解倒排序索引和Analysis分词【ElasticSearch系列05:倒排序索引与分词Analysis】,这样才能快乐的学习ik分词和Match query查询。
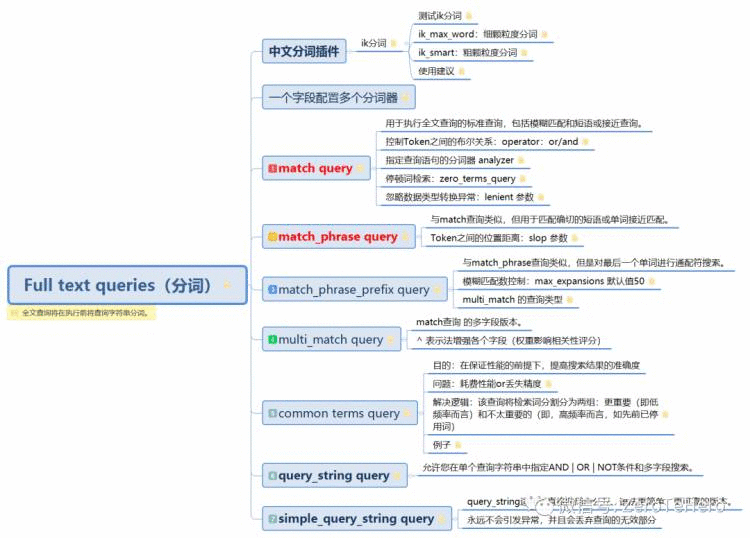
本文结构【开局一张图】
Full text queries 将在执行前将查询字符串分词。因为ES本身提供的分词器不太适合中文分词,所以在学习全文查询前,我们先简单了解下中文分词插件ik分词。
一、ik 分词
官网简介:The IK Analysis plugin integrates Lucene IK analyzer (http://code.google.com/p/ik-analyzer/) into elasticsearch, support customized dictionary.
Analyzer: ik_smart , ik_max_word , Tokenizer: ik_smart , ik_max_word
1.1 ik_max_word:细颗粒度分词
ik_max_word: 会将文本做最细粒度的拆分,比如会将“关注我系统学习ES”拆分为“关注,我,系统学,系统,学习,es”,会穷尽各种可能的组合,适合 Term Query;
# 测试分词效果
GET /_analyze
{"text": ["关注我系统学习ES"],"analyzer": "ik_max_word"
}
# 效果
{"tokens": [{"token": "关注","start_offset": 0,"end_offset": 2,"type": "CN_WORD","position": 0},{"token": "我","start_offset": 2,"end_offset": 3,"type": "CN_CHAR","position": 1},{"token": "系统学","start_offset": 3,"end_offset": 6,"type": "CN_WORD","position": 2},{"token": "系统","start_offset": 3,"end_offset": 5,"type": "CN_WORD","position": 3},{"token": "学习","start_offset": 5,"end_offset": 7,"type": "CN_WORD","position": 4},{"token": "es","start_offset": 7,"end_offset": 9,"type": "ENGLISH","position": 5}]
}
1.2 ik_smart:粗颗粒度分词
ik_smart: 会做最粗粒度的拆分,比如会将“关注我系统学习ES”拆分为“关注,我,系统,学习,es”,适合 Phrase 查询。
# 测试分词效果
GET /_analyze
{"text": ["关注我系统学习ES"],"analyzer": "ik_smart"
}
# 分词效果
{"tokens": [{"token": "关注","start_offset": 0,"end_offset": 2,"type": "CN_WORD","position": 0},{"token": "我","start_offset": 2,"end_offset": 3,"type": "CN_CHAR","position": 1},{"token": "系统","start_offset": 3,"end_offset": 5,"type": "CN_WORD","position": 2},{"token": "学习","start_offset": 5,"end_offset": 7,"type": "CN_WORD","position": 3},{"token": "es","start_offset": 7,"end_offset": 9,"type": "ENGLISH","position": 4}]
}
建议:一般情况下,为了提高搜索的效果,需要这两种分词器配合使用。既建索引时用 ik_max_word 尽可能多的分词,而搜索时用 ik_smart 尽可能提高匹配准度,让用户的搜索尽可能的准确。比如一个常见的场景,就是搜索"进口红酒"的时候,尽可能的不要出现口红相关商品或者让口红不要排在前面。
在简单学习了解了Ik分词后,我们就可以去学习es的全文查询了。
二、数据准备
2.1 创建index
PUT /tehero_index
{"settings": {"index": {"number_of_shards": 1,"number_of_replicas": 1}},"mappings": {"_doc": {"dynamic": false,"properties": {"id": {"type": "integer"},"content": {"type": "keyword","fields": {"ik_max_analyzer": {"type": "text","analyzer": "ik_max_word","search_analyzer": "ik_max_word"},"ik_smart_analyzer": {"type": "text","analyzer": "ik_smart"}}},"createAt": {"type": "date"}}}}
}
简单解释下,content字段的映射:【就是一个字段配置多个分词器】
"content": {"type": "keyword", # 默认为 keyword类型"fields": {"ik_max_analyzer": { # 创建名为 ik_max_analyzer 的子字段"type": "text","analyzer": "ik_max_word", # 字段ik_max_analyzer 的倒排序索引分词器为ik_max_word"search_analyzer": "ik_max_word" # 检索关键词的分词器为ik_max_word},"ik_smart_analyzer": { # 创建名为 ik_smart_analyzer的子字段"type": "text","analyzer": "ik_smart" # 字段ik_smart_analyzer 的倒排序索引分词器为ik_smart# 字段ik_smart_analyzer 的检索关键词的分词器默认为ik_smart}}}
相比粗暴的用不同的字段去实现配置不同的分词器而言,一个字段配置多个分词器在数据的存储和操作上方便许多,只用储存一个字段,即可得到不同的分词效果。
三、Full text queries 之 match query(检索关键词会被分词)
3.1 match query:用于执行全文查询的标准查询,包括模糊匹配和短语或接近查询。
POST _bulk
{ "index" : { "_index" : "tehero_index", "_type" : "_doc", "_id" : "1" } }
{ "id" : 1,"content":"关注我,系统学编程" }
{ "index" : { "_index" : "tehero_index", "_type" : "_doc", "_id" : "2" } }
{ "id" : 2,"content":"系统学编程,就关注我" }
{ "index" : { "_index" : "tehero_index", "_type" : "_doc", "_id" : "3" } }
{ "id" : 3,"content":"系统学编程,求关注" }
# 1、发现查询不到结果
GET /tehero_index/_doc/_search
{"query":{"match":{"content":"系统学"}}
}
# 2、查询到id = 1 的文档
GET /tehero_index/_doc/_search
{"query":{"match":{"content":"关注我,系统学编程"}}
}
分析:【语句1】发现查询不到结果,此时content是keyword类型,是不会分词的,所以检索词需要和内容完全一样,【语句2】查询到文档1【keword与text的区别:ElasticSearch系列03:ES的数据类型】
# 1、会检索出所有结果
GET /tehero_index/_doc/_search
{"query":{"match":{"content.ik_max_analyzer":"系统学"}}
}
# 2、改变检索分词器为ik_smart,只能检索到 文档1和文档2
GET /tehero_index/_doc/_search
{"query":{"match":{"content.ik_max_analyzer" : {"query" : "系统学","analyzer": "ik_smart"}}}
}
分析:【语句1】能查询到所有文档,因为检索词根据ik_max_word分词,得到Token(系统、系统学)【语句2】的检索词根据ik_smart分词,只能得到Token(系统学),不能匹配上文档3。
可以自己执行以下的分词测试语句,查看分词效果:
GET /_analyze
{"text": ["系统学"],"analyzer": "ik_smart"
}
GET /_analyze
{"text": ["系统学"],"analyzer": "ik_max_word"
}
通过上面的例子,我想大家已经理解了【ik_max_word 和 ik_smart】两种分词方式在实际运用中的区别。下面就来看看match query的参数有哪些?都有什么作用?
# 1、不配置,使用默认值or,得到文档1和文档2
GET /tehero_index/_doc/_search
{"query": {"match": {"content.ik_smart_analyzer": {"query": "系统学es"}}}
}
# 2、and,查询不到结果
GET /tehero_index/_doc/_search
{"query": {"match": {"content.ik_smart_analyzer": {"query": "系统学es","operator":"and"}}}
}
分析:检索词“系统学es”被分词为【系统学、es】两个Token,【语句1】的operator默认值为or,所以文档1和2可以被检索到;【语句2】的operator的值是and,也就是需要同时包含【系统学、es】这两个Token才行,所以没有结果。
简单阅读即可:
POST _analyze
{
"analyzer": "stop",
"text": "to be or not to be"
}
那么就像 这种 字段中的 to be or not to be 这个短语中全部都是停顿词,一过滤,就什么也没有了,得不到任何 tokens, 那搜索时什么都搜不到。
zero_terms_query 就是为了解决这个问题而生的。它的默认值是 none ,就是搜不到停止词(对 stop 分析器字段而言),如果设置成 all ,它的效果就和 match_all 类似,就可以搜到了。
# id是integer类型,报错
GET /tehero_index/_doc/_search
{"query": {"match": {"id": {"query": "系统学"}}}
}
# 加上参数,不报错,语句正常执行
GET /tehero_index/_doc/_search
{"query": {"match": {"id": {"query": "系统学","lenient": "true"}}}
}
# 为可转换的字符串,也不报错,语句正常执行
GET /tehero_index/_doc/_search
{"query": {"match": {"id": {"query": "2"}}}
}
注意,如果将 id 字段的值设置为字符串 "2", 来查询,由于能够转换成整数,
这时 elastic 内部会将 字符串先转换成整数再做查询,不会报错。
ps:本想将 Full text queries 全部介绍完整的,但考虑篇幅过大,剩下的6种match查询明天再更新咯。【关注我,获取最新推送哟】
下期预告:Full text queries 【关注公众号:ZeroTeHero,系统学习ES】
待续
 ●ElasticSearch系列01:如何系统学习ES
●ElasticSearch系列01:如何系统学习ES
●ElasticSearch系列02:ES基础概念详解
●ElasticSearch系列03:ES的数据类型
●ElasticSearch系列04:索引和文档的CURD
●ElasticSearch系列05:倒排序索引与分词Analysis








 京公网安备 11010802041100号
京公网安备 11010802041100号