作者:我没资格我不配 | 来源:互联网 | 2023-08-19 17:13
作者:王歌
背景描述
现有集群部署在 EKS 上,使用 TiDB Operator 部署的 TiDB 集群
使用 spark 主要想实现以下功能:
- ETL(批处理数据,从 TiDB 读取数据进行加工,然后再写入到 TiDB )
- 加速 AP 查询
客户倾向于使用托管的 spark,在 AWS 上 Spark 有 3 种部署形式:emr serverless,EMR on EC2,EMR on EKS,考虑到 TiSpark 需要和 PD,TiKV 进行交互,使用 EMR on EKS 默认网络是连通的,以下的方案是基于 EMR on EKS 展开。
方案简介
- 在 EKS 上,已存在 TiDB Operator 部署的 TiDB 集群
- 启动 EMR on EKS 的集群访问并通过 EMR 注册 EKS 集群
- 自定义 docker 镜像
- 配置 spark pod 并启动任务
操作步骤
现有 TiDB 集群部署在 EKS 上
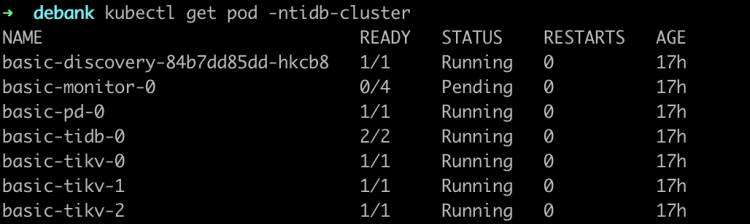
基于 EKS 部署 EMR
参考文档:https://docs.aws.amazon.com/zh_cn/emr/latest/EMR-on-EKS-DevelopmentGuide/setting-up-cli.html
暂时无法在飞书文档外展示此内容
运行 demo 之后,会自动创建 EMR 运行所需的 SA,如下:
tidb-cluster emr-containers-sa-spark-client-378955295993-189nnyj7mn9w2lqiewgg1u0l3jhmo0z69yjkj9u6qhosj8l 1 7s
tidb-cluster emr-containers-sa-spark-driver-378955295993-189nnyj7mn9w2lqiewgg1u0l3jhmo0z69yjkj9u6qhosj8l 1 6s
tidb-cluster emr-containers-sa-spark-executor-378955295993-189nnyj7mn9w2lqiewgg1u0l3jhmo0z69yjkj9u6qhosj8l 1 6s
需要为 emr-containers-sa-spark-driver 加上以下额外权限:
cat > spark-driver-access.yaml <kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
namespace: tidb-cluster
name: spark-driver-reader
rules:
- apiGroups: [""]
resources: ["services"]
verbs: ["get", "watch", "list", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "watch", "list", "delete"]
EOF
kubectl apply -f spark-driver-access.yaml
kubectl get sa -n tidb-cluster
kubectl create clusterrolebinding tispark-access \
--clusterrole=spark-driver-reader \
--serviceaccount=tidb-cluster:emr-containers-sa-spark-driver-XXXX
自定义 docker 镜像
参考文档:https://docs.aws.amazon.com/zh_cn/emr/latest/EMR-on-EKS-DevelopmentGuide/docker-custom-images-steps.html
Dockerfile 需要将 tispark 和 mysql-connector 的 jar 包放入到 spark 的 jars 目录下,参考:
注意 TiSpark 的版本需要和 spark 匹配,否则 job 会报错。(emr-6.7 对应的 spark 版本是 3.2.1-amzn-0)
cat > Dockerfile <FROM 059004520145.dkr.ecr.ap-northeast-1.amazonaws.com/spark/emr-6.7.0:latest
USER root
COPY tispark-assembly-3.2_2.12-3.1.1.jar /usr/lib/spark/jars/
COPY mysql-connector-java-8.0.27.jar /usr/lib/spark/jars/
USER hadoop:hadoop
EOF
配置 spark job
参考文档:https://www.eksworkshop.com/advanced/430_emr_on_eks/eks_emr_using_node_selectors/
创建节点组,并打上标签 dedicated: emr
cat newtidb.yaml
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: wg1
region: ap-northeast-1
availabilityZones: [&#x27;ap-northeast-1a&#x27;,&#x27;ap-northeast-1d&#x27;]
nodeGroups:
- name: emr
instanceType: m5.xlarge
desiredCapacity: 3
privateNetworking: true
availabilityZones: ["ap-northeast-1a"]
labels:
dedicated: emr
taints:
dedicated: emr:NoSchedule
eksctl create nodegroup -f newtidb.yaml
Spark pod 模板
将以下示例 pod 模板和 python 脚本上传到 s3 存储桶。
cat > spark_executor_nyc_taxi_template.yml <apiVersion: v1
kind: Pod
spec:
volumes:
- name: source-data-volume
emptyDir: {}
- name: metrics-files-volume
emptyDir: {}
nodeSelector:
dedicated: emr
tolerations:
- effect: NoSchedule
key: dedicated
operator: Equal
value: emr
containers:
- name: spark-kubernetes-executor
EOF
cat > spark_driver_nyc_taxi_template.yml <apiVersion: v1
kind: Pod
spec:
volumes:
- name: source-data-volume
emptyDir: {}
- name: metrics-files-volume
emptyDir: {}
nodeSelector:
dedicated: emr
tolerations:
- effect: NoSchedule
key: dedicated
operator: Equal
value: emr
containers:
- name: spark-kubernetes-driver
EOF
以下是 spark+jdbc 的方式读取 TiDB
暂时无法在飞书文档外展示此内容
以下是 TiSpark 读取 TiKV 并将数据写入到 TiDB 中
暂时无法在飞书文档外展示此内容
创建 spark job
aws emr-containers start-job-run
cat > request-nytaxi.json <{
"name": "nytaxi",
"virtualClusterId": "${VIRTUAL_CLUSTER_ID}",
"executionRoleArn": "${EMR_ROLE_ARN}",
"releaseLabel": "emr-6.7.0-latest",
"jobDriver": {
"sparkSubmitJobDriver": {
"entryPoint": "${s3DemoBucket}/nytaxi.py",
"sparkSubmitParameters": "
}
},
"configurationOverrides": {
"applicationConfiguration": [
{
"classification": "spark-defaults",
"properties": {
"spark.kubernetes.container.image": "自定义镜像的地址",
"spark.dynamicAllocation.enabled": "false",
"spark.kubernetes.executor.deleteOnTermination": "true",
"spark.tispark.pd.addresses": "pd-ip:port",
"spark.sql.extensions": "org.apache.spark.sql.TiExtensions",
"spark.sql.catalog.tidb_catalog": "org.apache.spark.sql.catalyst.catalog.TiCatalog",
"spark.sql.catalog.tidb_catalog.pd.addresses": "pd-ip:port"
}
}
],
"monitoringConfiguration": {
"cloudWatchMonitoringConfiguration": {
"logGroupName": "/emr-on-eks/eksworkshop-eksctl",
"logStreamNamePrefix": "nytaxi"
},
"s3MonitoringConfiguration": {
"logUri": "${s3DemoBucket}/"
}
}
}
}
EOF
查看 job 运行是否成功


附录
TiSpark 下载:https://github.com/pingcap/tispark/releases
TiSpark 使用:https://github.com/pingcap/tispark/blob/master/docs/userguide_3.0.md
PySpark 使用:https://github.com/pingcap/tispark/wiki/PySpark#%E4%BD%95%E6%97%B6%E4%BD%BF%E7%94%A8-pytispark
版权声明:本文为 TiDB 社区用户原创文章,遵循 CC BY-NC-SA 4.0 版权协议,转载请附上原文出处链接和本声明。
https://tidb.net/blog/2e5d1981






 京公网安备 11010802041100号
京公网安备 11010802041100号