ELK技术栈介绍
ELKStack 是 Elasticsearch、Logstash、Kibana 三个开源软件的组合。在实时数据检索和分析场合,三者通常是配合共用,而且又都先后归于 Elastic.co 公司名下,故有此简称。
ELKStack 在最近两年迅速崛起,成为机器数据分析,或者说实时日志处理领域,开源界的第一选择。和传统的日志处理方案相比,ELK Stack 具有如下几个优点:
处理方式灵活。Elasticsearch 是实时全文索引,不需要像storm 那样预先编程才能使用;
配置简易上手。Elasticsearch 全部采用 JSON 接口,Logstash 是 Ruby DSL 设计,都是目前业界最通用的配置语法设计;
检索性能高效。虽然每次查询都是实时计算,但是优秀的设计和实现基本可以达到全天数据查询的秒级响应;
集群线性扩展。不管是 Elasticsearch 集群还是 Logstash 集群都是可以线性扩展的;
前端操作炫丽。Kibana 界面上,只需要点击鼠标,就可以完成搜索、聚合功能,生成炫丽的仪表板。
当然,ELK Stack 也并不是实时数据分析界的灵丹妙药。在不恰当的场景,反而会事倍功半。我自 2014 年初开 QQ 群交流 ELK Stack,发现网友们对 ELKStack 的原理概念,常有误解误用;对实现的效果,又多有不能理解或者过多期望而失望之处。更令我惊奇的是,网友们广泛分布在传统企业和互联网公司、开发和运维领域、Linux 和 Windows 平台,大家对非专精领域的知识,一般都缺乏了解,这也成为使用 ELK Stack 时的一个障碍。
https://www.elastic.co/products/logstash#
Logstash是一款轻量级的日志搜集处理框架,可以方便的把分散的、多样化的日志搜集起来,并进行自定义的处理,然后传输到指定的位置,比如某个服务器或者文件。
下载后直接解压,就可以了。
通过命令行,进入到logstash/bin目录,执行下面的命令:
logstash -e ""
可以看到提示下面信息(这个命令稍后介绍),输入hello world!
可以看到logstash尾我们自动添加了几个字段,时间戳@timestamp,版本@version,输入的类型type,以及主机名host。
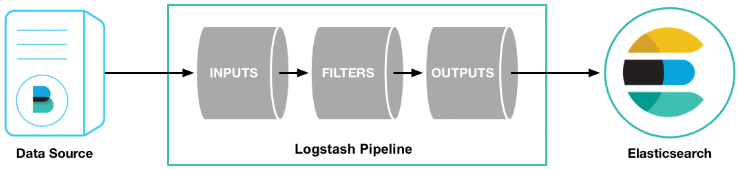
Logstash使用管道方式进行日志的搜集处理和输出。有点类似*NIX系统的管道命令 xxx | ccc | ddd,xxx执行完了会执行ccc,然后执行ddd。
在logstash中,包括了三个阶段:
输入input --> 处理filter(不是必须的) -->输出output
每个阶段都由很多的插件配合工作,比如file、elasticsearch、redis等等。
每个阶段也可以指定多种方式,比如输出既可以输出到elasticsearch中,也可以指定到stdout在控制台打印。
由于这种插件式的组织方式,使得logstash变得易于扩展和定制。
-f:通过这个命令可以指定Logstash的配置文件,根据配置文件配置logstash
-e:后面跟着字符串,该字符串可以被当做logstash的配置(如果是“” 则默认使用stdin作为输入,stdout作为输出)
-l:日志输出的地址(默认就是stdout直接在控制台中输出)
-t:测试配置文件是否正确,然后退出。
前面介绍过logstash基本上由三部分组成,input、output以及用户需要才添加的filter,因此标准的配置文件格式如下:
input {...}
filter {...}
output {...}
在每个部分中,也可以指定多个访问方式,例如我想要指定两个日志来源文件,则可以这样写:
input {
file { path =>"/var/log/messages" type =>"syslog"}
file { path =>"/var/log/apache/access.log" type =>"apache"}
}
类似的,如果在filter中添加了多种处理规则,则按照它的顺序一一处理,但是有一些插件并不是线程安全的。
比如在filter中指定了两个一样的的插件,这两个任务并不能保证准确的按顺序执行,因此官方也推荐避免在filter中重复使用插件。
说完这些,简单的创建一个配置文件的小例子看看:
file {
#指定监听的文件路径,注意必须是绝对路径
path => "E:/software/logstash-1.5.4/logstash-1.5.4/data/test.log"
start_position => beginning
filter {
output {
stdout {}
日志大致如下:注意最后有一个空行。
1 hello,this is first line in test.log!
2 hello,my name is xingoo!
3 goodbye.this is last line in test.log!
4
执行命令得到如下信息:
这个插件可以从指定的目录或者文件读取内容,输入到管道处理,也算是logstash的核心插件了,大多数的使用场景都会用到这个插件,因此这里详细讲述下各个参数的含义与使用。
在Logstash中可以在 input{} 里面添加file配置,默认的最小化配置如下:
path => "E:/software/logstash-1.5.4/logstash-1.5.4/data/*"
当然也可以监听多个目标文件:
path => ["E:/software/logstash-1.5.4/logstash-1.5.4/data/*","F:/test.txt"]
另外,处理path这个必须的项外,file还提供了很多其他的属性:
#监听文件的路径
#排除不想监听的文件
exclude => "1.log"
#添加自定义的字段
add_field => {"test"=>"test"}
#增加标签
tags => "tag1"
#设置新事件的标志
delimiter => "\n"
#设置多长时间扫描目录,发现新文件
discover_interval => 15
#设置多长时间检测文件是否修改
stat_interval => 1
#监听文件的起始位置,默认是end
#监听文件读取信息记录的位置
sincedb_path => "E:/software/logstash-1.5.4/logstash-1.5.4/test.txt"
#设置多长时间会写入读取的位置信息
sincedb_write_interval => 15
其中值得注意的是:
1 path
是必须的选项,每一个file配置,都至少有一个path
2 exclude
是不想监听的文件,logstash会自动忽略该文件的监听。配置的规则与path类似,支持字符串或者数组,但是要求必须是绝对路径。
3start_position
是监听的位置,默认是end,即一个文件如果没有记录它的读取信息,则从文件的末尾开始读取,也就是说,仅仅读取新添加的内容。对于一些更新的日志类型的监听,通常直接使用end就可以了;相反,beginning就会从一个文件的头开始读取。但是如果记录过文件的读取信息,这个配置也就失去作用了。
4sincedb_path
这个选项配置了默认的读取文件信息记录在哪个文件中,默认是按照文件的inode等信息自动生成。其中记录了inode、主设备号、次设备号以及读取的位置。因此,如果一个文件仅仅是重命名,那么它的inode以及其他信息就不会改变,因此也不会重新读取文件的任何信息。类似的,如果复制了一个文件,就相当于创建了一个新的inode,如果监听的是一个目录,就会读取该文件的所有信息。
5 其他的关于扫描和检测的时间,按照默认的来就好了,如果频繁创建新的文件,想要快速监听,那么可以考虑缩短检测的时间。
6add_field
就是增加一个字段,例如:
path => "D:/tools/logstash/path/to/groksample.log"
基于Logstash跑通Kafka还是需要注意很多东西,最重要的就是理解Kafka的原理。
由于Kafka采用解耦的设计思想,并非原始的发布订阅,生产者负责产生消息,直接推送给消费者。而是在中间加入持久化层——broker,生产者把数据存放在broker中,消费者从broker中取数据。这样就带来了几个好处:
1 生产者的负载与消费者的负载解耦
2 消费者按照自己的能力fetch数据
3 消费者可以自定义消费的数量
另外,由于broker采用了主题topic-->分区的思想,使得某个分区内部的顺序可以保证有序性,但是分区间的数据不保证有序性。这样,消费者可以以分区为单位,自定义读取的位置——offset。
Kafka采用zookeeper作为管理,记录了producer到broker的信息,以及consumer与broker中partition的对应关系。因此,生产者可以直接把数据传递给broker,broker通过zookeeper进行leader-->followers的选举管理;消费者通过zookeeper保存读取的位置offset以及读取的topic的partition分区信息。
由于上面的架构设计,使得生产者与broker相连;消费者与zookeeper相连。有了这样的对应关系,就容易部署logstash-->kafka-->logstash的方案了。
接下来,按照下面的步骤就可以实现logstash与kafka的对接了。
启动zookeeper:
$zookeeper/bin/zkServer.sh start
启动kafka:
$kafka/bin/kafka-server-start.sh $kafka/config/server.properties&
创建主题:
$kafka/bin/kafka-topics.sh --zookeeper 127.0.0.1:2181--create --topic hello --replication-factor 1--partitions 1
查看主题:
$kafka/bin/kafka-topics.sh --zookeeper127.0.0.1:2181 --describe
执行生产者脚本:
$kafka/bin/kafka-console-producer.sh --broker-list 10.0.67.101:9092 --topic hello
执行消费者脚本,查看是否写入:
$kafka/bin/kafka-console-consumer.sh--zookeeper 127.0.0.1:2181 --from-beginning--topic hello
input{
stdin{}
output{
kafka{
topic_id => "hello"
bootstrap_servers => "192.168.0.4:9092,172.16.0.12:9092"
# kafka的地址
batch_size => 5
codec => plain {
format => "%{message}"
charset => "UTF-8"
stdout{
codec => rubydebug
logstash配置文件:
kafka {
codec => "plain"
group_id => "logstash1"
auto_offset_reset => "smallest"
reset_beginning => true
zk_connect => "192.168.0.5:2181"

















 京公网安备 11010802041100号
京公网安备 11010802041100号