EFK 是ELK 日志分析的一个变种,能够更好的来实现日志分析。
首先我们先准备3台 centos7的服务器,在给他们调成2核2G的状态打开。
| 软件 |
版本号 |
| zookeeper |
3.4.14 |
| Kafka |
2.2.0 |
| logstash |
6.6.0 |
| elasticsearch |
6.6.2 |
| jdk |
jdk-8u131-linux-x64_.rpm |
| kibana |
6.6.2 |
我的三台服务器分别为
192.168.153.171 安装了jdk,zookeeper,kafka,filebeat,nginx
192.168.153.172 安装了jdk,zookeeper,kafka,logstash
192.168.153.173 安装了jdk,zookeeper,kafka,elasticsearch,kibana
1 . 首先我们先在每台服务器上安装jdk
cd /usr/local/src
rpm -ivh jdk-8u131-linux-x64_.rpm
2 . 关闭防火墙和selinux
systemctl stop firewalld
setenforce 0
3 . 上传需要使用的安装包到/usr/local/src下
cd /usr/local/src
rz (zookeeper,kafka)
4 . 解压zookeeper,kafka 到/usr/local/下
tar zxf zookeeper-3.4.14.tar.gz
tar zxf kafka_2.11-2.2.0.tgz
mv kafka_2.11-2.2.0 /usr/local/kafka
mv zookeeper-3.4.14 /usr/local/zookeeper
5 . 进入 /usr/local/zookeeper
mkdir {zkdata,zkdatalog}
进入/usr/local/zookeeper/conf/
cp zoo_sample.cfg zoo.cfg
6 . 编辑zoo.cfg
vim zoo.cfg
--------------------------------------------------------
tickTime=2000 //zookeeper服务器之间的心跳时间
initLimit=10 //zookeeper的最大链接失败时间
syncLimit=5 //zookeeper的同步通信时间
dataDir=/usr/local/zookeeper/zkdata //zookeeper的存放快照日志的绝对路径
dataLogDir=/usr/local/zookeeper/zkdatalog //zookeeper的存放事物日志的绝对路径
clientPort=2181 //zookeeper与客户端建立连接的端口
server.1=192.168.153.171:2888:3888 //服务器及其编号,服务器IP地址,通信端口,选举端口
server.2=192.168.153.172:2888:3888
server.3=192.168.153.173:2888:3888
----------------------------------------------------------
7 . 在每台机器上写上自己的id
echo ‘1/2/3‘ > /usr/local/zookeeper/zkdata/myid
我写的是171为1 172为2 173为3
8 . 开启zookeeper服务
cd /usr/local/zookeeper/bin/
./zkServer.sh start
./zkServer.sh status //Mode: leader为主节点,Mode: follower为从节点,zk集群一般只有一个leader,多个follower,主一般是响应客户端的读写请求,而从主同步数据,当主挂掉之后就会从follower里投票选举一个leader出来。
如果查看状态时为error 我们看一下端口起没起来,zookeeper开启时的顺序是( 1 2 3 ),把 /usr/local/zookeeper/zkdata 下的文件删除,只保留一个我们设置的myid,在进行重启
到此为止 zookeeper 配置完成
搭建kafka
1 . 编辑kafka的配置文件
第一台
cd /usr/local/kafka/config
vim server.properties
*********************
broker.id=1
advertised.listeners=PLAINTEXT://kafka01:9092
zookeeper.cOnnect=192.168.153.171:2181,192.168.153.172:2181,192.168.153.173:2181 (三台服务器的IP地址)
第2台
cd /usr/local/kafka/config
vim server.properties
*********************
broker.id=2
advertised.listeners=PLAINTEXT://kafka02:9092
zookeeper.cOnnect=192.168.153.171:2181,192.168.153.172:2181,192.168.153.173:2181 (三台服务器的IP地址)
第3台
cd /usr/local/kafka/config
vim server.properties
*********************
broker.id=3
advertised.listeners=PLAINTEXT://kafka03:9092
zookeeper.cOnnect=192.168.153.171:2181,192.168.153.172:2181,192.168.153.173:2181 (三台服务器的IP地址)
2 . vim /etc/hosts
192.168.153.171 kafka01
192.168.153.172 kafka02
192.168.153.173 kafka03
3 . 每一台服务器都要启动kafka
cd /usr/local/kafka/bin
./kafka-server-start.sh -daemon ../config/server.properties // 以后台模式启动kafka
4 . 启动之后查看端口是否成功启动
5 . 创建主题topics
cd /usr/local/kafka/bin
./kafka-topics.sh --create --zookeeper 192.168.153.171:2181 --replication-factor 2 --partitions 3 --topic wg007 //因为我只做第一台服务器的日志收集,所以我的IP地址为第一台的
6 . 查看主题 如果可以显示出我们所创建的topics 就代表我们创建成功了

7 . 模拟生产者 执行代码之后就会有一个>
cd /usr/local/kafka/bin
./kafka-console-producer.sh --broker-list 192.168.153.171:9092 --topic wg007
>
>
在第二台上模拟消费者
/usr/local/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.153.172:9092 --topic wg007 --from-beginning //可以在任意服务器上执行
写一个脚本用来创建kafka的topic
cd /usr/local/kafka/bin
vim kafka-create-topics.sh
#################################
#!/bin/bash
read -p "请输入一个你想要创建的topic:" topic
cd /usr/local/kafka/bin
./kafka-topics.sh --create --zookeeper 192.168.153.171:2181 --replication-factor 2 --partitions 3 --topic ${topic}
创建一个新的yum源
vim /etc/yum.repo.d/filebeat.repo
***加入以下内容
[filebeat-6.x]
name=Elasticsearch repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
安装filebeat
编辑filebeat的配置文件
cd /etc/filebeat
vim filebeat.yml
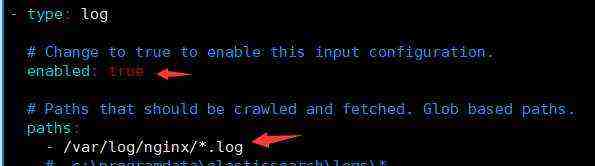
修改以下内容
enabled: true
paths:
- /var/log/nginx/*.log //写这个路径的前提是安装nginx
output.kafka:
enabled: true
# Array of hosts to connect to.
hosts: ["192.168.153.171:9092","192.168.153.172:9092","192.168.153.173:9092"]
topic: nginx1 //写这个nginx1 的前提是有nginx1的topic 上面有生产者的脚本
安装nginx
yum -y install epel*
yum -y install nginx
启动nginx和filebeat
systemctl start filebeat
systemctl enable filebeat
systemctl start nginx
可以给ningx生产一些数据
yum -y install httpd-tools
ab -n1000 -c 200 http://127.0.0.1/cccc //这条命令可以多执行几次
-----------------------------------------------------------------
curl -I 192.168.18.140:80
然后再检验看日志是否可以同步
现在开始收集多个日志 system nginx secure 和日志 编辑filebeat的配置文件
#讲filebeat的input改成下面的样子
filebeat.inputs:
#这个是收集nginx的日志
- type: log
enabled: true
paths:
- /var/log/nginx/*.log //nginx的日志文件
fields:
log_topics: nginx1 //这个是收集nginx的topic
#这个是收集system的日志
- type: log
enabled: true
paths:
- /var/log/messages //system的日志文件目录
fields:
log_topics: messages //这个是收集system的topic
#收集secure的日志
- type: log
enabled: true
paths:
- /var/log/secure //secure的日志文件
fields:
log_topics: secure //这个是收集secure的topic
output.kafka:
enabled: true
hosts: ["192.168.153.171:9092","192.168.153.172:9092","192.168.153.173:9092"]
topic: ‘%{[fields][log_topics]}‘
注意:一点更要创建三个topic 就是上面的配置文件提到的topic 可以使用上面的脚本创建topic 重启filebeat
systemctl restart filebeat
接下来在第二台安装logstash 在第三台安装ES集群(就是elasticsearch和kibana)
EFK的搭建(未完成)




![Spark中使用map或flatMap将DataSet[A]转换为DataSet[B]时Schema变为Binary的问题及解决方案](https://img6.php1.cn/3cdc5/9b0d/243/f27d40b3b7e4b51b.png)


 京公网安备 11010802041100号
京公网安备 11010802041100号