作者: | 来源:互联网 | 2023-09-23 11:56
作者:张楚珩
链接:https://zhuanlan.zhihu.com/p/51091244
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
中Distral是Distill & transfer learning的缩写。
原文传送门
Teh, Yee, et al. "Distral: Robust multitask reinforcement learning." Advances in Neural Information Processing Systems. 2017.
特色
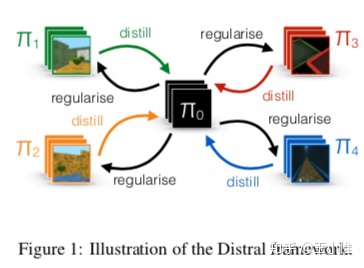
提出了一种同时在多个任务上训练的强化学习方法,主要的想法是把各个任务上学到的策略进行提纯(distill,本意是蒸馏)得到一个共有的策略,然后再使用这个共有的策略去指导各个特定任务上的策略进行更好的学习。文章称,这种多任务的强化学习方法避免了不同任务产生互斥的梯度,反而干扰学习;同时,也避免了各个任务学习进度不一致,导致某个任务的学习主导了整体的学习。个人感觉,这种各个任务间提纯的方法也说不定能用到多智能体间的相互交互上。
背景
为什么要做多任务学习?需要过多的交互(采样)是目前强化学习的一大重要问题,这阻碍了强化学习应用到模拟环境以外的其他地方。如果能通过进行多任务学习让智能体学习到一些共有的知识,这样在一个新环境下就能通过少量样本学习到好的策略了,这样就相当于从另一个角度降低了学习算法所需要的样本。
过程
- 大致思想
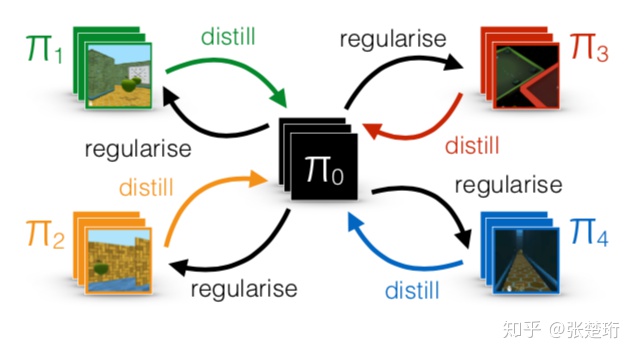
在各个环境各自学习各自策略的基础上建立一个中间的策略 ![[公式]](https://img2.php1.cn/3cdc5/3984/882/c22e2cfc216e7066) ,各个策略进行学习的时候会在中间策略的正则下来学习,而各个不同的策略综合起来由提纯得到这个中间策略。
,各个策略进行学习的时候会在中间策略的正则下来学习,而各个不同的策略综合起来由提纯得到这个中间策略。
2. 目标函数
考虑多个任务 (这里的 既表示任务,也表示任务下相应的策略)和由这些策略提纯得到的策略 。
设定如下的最大化目标
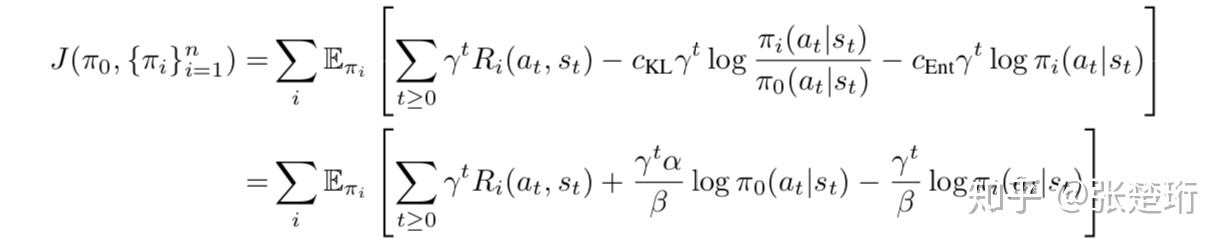
即主要约束了各个策略 不要偏离中心策略 太远,同时再加上了entropy项以鼓励探索。
3. 优化方式
文章讨论了两种优化方式,一种是联合优化,一种是交替优化。前一种就是每次都对所有的策略 的参数化表示做SGD;后一种就是每次固定一个训练另一个,即固定 优化 ,再固定 优化 。在后一种情况下,第一步可以使用和已有的soft Q-learning一样的实现,第二步可以使用和已有的一些distillation方法已有的实现,实践上这两者已经是稳定的了。
固定 的时候,我们可以定义一个正则化的奖励
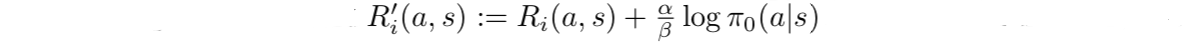
这样问题就变成了一个附加entropy项的单任务强化学习问题了,使用Soft Q-learning的框架(不熟悉的可以参考本专栏的文章【强化学习算法 10】SQL)就是学习这样的任务(红色删除线应为 ,文章打印错误)
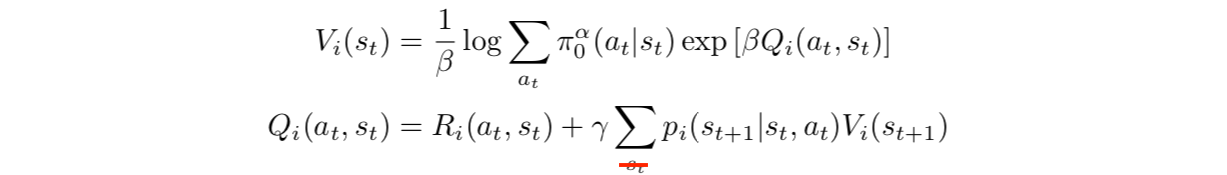
它相当于是以 为先验来学习的,这是一个比 更为鼓励探索的一个先验, 的作用后面会再提到。相应的Boltzmann策略是
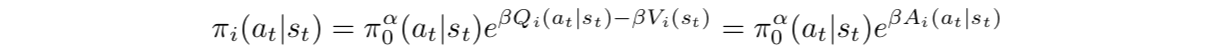
固定 的时候,目标函数里面只有一项与 相关
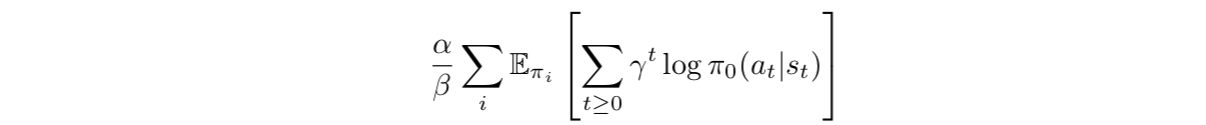
可以使用maximum likelihood estimator或者对目标函数做SGD得到,这就是一个distillation的过程。
4. 策略的表示
一种自然的策略表示方法是都采用Boltzmann策略的表示方法
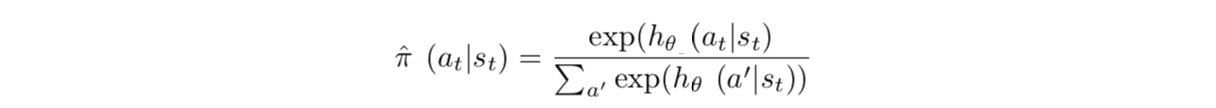
不过文中还提出了另一种更好的方法,即各个特定的策略 表示为与 共有的部分和其自己特有部分的加和,这样各个特定策略学习过程中就只需要集中精力学习自己特有的部分了。
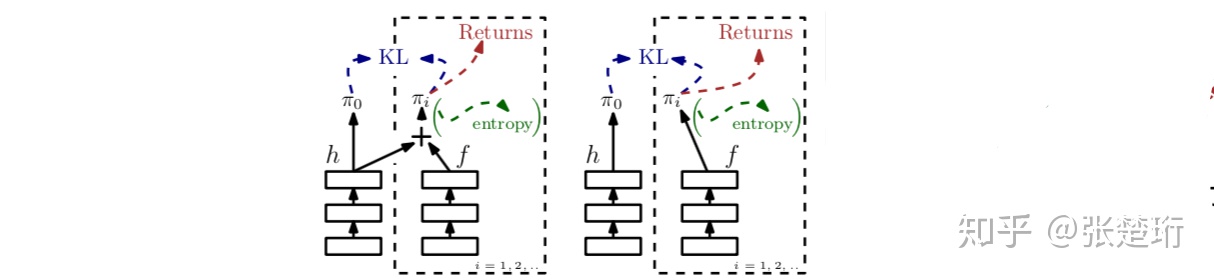
左边是文中提到的更好的一种表示方式,右边是各自表示各自的
中心策略 使用一个神经网络 来表示
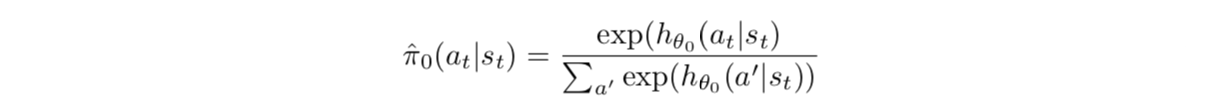
特定的策略 使用使用中心策略的神经网络 和各自的神经网络 来表示
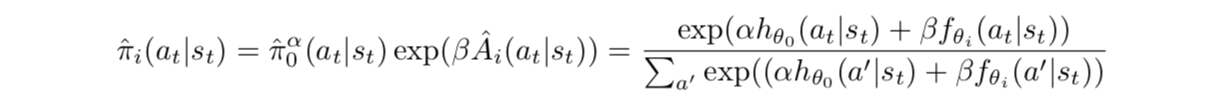
注意到这就是一个以 为先验的Boltzmann策略,其中advantage使用的是soft advantage
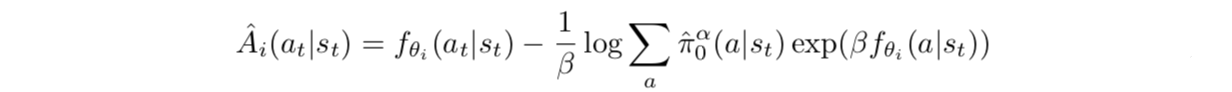
在这种表示方法下就可以自然使用策略梯度方法进行联合优化
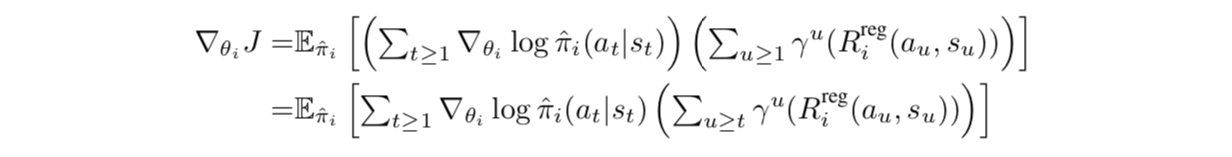
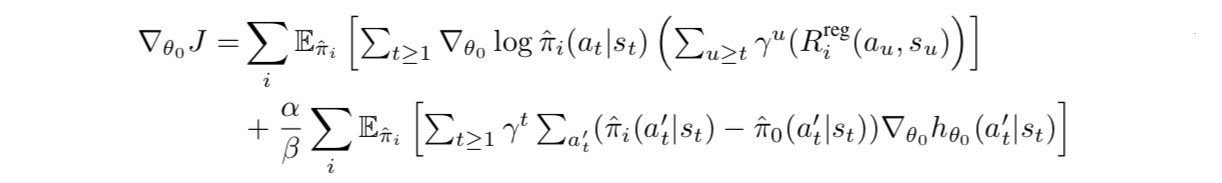
其中正则化的奖励为
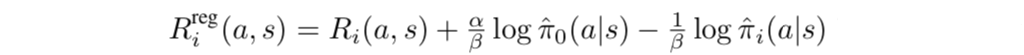
5. 的选择
下面考虑优化目标里面 不同数值带来的不同含义
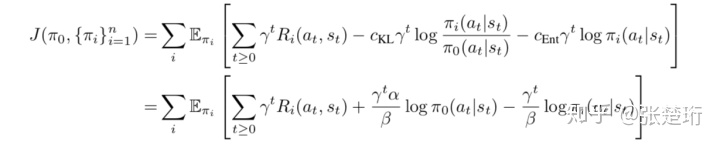
- 的时候就等于没有中心策略,即每个任务各学各的;
- 的时候相当于在最大化cumulated discounted return的同时,还需要最小化一个 项;当 的时候, 项为零,这时候相当于 在找一个在这个任务上的greedy策略;
- 的时候在最小化KL项的同时,还要最小化 ,这相当于附加了激励各个策略 不要局限在中心策略附加,鼓励了相对于中心策略的探索。
实验
根据前面提到的目标的不同(选择不同的 )、优化方式的不同(是分别优化还是联合优化)以及结构的不同( 的表示是否使用中心策略),文章做了以下的7个实验组。
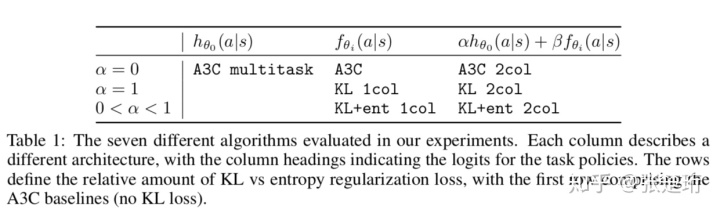
根据目标、优化方法、参数化策略结构不同产生的7个实验组算法
实验主要在一个简单的世界任务和3D的第一人称迷宫任务上做的。个人感觉有如下几个点
- 多个任务联合起来学习可以使得单个任务的渐进性能都稍微好一点点,这一点说明中心策略 确实还是代表了一些共有的知识。(不然,搞了这么一通不如单独每个任务去训练)
- 格子世界任务选择了一个具有长长走廊的格子世界,中心策略的主要优势就体现在这个走廊上,实验结果表明,使用了中心策略之后,智能体能够快速地朝一个方向通过这个走廊,以此证明这种算法不会产生相互冲突的中心策略更新;但是个人认为其主要原因是这里的state选择并不仅仅是所处的格子,还包括了上一步的行动,正是这样状态空间的选择导致了不会产生相互冲突的中心策略。
- 就相对于超参数的稳定性来说,KL+ent 2col算法(即使用 和相互耦合的策略表示)具有最好的稳定性。
- 如果学习相对独立的策略,还是不要使用相互耦合的策略表示(即1col)更好。
作者:王小惟
链接:https://zhuanlan.zhihu.com/p/70127847
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2017-NIPS-Distral: Robust Multitask Reinforcement Learning
Distral (Distill & transfer learning)。简而言之,之前的multitask或多或少都是希望通过参数共享来加快学习(比如对于图片的特征提取层)。但是在实际中,由于任务之间的梯度方向可能会互相干扰,同时不同任务的reward尺度(observation的数值尺度)会不一样大,这就进一步限制了parameter weight的大小,同样也会出现梯度大小等不同的情况等等。既然共享参数会存在这样一系列的问题,这里采用了另外的一套框架,即在每个任务中学习特定的policy,然后在学习过程中进行knowledge的共享。即:将这些policy都蒸馏到一个中心的policy 中,同时也利用这个 来对特定的任务下的policy做正则化来进行约束(感觉就是knowledge transfer过去)。
在训练特定任务时,policy最大化环境的累积收益,同时加上对于 的KL散度来做约束,还有相应的entropy正则来鼓励探索。
在训练中心式的policy,就是对于其他所有特定任务的策略的KL散度的最小化。
更近一步,这边提了一下不同的训练方式,比如一起训练,间隔训练等,具体就去看paper即可。








 京公网安备 11010802041100号
京公网安备 11010802041100号