作者:May蕊心 | 来源:互联网 | 2023-05-19 00:02
大数据的概念大数据(bigdata),指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多
大数据的概念
大数据(big data),指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。

主要解决:海量数据存储和海量数据的分析计算问题
大数据的特点
大数据特性,谨记四字箴言:「大、快、杂、疑」
1、Volume(大)
资料量非常大,以前人们「手动」在表格中记录、累积出数据;现在数据是由机器、网路、人与人之间的社群互动来生成。你现在正在点击的滑鼠、来电、简讯、网路搜寻、线上交易… 都正在生成累积成庞大的数据。截止目前人类生产的所有印刷材料是200PB(Peta Bytes,千兆位元组),历史上人类总共说过的话数据量约5EB(Exabytes,百万兆位元组)。
2、Velocity(快)
响应的时效性至关重要,据IDC“数字宇宙”报告,预计到2020年,全球数据使用量将达到35.2ZB(Zetta Bytes,十万亿亿字节),如此海量数据,处理效率至关重要。
3、Variety(杂)
大数据的来源种类包罗万象,十分多样化,如果一定要把资料分类的话,最简单的方法是分两类,结构化与非结构化。早期的非结构化资料主要是文字,随着网路的发展,又扩展到电子邮件、网页、社交媒体、视讯,音乐、图片等等,这些非结构化的资料造成储存(storage)、探勘(mining)、分析(analyzing)上的困难。
4、Value(疑)
价值密度的高低与数据总量的大小成反比。以视频为例,一部1小时的视频,在连续不间断的监控中,有用数据可能仅有一二秒。如何通过强大的机器算法更迅速地完成数据的价值“提纯”成为目前大数据背景下亟待解决的难题。
大数据能干啥?
例1: o2o–百度大数据+平台,通过先进的线上线下打通技术和客流分析能力,助力商家精细化运营,提升销量。

例2: 美国折扣零售商能够通过用户购买商品的历史,判断出是否怀孕。
例3: 日本通过研究驾驶员的坐姿数据,用来作为汽车防盗系统中。

例4: 电子商务领域–购物行为与销量预测分析;商品关联分析;全网产品信息采集,产品素材获取;通过分析产品价格和销量,指导新品上架策略;云评论系统的搭建和维护;电子商务渠道分销 。

例5: 金融领域–金融行业的主要业务应用包括企业内外部的风险管理、信用评估、借 贷、保 险、理 财、证 券分析等,都可以通过获取、关联和分析更多维度、更深层次的数据,并通过不断发展的大数据处理技术得以更好、更快、更准确的实现,从而使得原来不可担保的信 贷可以担保,不可保 险的风险可以保 险,不可预测的证 券行情可以预测。

例6: 电信领域–采集基站等硬件设备的数据,分析设备负荷状况,生成设备的扩容、优化、质量排查、扩建等建议,达到均衡网络流量的目的;分析用户的话单数据,界定用户属性,分析手机终端的特征,从而形成套餐推荐、终端推荐等决策;根据用户使用的app软件、访问的网页进行更为全面的用户行为分析、用户喜好分析;采集微博等社交网络数据,了解用户对运营商的评价和意见,舆情分析。

例7: 新闻媒体–快速准确地自动跟踪、采集数千家网络媒体信息,扩大新闻线索,提高采集速度;支持每天对数万条新闻进行有效抓取。监控范围的深度、广度可以自行设定;支持对所需内容的智能提取、审核;实现互联网信息内容采集、浏览、编辑、管理、发布的一体化。

例8: 政府机关–大数据必将成为宏观调控、国家治理、社会管理的信息基础。实时跟踪、采集与业务工作相关的信息;全面满足内部工作人员对互联网信息的全局观测需求;及时解决政务外网、政务内网的信息源问题,实现动态发布;快速解决政府主网站对各地级子网站的信息获取需求;全面整合信息,实现政府内部跨地区、跨部门的信息资源共享与有效沟通;节约信息采集的人力、物力、时间,提高办公效率。

例9: 企业制造–实时准确地监控、追踪竞争对手动态,是企业获取竞争情报的利器;及时获取竞争对手的公开信息以便研究同行业的发展与市场需求;为企业决策部门和管理层提供便捷、多途径的企业战略决策工具;大幅度地提高企业获取、利用情报的效率,节省情报信息收集、存储、挖掘的相关费用,是提高企业核心竞争力的关键;提高企业整体分析研究能力、市场快速反应能力,建立起以知识管理为核心的“竞争情报数据仓库”,提高核心竞争力。
大数据前景
1、国际数据公司IDC预测,到2020年,企业基于大数据计算分析平台的指出将突破5000亿美元。目前,我国大数据人才只有46万,未来3到5年人才缺口达到150万之多。

2、2017年北京大学,北京邮电大学等25所高校成功申请开设大数据课程。

3、大数据属于高新技术,大牛少,升职竞争小;
大数据技术生态体系
总共分为六层:数据来源层–>数据来源层–>数据存储层–>资源管理层–>数据计算层–>任务调度层
具体如下图:

下面我们来讲一下上面的架构图:
首先我们第一步当然是获取数据【数据来源层】,包括(结构化,半结构化,非架构话数据),然后我们需要去接收数据【数据来源层】。
不同的数据类型有不同的接收工具:

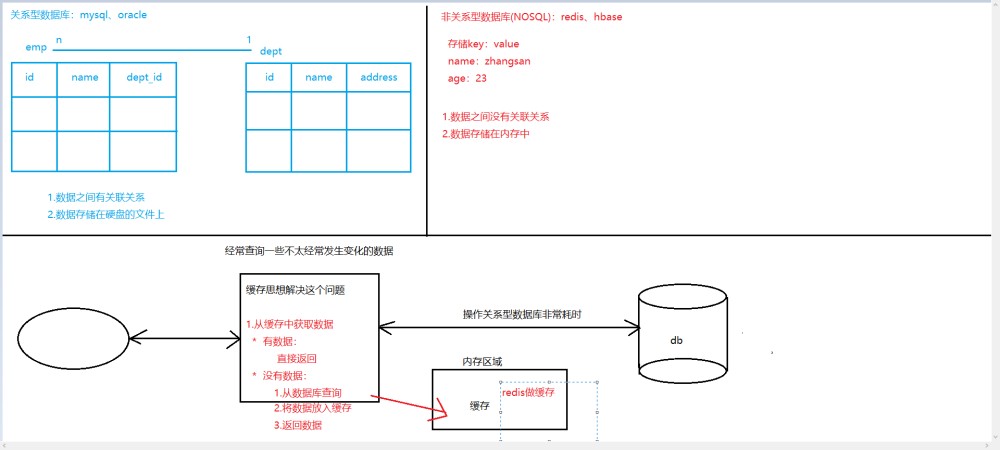
- Sqoop(发音:skup)主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql…)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
- Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
接收过后,当然是存储起来,可以存储在HDFS上也可以存储在Hbase。Hbase是按列存储,检索起来特别快。Hadoop HDFS为HBase提供了高可靠性的底层存储支持。
- Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。HDFS在最开始是作为Apache Nutch搜索引擎项目的基础架构而开发的。HDFS是Apache Hadoop Core项目的一部分。
- HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
数据存储完毕,到了我们YARN资源管理层,YARN资源管理层相当于我们电脑的操作系统,调度这些资源,HDFS相当于磁盘。
- Apache Hadoop YARN (Yet Another Resource Negotiator,另一种资源协调者)是一种新的 Hadoop 资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
再往上到了我们数据计算层,

从图中可以看出左侧是处理离线的数据,右侧是处理实时数据。
离线又分为两类:
MapReduce是基于磁盘计算,Spark Core是基于内存计算。
MapReduce断电后数据还在,Spark Core断电后数据不存在。
Spark Core比MapReduce速度快。
- MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念”Map(映射)”和”Reduce(归约)”,是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
到最后一步就是调度层,说白了就是安排什么时间做什么事。
- azkaban主要是应用于hadoop生态圈的任务调度的。我们在实际使用过程中,也主要是用来做hadoop相关任务的调度,其他任务的调度暂时还没有进行相关实践。
- ozie是管理Hadoop作业的工作流调度系统,工作流是一系列的操作图。Oozie协调作业是通过时间(频率)以及有效数据触发当前的Oozie工作流程。Oozie是针对Hadoop开发的开源工作流引擎,专门针对大规模复杂工作流程和数据管道设计。
推荐系统项目框架
接下来来个实战框架:
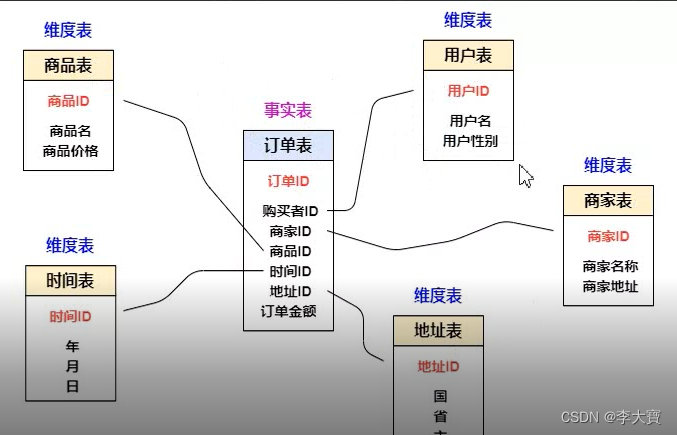
例如我们在淘宝买了个键盘,那么你会发现当你买完键盘的时候,会给你推荐鼠标,显示器等相关商品,那么这个就是通过上面我们讲到的数据框架实现的。

购买完键盘通过Nginx来让Tomcat收集日志,然后通过我们的数据系统将日志存储到HDFS或Hbase,由于我们这个是实时的,所以我们走Storm实时计算。然后通过计算我们可以得出结论买过键盘的人同时还买过鼠标,显示器等物品。然后我们将分析得到的文件/数据库再给到Tomcat推荐业务服务器,将结果再推送给客户。
结束啦!!欢迎微信扫码二维码关注公众号,更多精彩干货。









 京公网安备 11010802041100号
京公网安备 11010802041100号