作者:我才是陈墨_773 | 来源:互联网 | 2023-09-25 11:55
机器学习相关的技术
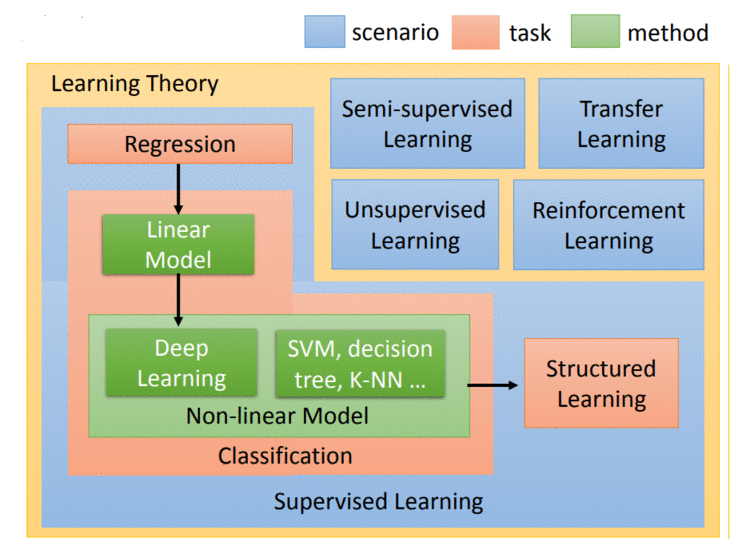
如果讲的更务实一点的话,machine learning所做的事情,你可以想成就是在寻找一个function,要让机器具有一个能力,这种能力是根据你提供给他的资料,它去寻找出我们要寻找的function。还有很多关键问题都可以想成是我们就是需要一个function。
假设你要做影像辨识,那就是找一个function,输入一张图片,然后输出图片里面有什么样的东西。 或者是大家都一直在说的Alpha GO,如果你要做一个可以下围棋machine时,其实你需要的也就是找一个function。这个function的输入是围棋上十九* 十九的棋盘。告诉机器在十九* 十九的棋盘上,哪些位置有黑子,哪些位置有白子。然后机器就会告诉你,接下来下一步应该落子在哪。或者是你要做一个聊天机器人,那你需要的是一个function,这个function的输入就是使用者的input,它的输出就是机器的回应。
机器可以根据训练资料判断一个function是好的,还是不好的。举例来说:在这个例子里面显然f_1f1,他比较符合training data的叙述,比较符合我们的知识。所以f1看起来是比较好的。f_2f2看起来是一个荒谬的function。我们今天讲的这个task叫做supervised learning。
监督学习
若你要训练这种machine,如同我们在Framework中讲的,你要准备一些训练资料,什么样的训练资料?你就告诉它是今天我们根据过去从政府的open data上搜集下来的资料。九月一号上午的PM2.5是63,九月二号上午的PM2.5是65,九月三号上午的PM2.5是100。所以一个好的function输入九月一号、九月二号的PM2.5,它应该输出九月三号的PM2.5;若给function九月十二号的PM2.5、九月十三号的PM2.5,它应该输出九月十四号的PM2.5。若收集更多的data,那你就可以做一个气象预报的系统。
刚才讲的都是让machine去解的任务,接下来要讲的是在解任务的过程中第一步就是要选择function set,选不同的function set就是选不同的model。Model有很多种,最简单的就是线性模型,但我们会花很多时间在非线性的模型上。在非线性的模型中最耳熟能详的就是Deep learning。
半监督学习 刚才我们讲的都是supervised learning(监督学习),监督学习的问题是我们需要大量的training data。training data告诉我们要找的function的input和output之间的关系。如果我们在监督学习下进行学习,我们需要告诉机器function的input和output是什么。这个output往往没有办法用很自然的方式取得,需要人工的力量把它标注出来,这些function的output叫做label。
那有没有办法减少label需要的量呢?就是半监督学习。
迁移学习 迁移学习的意思是:假设我们要做猫和狗的分类问题,我们也一样,只有少量的有label的data。但是我们现在有大量的data,这些大量的data中可能有label也可能没有label。但是他跟我们现在要考虑的问题是没有什么特别的关系的,我们要分辨的是猫和狗的不同,但是这边有一大堆其他动物的图片还是动画图片(凉宫春日,御坂美琴)你有这一大堆不相干的图片,它到底可以带来什么帮助。这个就是迁移学习要讲的问题。
无监督学习 我们举另外一个无监督学习的例子:假设我们今天带机器去动物园让它看一大堆的动物,它能不能够在看了一大堆动物以后,它就学会自己创造一些动物。那这个都是真实例子。仔细看了大量的动物以后,它就可以自己的画一些狗出来。有眼睛长在身上的狗、还有乳牛狗等等。
监督学习中的结构化学习 在machine要解的任务上我们讲了Regression、classification,还有一类的问题是structured learning。
structured learning 中让机器输出的是要有结构性的,举例来说:在语音辨识里面,机器输入是声音讯号,输出是一个句子。句子是要很多词汇拼凑完成。它是一个有结构性的object。或者是说在机器翻译里面你说一句话,你输入中文希望机器翻成英文,它的输出也是有结构性的。或者你今天要做的是人脸辨识,来给机器看张图片,它会知道说最左边是长门,中间是凉宫春日,右边是宝玖瑠。然后机器要把这些东西标出来,这也是一个structure learning问题。
强化学习 我们若将强化学习和监督学习进行比较时,在监督学习中我们会告诉机器正确答案是什么。若现在我们要用监督学习的方法来训练一个聊天机器人,你的训练方式会是:你就告诉
若我们用Alpha Go当做例子时,supervised learning就是告诉机器:看到这个盘式你就下“5-5”,看到这个盘式你就下“3-3”
原文转载自:https://datawhalechina.github.io/leeml-notes/#/chapter1/chapter1 感兴趣的小伙伴可以去自学










![[译]技术公司十年经验的职场生涯回顾](https://img8.php1.cn/3cdc5/24912/711/b6574f3292f9dc00.png)






 京公网安备 11010802041100号
京公网安备 11010802041100号