作者:sijiamian_767 | 来源:互联网 | 2023-09-10 20:04
1. 用线程池执行异步任务
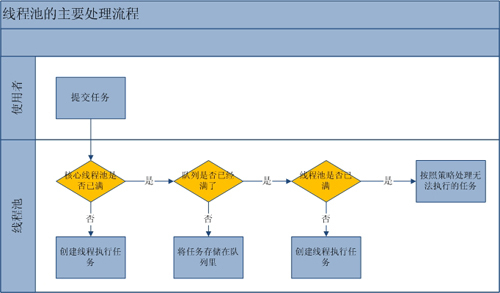
为了减少阻塞时间,加快响应速度,把无需返回结果的操作变成异步任务,用线程池来执行,这是提高性能的一种手段。
你可能要惊讶了,这么做不对吗?
首先,我们把异步任务分为两种:
显然大多数时候都是第一种。那么当你把任务丢给线程池,你知道它完成了没有吗?
如果服务器宕机、升级或重启,那些尚未完成或还在排队的任务就丢了。后果是,用户在促销活动中抢到的优惠券,没有发给用户。更严重的后果是,一个订单在送往仓库系统的途中消失了。
我推荐的做法是把任务投递到消息中间件,让它分发给消息消费者来执行(消费者可能是发送者自身)。
- 消息中间件可以要求消费者在完成任务后通知中间件,否则就重新分发消息,直到收到任务已完成的通知。
- 如果中间件没这种功能,可以让应用要求消费者在完成任务后回发一个"任务已完成"的消息,但应用不能同步等待这一消息,否则异步就退化为同步了。
更重要的是,消息中间件有持久化功能,即使宕机也不丢消息,而且可以长期不升级、不重启。消息中间件的缺点是,对失败情况的处理难以定制化——你可能想定制重试间隔、重试次数等细节。
换个角度来看,要解决丢任务的问题,你不一定要用消息中间件。你可以在应用代码中把任务和完成状态保存到数据库中,用线程池执行,在完成后更新状态。这是不是很像作业调度(例如Quartz)呢?是的。
然而,有些任务确实是可有可无的,例如『刷新一个不重要的缓存』的任务,那么就随便丢到线程池吧。
2. 日志采用同步模式
我们知道,性能瓶颈通常都是I/O,尤其是数据库的I/O。因此我们用了缓存,速度蹬的一下窜上来了——不一定哦。
用缓存把I/O变成了内存计算,最大瓶颈消除,速度上升一个数量级。在这个数量级,一些原本不重要的因素开始产生影响了。
日志是一种I/O啊,虽然顺序写磁盘很快,但还是比内存计算要慢啊。更糟的是,一个线程写日志时,另一个线程必须等它写完才能接着写,否则日志会乱,当日志量较大时,就stop the world了。
所以当你的系统性能高到一定程度,就要对日志做性能优化了(有过提高3倍QPS的案例),两个常见办法:
今天少打日志,明天排查bug就想哭。所以主要靠异步模式。
Logback可以通过配置(网上搜一搜),在RollingFileAppender上套一个AsyncAppender,实际上就是加了个缓冲队列,变成了批量写磁盘。缺点是无法看到最新日志(还没写磁盘)。queueSize默认是256,即使设为16,也有明显的性能提升,还缓和了不能及时看到最新日志的问题。
Log4j 2的异步模式有更深入的优化,是否选用,以测试数据为准。
3. 没有超时设置
网络忘记设超时,系统随时可能挂。
每一个网络操作,都记得设置超时时间,超过这个时间就放弃。访问分布式缓存也如此。
如果不设超时,可能会等到天荒地老。网络,就是这么不确定。
4. 没有统计缓存命中率
一个命中率低下的缓存,不如没有。虽然LRU算法很好用,但未必没有例外情况。频繁作废的数据、大体积数据都可能是负担。
统计缓存命中率的实现办法可以是内存里计数,定期写到数据库或文件;也可以是把命中情况打到日志里,日后汇总统计。也可能有更精巧的实现。
当你的系统进入精耕细作时代,这个问题必然摆上案头。
5. 没有统计缓存响应时间
缓存一定快吗?我真的见过不快的。分布式缓存要经由网络,网络抖一抖,缓存抖三抖;还依赖运维,运维抖一抖,缓存抖三抖。此事之微妙,不可不察也。
留个心,设个超时,记个响应时间。一个简单办法是,当响应时间过长时,打一行日志,正常情况不打日志。这样既留了记录,又不产生过多日志。
6. 单一的缓存模式
分布式缓存是由缓存中间件组成的集群,一致性较好,缓存的很快会同步到所有副本。但是毕竟要经由网络,延迟为亚毫秒级,而且负载聚集到中间件,可能因网络拥塞或机器负载高而出现性能波动。
为了进一步提高部分业务的性能和稳定性,可能要辅以本地缓存。
- 缓存要有过期策略,如果使用了Guava Cache,可以选择expireAfterAccess(不常用)、expireAfterWrite或refreshAfterWrite策略:
expire是先丢弃旧数据,再从数据库加载新数据,期间让数据库承担压力,适用于一般情况。
refresh是在异步加载新数据完成前,一直保留旧数据,能始终为数据库挡住压力,适用于高压情况。 - 各个应用实例的本地缓存是独立的,旧数据的作废依赖于过期策略。作为改进,可以利用消息队列,一个实例广播消息说某数据作废了,其他实例纷纷自检。这是准实时同步。
缓存的更新方式也影响着性能,@左耳朵耗子 的缓存更新的套路很好地介绍了三种套路,现在我来对比一下:
- Cache Aside Pattern: 应用程序在数据库和缓存之间周旋,以数据库为准。适合一般情况,因此最常用。
- Read/Write Through Pattern: 应用只读写缓存,缓存同步写回数据库(同步是指应用等待着写回完成)。理论性能略高一些。
- Write Behind Caching Pattern: 应用只读写缓存,缓存异步写回数据库(应用不等待写回完成,缓存若宕机将丢数据)。理论性能最高,如果有Write Ahead Logging特性,可避免丢数据,但略为降低性能。
7. 分布式缓存加锁
有的系统步入精耕细作时代后,想避免一种情况——缓存作废时,很多应用实例同时访问数据库,加重负载,而且浪费资源。于是有了给缓存加锁的方案。
简单版是每个实例内部设锁,某条数据只许一个线程去数据库取。复杂版是把锁设在分布式缓存中,某条数据只许一个实例去数据库取,然后放入缓存让其他实例用。
复杂版的想法是好的,但注意,锁要设置超时(还记得我上文说的吗),否则万一持有锁的实例发生问题,就全体耽误了。即使设了超时,也可能全体实例一直等待超时,浪费时间。所以这种方案不一定好,需以测试数据为准。
8. 疲于奔命
很多公司经常加班,实际上效率低下、也不持久,只能复制既有经验,靠不停换人来维持,其后果就是:需求混乱、bug巨多、创新乏力。
要把技术搞好,需要有条不紊,遇变不乱,持久输出。疲于奔命的模式,做不好大型服务端开发,也难以做好各种领域的开发。
作者:sorra
来源:51CTO








 京公网安备 11010802041100号
京公网安备 11010802041100号