作者:文逸博166293 | 来源:互联网 | 2023-06-04 20:45
我们就简单用一组数据来使用这三个组件首先自己随便准备一组测试数据,导入数据到mysql导入完成。一、用Sqoop1.99.7将mysql数据导入hdfs强烈推荐这篇博客blog.c
我们就简单用一组数据来使用这三个组件
首先自己随便准备一组测试数据,导入数据到mysql

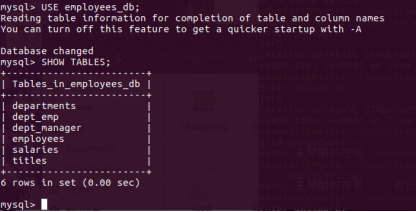
导入完成。
一、用Sqoop1.99.7将mysql数据导入hdfs
强烈推荐这篇博客 blog.csdn.net/m_signals/article/details/53190965
执行sqoop2-shell进入shell界面
setoption–name verbose –valuetrue 这个可以使操作输出更多的信息
setserver–host master –port 12000–webapp sqoop 设置端口号12000
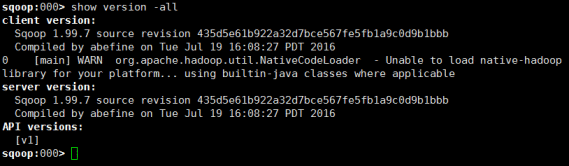
1.执行show version -all,查看sqoop2是否正常运作
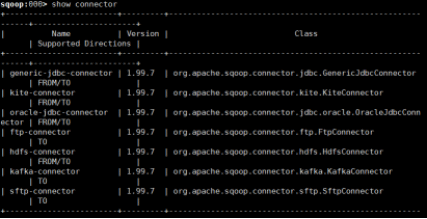
2.1执行show connector,查看有哪些注册了的连接器
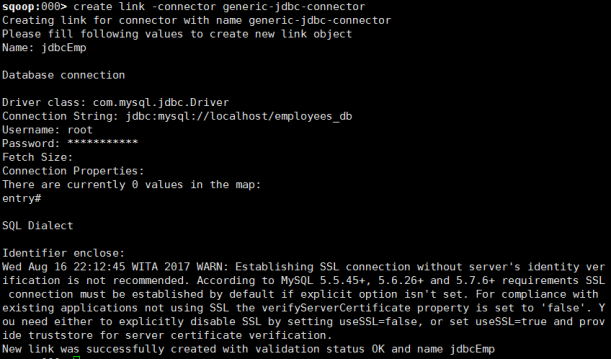
2.2创建连接
首先创建jdbc
create link -connector generic-jdbc-connector
Name:标示这个link的字符串,可以是一个自己喜欢的名称。
Driver Class:指定jdbc启动时所需要加载的driver类,这个类实现了Java.sql.Driver接口。对本文来说,这个值是com.mysql.jdbc.Driver。
Connection String:数据库链接字符串
Username:链接数据库的用户名,也就是mysql客户端传入的-u参数。
Password:链接数据库的用户密码。
FetchSize:这个属性并没有在官方文档上描述,直接回车了,使用的默认值。
Identifier enclose:指定SQL中标识符的定界符,也就是说,有的SQL标示符是一个引号:select * from “table_name”,这种定界符在MySQL中是会报错的。这个属性默认值就是双引号,所以不能使用回车,必须将之覆盖,使用空格覆盖这个值。
再创建HDFS
create link -connector hdfs-connector
其中URI是我们Hadoop配置文件中fs.defaultFS的值
Conf derectory使我们Hadoop配置文件的目录

查看我们创建的link,完成
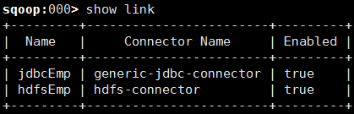
3.接下来就是job
3.1 创建job
create job -f jdbcEmp -t hdfsEmp
-f指定from,即是数据源位置,-t指定to,即是目的地位置。本例是从MySQL传递数据到HDFS,所以就是from mysql to HDFS。参数值就是在创建链接(link)时指定的Name。
3.2 提交job
首先查看我们创建成功的的job

提交Job
start job -n EmployeeToHdfs
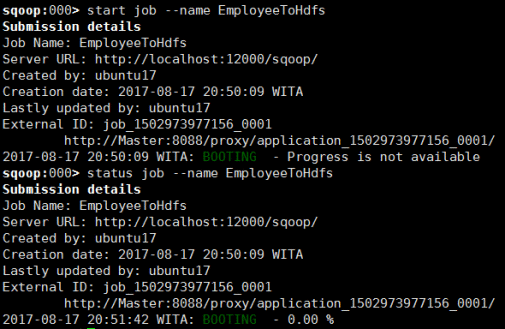
我们也可以在WebUI上查看进程
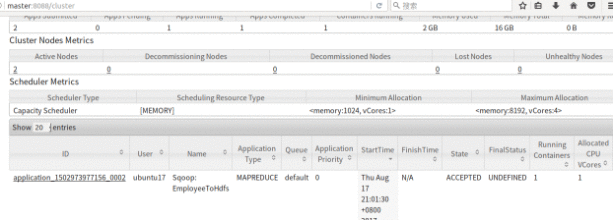
如果你发现如果最后WebUI上报错 ..Exception from container-launch…
那么可以尝试在hadoop的配置文件mapred-site.xml中加上两段话,对JVM的内存进行处理
mapreduce.admin.map.child.java.opts
-Xmx1024m
mapreduce.admin.reduce.child.java.opts
-Xmx5120m
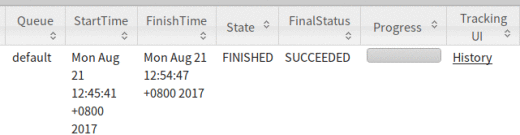
(这就是我从运行JOB到JOB FINISHED花了四天的原因之一…)
查看我们的数据
hadoop fs -cat /sqoop2/*
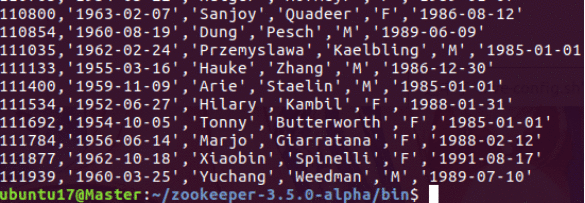
成功。
二、将数据从hdfs导入hbase并显示
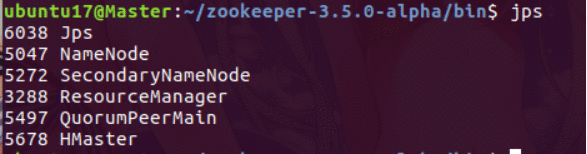
启动Hadoop之后,首先在各个节点上启动zookeeper,然后再启动Hbase
主节点有HMaster和QuorumPeerMain
分节点有HRegionServer和QuorumPeerMain
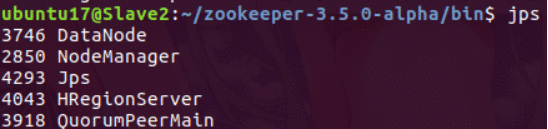
(如果HMaster启动不久就消失,那就是Hbase配置文件的问题,回头好好检查)
我们使用hbase提供的important工具来导入
首先执行hbase org.apache.hadoop.hbase.mapreduce.Import查看用法
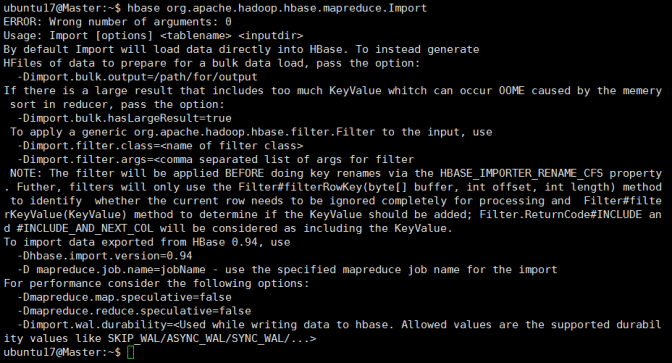
看起来大概就是刚才的命令+表名+文件
执行start-hbase.sh
执行hbase shell进入hbase,首先创建我们的表
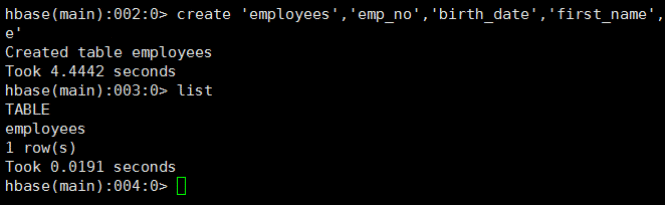
创建之后我们回命令行执行我们刚才所说的命令
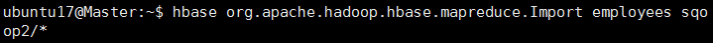
但是报错:不是序列化文件。所以就得换个方法了,于是我就找到下面这个命令
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.separator=”,” -Dimporttsv.columns=HBASE_ROW_KEY,**列名1**,**列名2** **表名** **文件路径**
这个命令就是先执行文件序列化,再导入HBase,我们实际操作下
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.separator=”,” -Dimporttsv.columns=HBASE_ROW_KEY,emp_no,birth_date,first_name,last_name,gender,hire_date employees sqoop2/*

然后就开始执行MapReduce程序,同样可以通过WebUI查询。
最后跑完,我们回hive查看下
执行scan‘employees’

大概就是这样了,因为数据比较多,我没等刷新完,但已经说数据已经成功从HDFS导入到HBase中了。
三、将数据从hdfs导入hive并显示
在导入数据之前,我们首先得根据源数据的类型来创建一个表
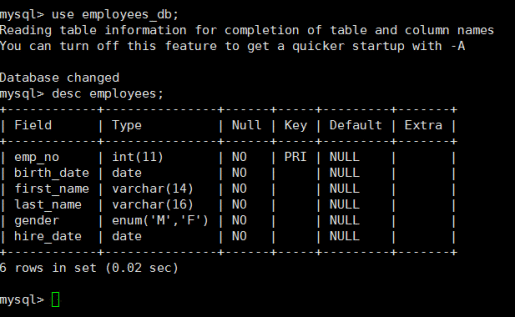
通过mysql可以看到有哪些数据和类型
所以我们进入到我们的hive界面,执行下面的操作创建一个新表
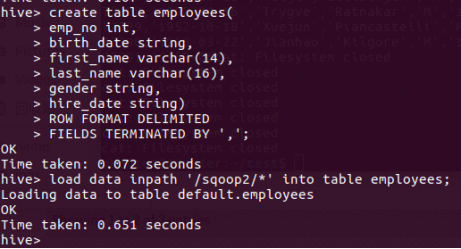
(hive中没有enum,所以我直接替换成了string;date类型我查了,hive应该是自带了的,但我始终打印出来的是NULL,所以暂时也用string代替)
然后执行
load data inpath‘**HDFS上的路径***’into table **表名称**;
将HDFS上的数据导入到hive中。
成功之后执行select * from **表名** ;
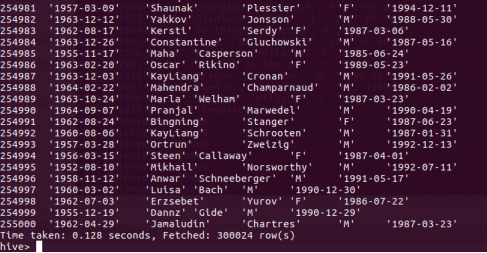
我们就可以看到已经成功的把数据导入到了hive中
四.hive和hbase的基本shell操作
这个在网上就随便搜搜就一大堆的,我再啰嗦就不好了….
至此结束,如果有任何错误地方欢迎指出(╯‵□′)╯︵┻━┻







 京公网安备 11010802041100号
京公网安备 11010802041100号