作者:手机用户2502859733 | 来源:互联网 | 2023-02-04 12:10
概要

详情
什么样的数据才能被称为“大数据”???
1、海量:数据足够多。
2、高增长率:单位时间内数据增长速度非常快。
3、多样化:数据的种类多种多样
为什么要研究大数据?
1、为了存储海量的数据。
2、为了进行海量数据的分析与计算。
重要的度量单位
bit、Byte、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB
一般来说,大数据指的是PB级别甚至更多的数据量。

Hadoop的概念
狭义上来说hadoop相当于一款数据库软件。
广义上来说hadoop是一个大数据神态圈。
它于2006正式的诞生,标志着大数据时代的到来!
图标是制作人儿子的大象

Hadoop主要版本
Hadoop一般有三种主要的版本系列Apache、Cloudera、Hortonworks。
Apache
最原始、最基础的版本,对于⼊⻔学习最好。2006发行

Cloudera
内部集成很多⼤数据框架,对应产品CDH。 2008发行
Hortonworks
⽂档较好,对应产品HDP。 2011发行
ps:Hortonworks已经被Cloudera公司收购推出新品牌CDP。
Hadoop版本号区别
Hadoop1.X
MapReduce # 计算与资源调度
HDFS # 数据存储
Common # 辅助工具
Hadoop2.X与3.X(对计算与资源调度的功能做进一步拆分)
MapReduce # 计算
Yarn # 资源调度
HDFS # 数据存储
Common # 辅助工具
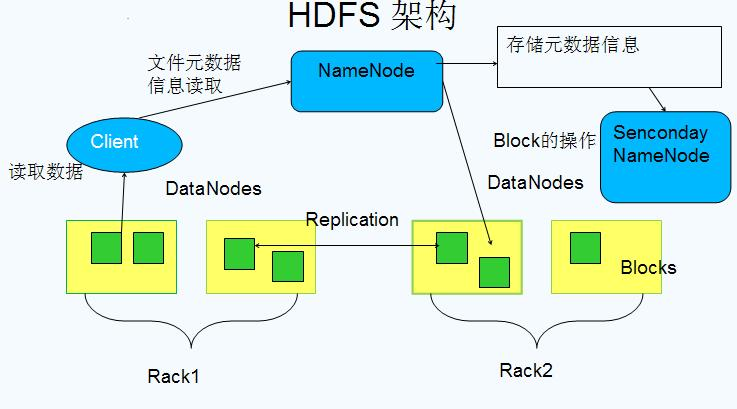
HDFS架构组成
NameNode(nn): 存储文件的元数据。 # 相当于目录
DataNode(dn): 存储文件的真实数据。 # 当对于文本内容
Secondary NameNode(2nn): 辅助NameNode工作。 # 相当于备用设施
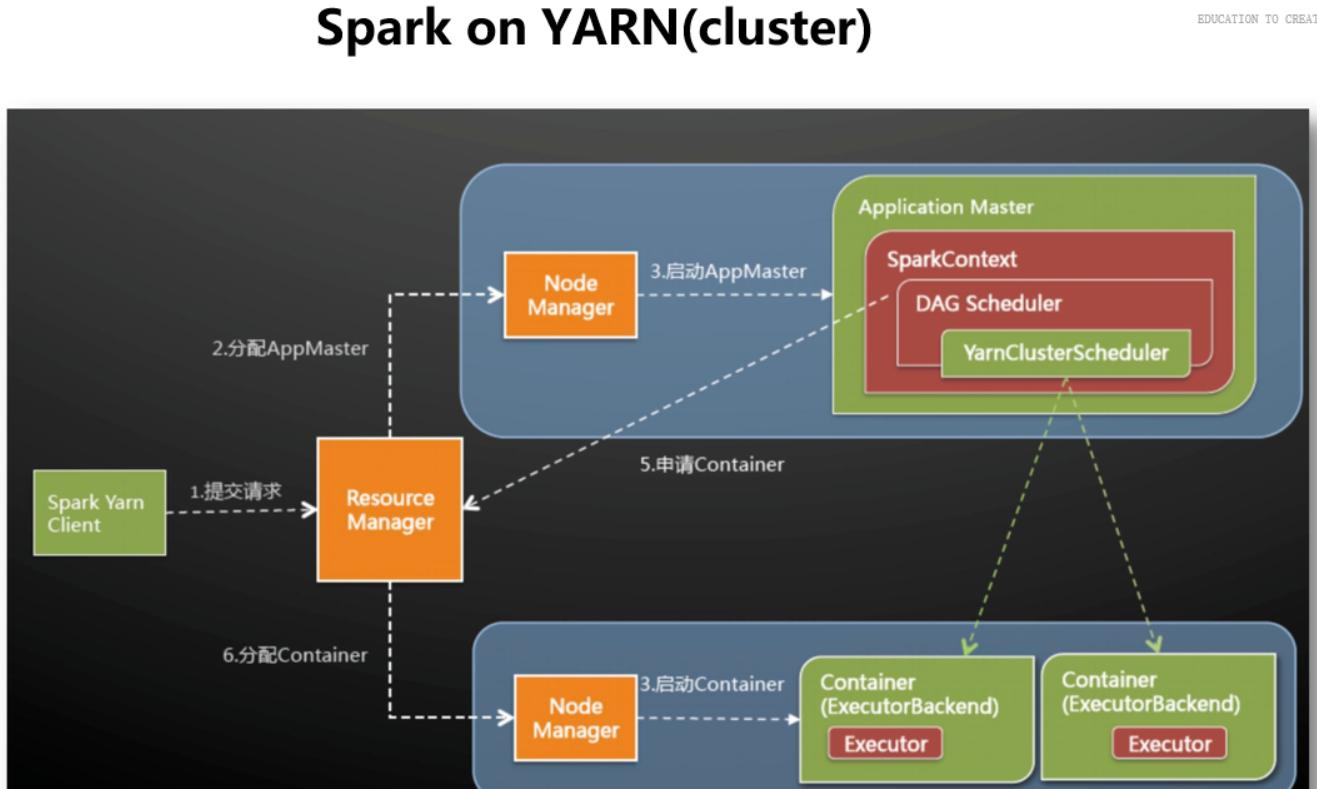
Yarn架构组成
# 做个比喻
Resource Manager: 大老板
Node Manager: 各部门经理
Application Master: 部门中真正干活的员工
Container: 每个部门拥有的各项资源
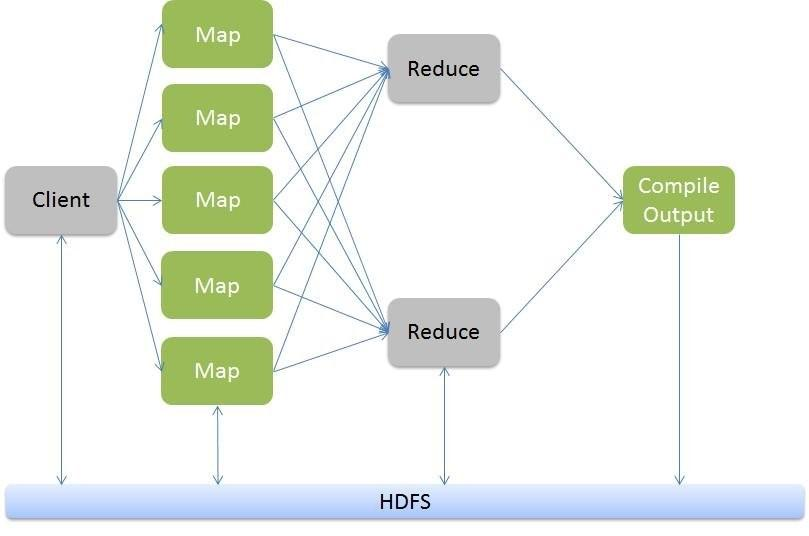
MapReduce架构组成
# 做个比喻
Map: 将复杂的任务拆分成多个小任务分发给不同的节点完成。
Reduce: 将每个节点完成的小任务汇总到一起。
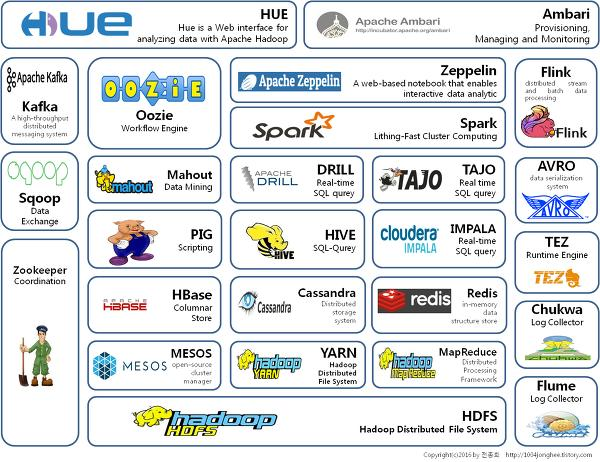
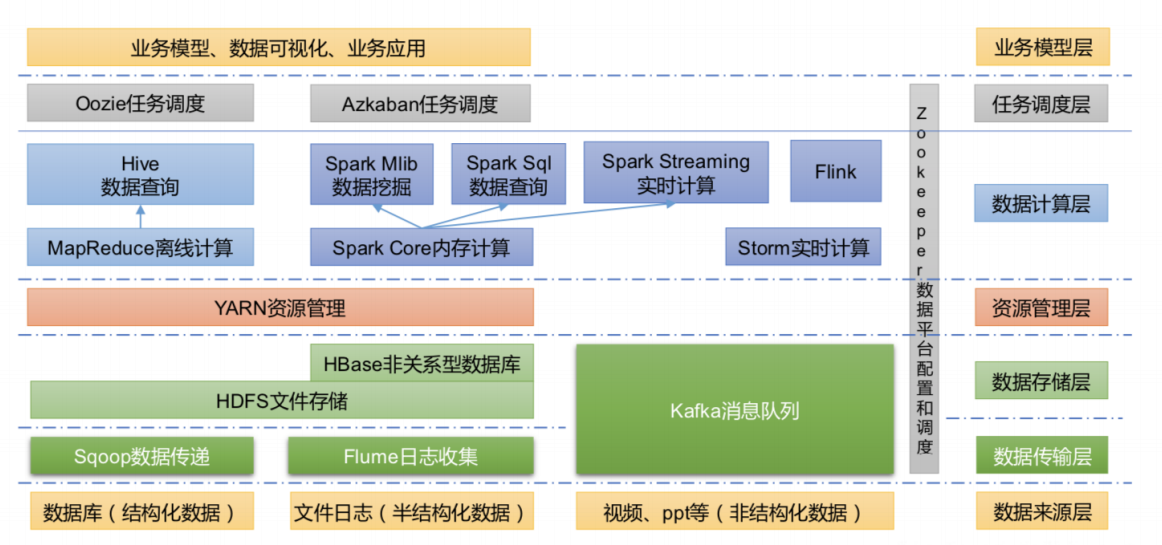
技术生态圈
''' 数据来源层 '''
针对结构化数据(关系型数据库)采用sqoop进行数据同步
针对半结构化、非结构化数据(非关系型数据库)采用flume、kafka进行同步
原文链接:https://www.cnblogs.com/leguan001/p/15471227.html





![Spark中使用map或flatMap将DataSet[A]转换为DataSet[B]时Schema变为Binary的问题及解决方案](https://img6.php1.cn/3cdc5/9b0d/243/f27d40b3b7e4b51b.png)





 京公网安备 11010802041100号
京公网安备 11010802041100号