对于7×24小时不间断运行的流程序来说,要保证fault tolerant是很难的,这不像是离线任务,如果失败了只需要清空已有结果,重新跑一次就可以了。对于流任务,如果要保证能够重新处理已处理过的数据,就要把数据保存下来;而这就面临着几个问题:比如一是保存多久的数据?二是重复计算的数据应该怎么处理,怎么保证幂等性?
对于一个流系统,我们有以下希望:
- 最好能做到exactly-once
- 处理延迟越低越好
- 吞吐量越高越好
- 计算模型应当足够简单易用,又具有足够的表达力
- 从错误恢复的开销越低越好
- 足够的流控制能力(背压能力)
Storm的ack机制
storm的fault tolerant是这样工作的:每一个被storm的operator处理的数据都会向其上一个operator发送一份应答消息,通知其已被下游处理。storm的源operator保存了所有已发送的消息的每一个下游算子的应答消息,当它收到来自sink的应答时,它就知道该消息已经被完整处理,可以移除了。
如果没有收到应答,storm就会重发该消息。显而易见,这是一种at least once的逻辑。另外,这种方式面临着严重的幂等性问题,例如对一个count算子,如果count的下游算子出错,source重发该消息,那么防止该消息被count两遍的逻辑需要程序员自己去实现。最后,这样一种处理方式非常低效,吞吐量很低。
SparkStreaming 的moni Batch
storm的实现方式就注定了与高吞吐量无缘。那么,为了提高吞吐量,把一批数据聚集在一起处理就是很自然的选择。Spark Streaming的实现就是基于这样的思路。
我们可以在完全的连续计算与完全的分批计算中间取折中,通过控制每批计算数据的大小来控制延迟与吞吐量的制约,如果想要低延迟,就用小一点的batch,如果想要大吞吐量,就不得不忍受更高的延迟(更久的等待数据到来的时间和更多的计算)。
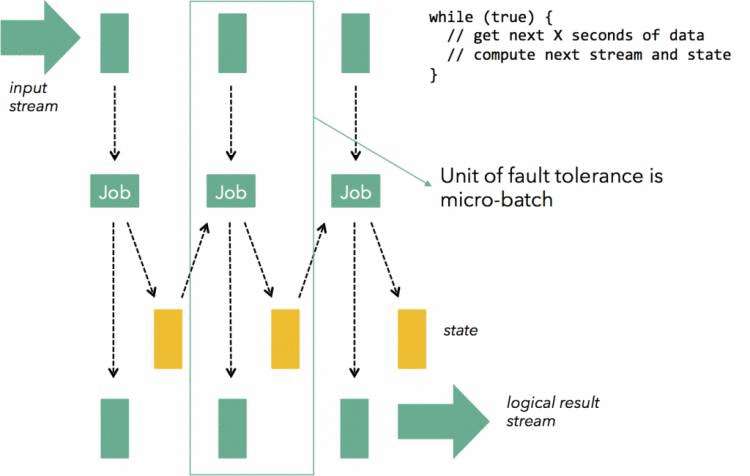
以这样的方式,可以在每个batch中做到exactly-once,但是这种方式也有其弊端:
首先,batch的方式使得一些需要跨batch的操作变得非常困难,例如session window;用户不得不自己想办法去实现相关逻辑。
其次,batch模式很难做好背压。当一个batch因为种种原因处理慢了,那么下一个batch要么不得不容纳更多的新来数据,要么不得不堆积更多的batch,整个任务可能会被拖垮,这是一个非常致命的问题。
最后,batch的方式基本意味着其延迟是有比较高的下限的,实时性上不好。
Flink的容错
我们在传统数据库,如mysql中使用binlog来完成事务,这样的思路也可以被用在实现exactly-once模型中。例如,我们可以log下每个数据元素每一次被处理时的结果和当时所处的操作符的状态。这样,当我们需要fault tolerant时,我们只需要读一下log就可以了。这种模式规避了storm和spark所面临的问题,并且能够很好的实现exactly-once,唯一的弊端是:如何尽可能的减少log的成本?Flink给了我们答案。
实现exactly-once的关键是什么?是能够准确的知道和快速记录下来当前的operator的状态、当前正在处理的元素(以及正处在不同算子之间传递的元素)。如果上面这些可以做到,那么fault tolerant无非就是从持久化存储中读取上次记录的这些元信息,并且恢复到程序中。那么Flink是如何实现的呢?
Flink的分布式快照的核心是其轻量级异步分布式快照机制。为了实现这一机制,flink引入了一个概念,叫做Barrier。Barrier是一种标记,它被source产生并且插入到流数据中,被发送到下游节点。当下游节点处理到该barrier标志时,这就意味着在该barrier插入到流数据时,已经进入系统的数据在当前节点已经被处理完毕。
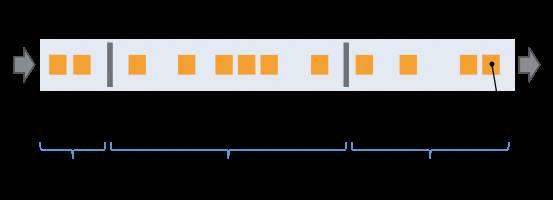
如图所示,每当一个barrier流过一个算子节点时,就说明了在该算子上,可以触发一次检查点,用以保存当前节点的状态和已经处理过的数据,这就是一份快照。(在这里可以联想一下micro-batch,把barrier想象成分割每个batch的逻辑,会好理解一点)这样的方式下,记录快照就像和前面提到的micro-batch一样容易。
与此同时,该算子会向下游发送该barrier。因为数据在算子之间是按顺序发送的,所以当下游节点收到该barrier时,也就意味着同样的一批数据在下游节点上也处理完毕,可以进行一次checkpoint,保存基于该节点的一份快照,快照完成后,会通知JobMananger自己完成了这个快照。这就是分布式快照的基本含义。

有时,有的算子的上游节点和下游节点都不止一个,应该怎么处理呢?如果有不止一个下游节点,就向每个下游发送barrier。同理,如果有不止一个上游节点,那么就要等到所有上游节点的同一批次的barrier到达之后,才能触发checkpoint。因为每个节点运算速度不同,所以有的上游节点可能已经在发下个barrier周期的数据了,有的上游节点还没发送本次的barrier,这时候,当前算子就要缓存一下提前到来的数据,等比较慢的上游节点发送barrier之后,才能处理下一批数据。
当整个程序的最后一个算子sink都收到了这个barrier,也就意味着这个barrier和上个barrier之间所夹杂的这批元素已经全部落袋为安。这时,最后一个算子通知JobManager整个流程已经完成,而JobManager随后发出通知,要求所有算子删除本次快照内容,以完成清理。这整个部分,就是Flink的两阶段提交的checkpoint过程,如下面四幅图所示:
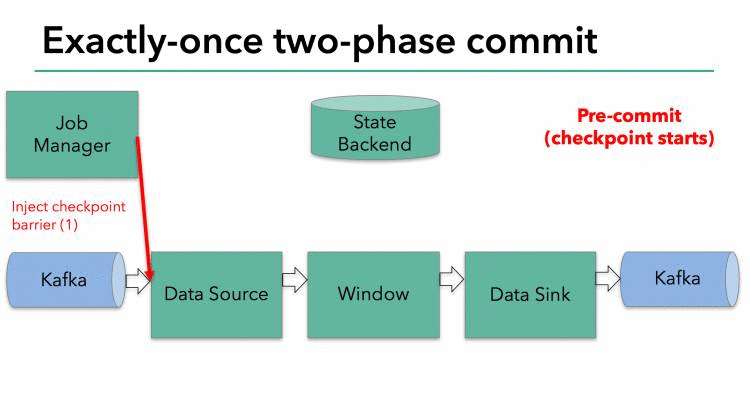
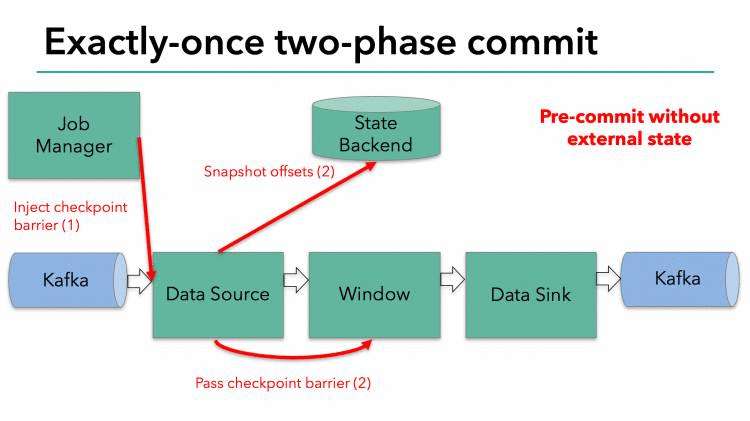
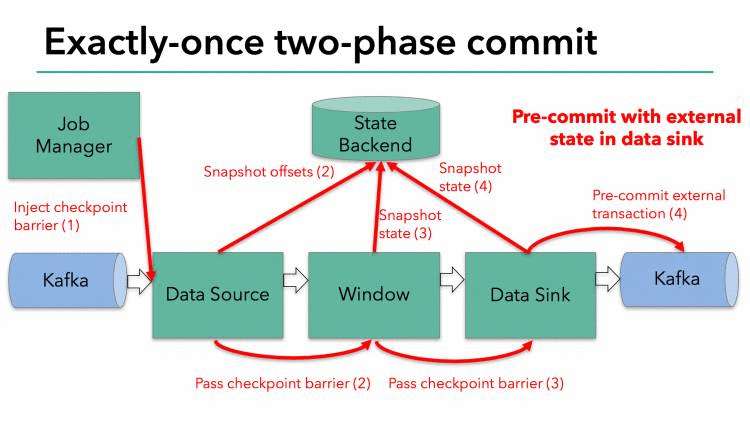
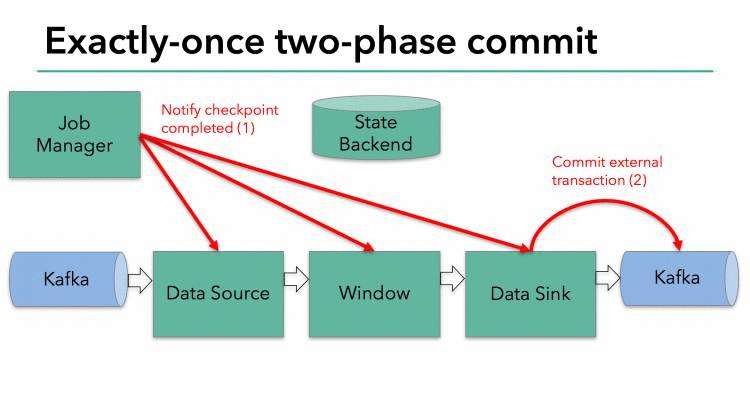
总之,通过这种方式,flink实现了我们前面提到的六项对流处理框架的要求:exactly-once、低延迟、高吞吐、易用的模型、方便的恢复机制。











 京公网安备 11010802041100号
京公网安备 11010802041100号