在大数据方兴未艾之际,越来越多的技术被引进大数据领域。从多年前的mapreduce到现在非常流行的spark,spark自从出现以来就逐渐有替代mapreduce的趋势。既然如此,spark到底有什么过人之处?这么备受青睐?
一、Spark是什么?
Spark是一种通用的大数据计算框架,和传统的大数据技术MapReduce有本质区别。前者是基于内存并行计算的框架,而mapreduce侧重磁盘计算。Spark是加州大学伯克利分校AMP实验室开发的通用内存并行计算框架,用于构建大型的、低延迟的数据分析应用程序。
Spark同样支持离线计算和实时计算两种模式。Spark离线计算速度要比Mapreduce快10-100倍。而实时计算方面,则依赖于SparkStreaming的批处理能力,吞吐量大。不过相比Storm,SparkStreaming并不能做到真正的实时。
Spark使用强大的函数式语言Scala开发,方便简单。同时,它还提供了对Python、Java和R语言的支持。
2015年至今,Spark在国内IT行业变得愈发火爆,越来越多的公司开始重点部署或者使用Spark来替代MapReduce、Hive、Storm等传统的大数据计算框架。如袋鼠云,便用Spark代替了Mapreduce计算框架。
二、Spark的发展历程
2009年由Berkeley's AMPLab开始编写最初的源代码。
2010年开放源代码。
2013年6月,进入Apache孵化器项目。
2014年2月,成为Apache的顶级项目,仅仅用了8个月的时间。
2014年5月,底Spark1.0.0发布,打破Hadoop保持的基准排序纪录。
2014年12月,Spark1.2.0发布。
2015年11月,Spark1.5.2发布,同时推出DataFrame。
2016年1月,Spark1.6发布。
2016年12月,Spark2.1发布,同年推出DataSet。
2017年,Structured Streaming 发布。
2018年,Spark2.4.0发布,成为全球最大的开源项目。
三、为什么Spark越来越受欢迎?
1、内存计算、运行速度快:Spark使用DAG执行引擎用以支持循环数据流与内存计算。注意:shuffle部分也有磁盘参与计算。
2、支持多语言编程:支持使用Scala、Python、Java和R语言进行编程,同时可以通过Spark Shell进行交互式编程。
3、生态强、组件丰富:Spark支持离线和实时计算,如包括SparkSql查询、SparkStreaming流式计算、MLLib机器学习和 GraphX图算法。
4、运行方便、多数据源支持:Spark可运行于独立的集群模式中、可运行于Hadoop中、也可运行于Amazon EC2云环境中。同时可以访问HDFS、HBase、Hive、Kafka和传统关系型数据库等多种数据源 。
四、Spark生态

SparkCore:SparkCore实现了spark的基本功能、包括任务调度、内存管理、错误恢复与存储系统交互等模块。SparkCore中还包含了对弹性分布式数据集RDD的定义,这是其核心功能。
SparkSql:SparkSql是spark用来操作结构化数据的程序,我们可以使用Sql或者Hql来查询数据、操作数据库。SparkSql可以读取多种数据源,除了提供Sql查询接口之外,同时还支持将Sql和RDD结合,开发者可以在一个应用中同时使用Sql和编程方式进行数据的查询分析。
SparkStreaming:SparkStreaming是Spark提供的对实时数据进行流式计算的组件。如网页服务器日志消息实时流处理。
SparkMLLib:SparkMLLib是Spark中提供常见的机器学习功能的程序库,包括很多机器学习算法,比如分类、回归、聚类、协同过滤等。
GraphX:GraphX是分布式图处理框架,用于图计算。如社交网络的朋友关系图。
五、Spark和Hadoop的区别
1、spark和hadoop的比较
Hadoop主要用普通硬件解决存储和计算问题;而Spark用于构建大型的、低延迟的数据分析应用程序,不进行存储、只进行计算。
Spark是在MapReduce基础上发展而来的,继承了其分布式并行计算的优点并改进了MapReduce的缺陷。
Spark中间数据放到内存中,迭代运算效率高,但是特别依赖内存。Spark引进了弹性分布式数据集RDD,数据对象既可以放在内存,也可以放在磁盘,容错性高。RDD计算时可以通过CheckPoint来实现容错。
Hadoop只提供了Map和Reduce操作,Spark更加通用,提供的数据集操作类型有很多种,主要分为:Transformations和Actions两大类算子。
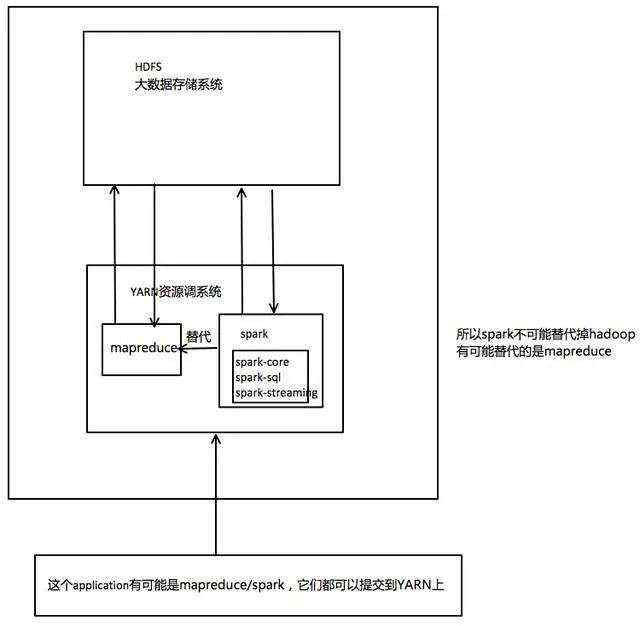
spark和mapredcue
2、spark和mapredcue的比较
1)、spark的shuffle过程不需要等待,使用的时候才对数据排序。
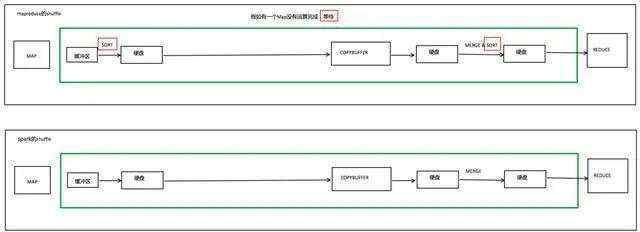
2)、spark可以把多次使用的数据缓存放到内存中。
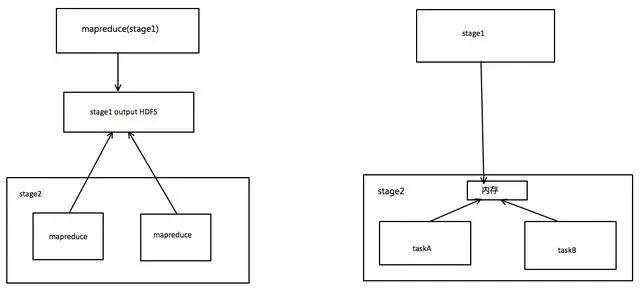
3)、spark支持多种算子操作,而mapreduce只支持map和redcue操作。

4)、spark过度依赖于内存,对内存要求高。

总而言之, Spark主要用于大数据的计算,而Hadoop主要用于大数据的存储,以及资源调度。Spark和Hadoop的组合,将会取代Mapredcue和Hadoop的组合成为未来大数据领域的基础。










 京公网安备 11010802041100号
京公网安备 11010802041100号