Flume: 分布式日志收集系统,最初由Cloudera 开发,现是Apache的一个开源项目 Chukwa:开源分布式数据收集系统,是Hadoop 的组成部分,构建在 hdfs 和 map/reduce 框架之上 Scrible:Scribe是facebook开源的日志收集系统,在facebook内部已经得到大量的应用 Kafka:最早是LinkedIn的开发的消息系统,现是Apache的一个开源项目
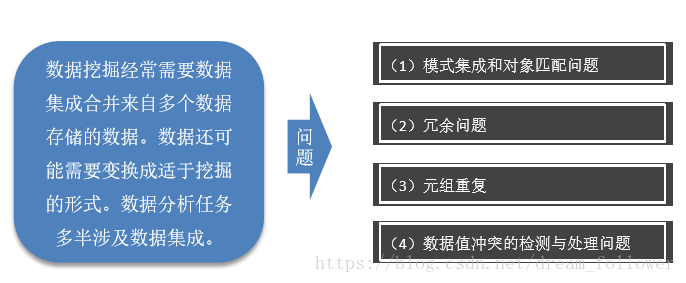
通过数据预处理工作, 可以使残缺的数据完整 ,并将错误的数据纠正 、多余的数据去除,进 而将所需的数据挑选出 来,并且进行数据集成 。数据预处理的常见方 法有数据清洗、数据集 成与数据变换。
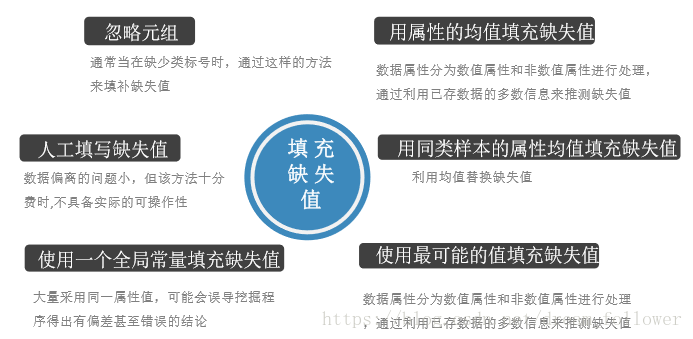
噪声的处理 数据清洗可以视为一个过程,包括检测偏差和纠正偏差两个步骤。 检查偏差:可以使用已有的关于数据性质的知识发现噪声、离群点和需要考察的不寻常 的值。这种知识或“关于数据的数据”称为元数据。 纠正偏差:即一旦发现偏差,通常需要定义并使用一系列的变换来纠正它们。但这些工 具只支持有限的变换,因此,常常可能需要为数据清洗过程的这一步编写定 制的程序










 京公网安备 11010802041100号
京公网安备 11010802041100号