首页
技术博客
PHP教程
数据库技术
前端开发
HTML5
Nginx
php论坛
新用户注册
|
会员登录
PHP教程
技术博客
编程问答
PNG素材
编程语言
前端技术
Android
PHP教程
HTML5教程
数据库
Linux技术
Nginx技术
PHP安全
WebSerer
职场攻略
JavaScript
开放平台
业界资讯
大话程序猿
登录
极速注册
取消
热门标签 | HotTags
regex
runtime
process
instance
ascii
char
cPlusPlus
java
cmd
select
uml
triggers
random
dockerfile
typescript
copy
plugins
testing
join
bitmap
less
python3
dagger
cpython
frameworks
string
rsa
const
blob
default
web
ip
eval
int
install
nodejs
uri
keyword
main
sum
timestamp
require
bit
hashset
golang
split
python
jsp
callback
flutter
javascript
audio
heap
version
format
js
fetch
foreach
utf-8
erlang
range
future
input
php8
import
perl
controller
tree
io
go
email
hashtable
数组
solr
substring
node.js
md5
hook
cookie
当前位置:
开发笔记
>
编程语言
> 正文
大数据管理与分析2hadoop
作者:许祥生老师 | 来源:互联网 | 2023-08-09 01:20
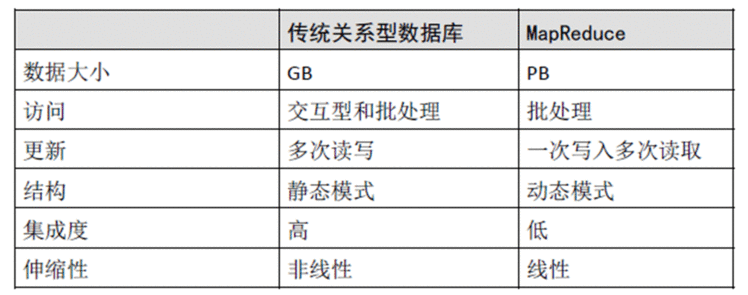
hadoophadoop概述Hadoop的作用与功能hadoop优点hadoop体系结构HDFS体系结构MapReduce体系结构hadoop概述hadoop是一个开源的可运行在
hadoop
hadoop概述
Hadoop的作用与功能
hadoop优点
hadoop体系结构
HDFS 体系结构
MapReduce 体系结构
hadoop概述
hadoop是一个开源的可运行在大规模集群上的分布式并行编程框架,实现了Map/Reduce 计算模型
Hadoop的作用与功能
Hadoop采用了分布式存储方式,提高了读写速度,并扩大了存储容量
采用MapReduce来整合分布式文件系统上的数据,可保证分析和处理数据的高效
Hadoop还采用存储冗余数据的方式保证数据的安全性
Hadoop中HDFS的高容错特性,以及它是基于Java 语言开发的,使得Hadoop可以部署在低廉的计算机集群
Hadoop中HDFS的数据管理能力,MapReduce处理任务时的高效率,以及它的开源特性,使其在同类的分布式系统中大放异彩,并在众多行业中被广泛采用
hadoop优点
可靠:维护多个工作数据副本,保证对失效节点重新分布处理
高效:一并行方式工作,通过并行处理加快速度。Hadoop可伸缩,能处理PB级数据
成本低:依赖于廉价的服务器
运行在Linux平台上
支持多种编程语言
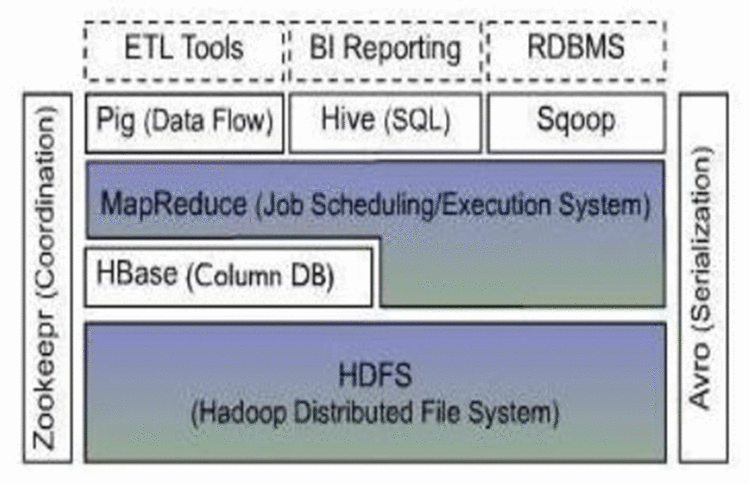
hadoop体系结构
核心:HDFS 和 MapReduce
Hadoop 分布式文件系统 HDFS,提供高可靠性的底层存储支持
HBase 位于结构化存储层,一个分布式的列存储数据库
Avro 数据序列化系统,将数据对象转化成便于数据存储和网络传输的格式
Zookeeper 一个分布式的、高可靠性的协调服务,提供分布式所之类的基本服务
Hive 建立在hadoop之上的数据仓库
Pig 提供一种数据流语言,pig数据流脚本自动转换成为MapReduce任务链在hadoop上执行
Sqoop SQL-to-hadoop 为 RDBMS与Hadoop平台之间及逆行快速批量数据交换
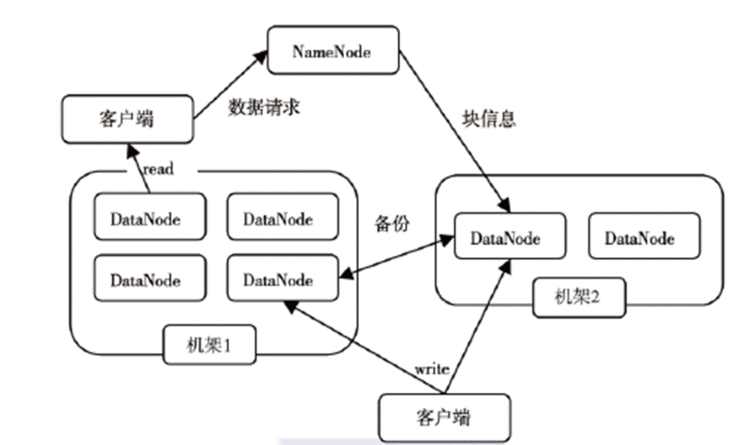
HDFS 体系结构
一个HDFS 集群有一个NameNode 和若干个DataNOde组成
NameNode作为主服务器,管理文件系统的命名空间和客户端对文件访问操作;它维护着文件系统树(filesystem tree)以及文件树中所有的文件和文件夹的元数据(metadata)。
DataNode 管理存储数据
HDFS 支持用户以文件形式存储数据,文件被分程若干数据块,放在一组DataNode上
没有namenode, 文件系统将无法使用。事实上,如果运行namenode 服务的机器毁坏,文件系统上所有的文件将会丟失,因为我们不知道如何根据datanode 的块重建文件。
心跳是每3秒一次,心跳返回结果带有namenode给该datanode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个datanode的心跳,则认为该节点不可用。
控制命令由客户端提交
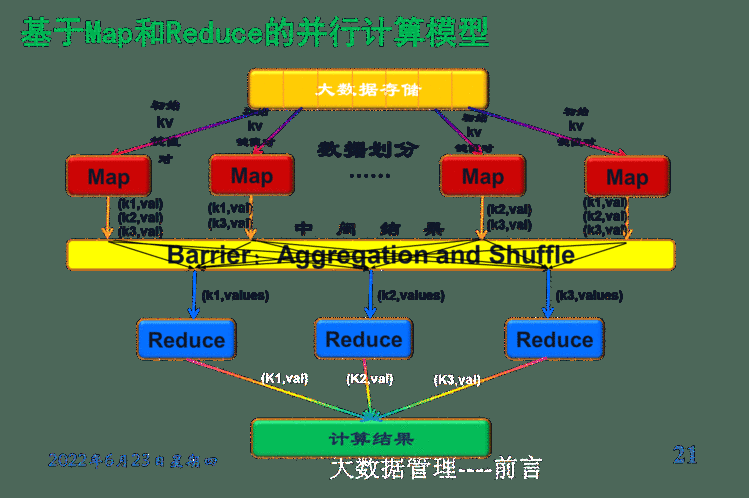
MapReduce 体系结构
有一个单独运行在主节点上的JobTracker 和 运行在每个集群姐带你上的 TaskTracker共同组成
JobTracker 和 namenode不一定在同一台机器上
TaskTracker和 dataNode是一一对应的
主节点负责调度一个作业的所有任务,这些人物分布在不同的从节点上;主节点监控他们的执行情况,柄重新执行之前是白的任务。从节点只负责由主节点指派的任务。
当一个Job被提交后,JobTracker接收到提交作业和配置信息之后,将配置信息分发给从节点,同时调度任务并监控TaskTracker的执行
hadoop
hdfs
mapreduce
分布式
编程
文件
安全
java
服务器
写下你的评论吧 !
吐个槽吧,看都看了
会员登录
|
用户注册
推荐阅读
cmd
Python 实现监控与运维自动化方案
本文探讨了使用Python实现监控信息收集的方法,涵盖从基础的日志记录到复杂的系统运维解决方案,旨在帮助开发者和运维人员提升工作效率。 ...
[详细]
蜡笔小新 2024-11-23 11:25:14
cmd
深入解析:存储技术的演变与发展
本文探讨了从单机文件系统到分布式文件系统的存储技术发展过程,详细解释了各种存储模型及其特点。 ...
[详细]
蜡笔小新 2024-11-19 11:25:40
java
构建用户画像环境:Hive与SparkSQL的高效整合
本文介绍如何通过整合SparkSQL与Hive来构建高效的用户画像环境,提高数据处理速度和查询效率。 ...
[详细]
蜡笔小新 2024-11-19 09:44:24
java
大数据领域的职业路径与角色解析
本文将深入探讨大数据领域的各种职业和工作角色,帮助读者全面了解大数据行业的需求、市场趋势,以及从入门到高级专业人士的职业发展路径。文章还将详细介绍不同公司对大数据人才的需求,并解析各岗位的具体职责、所需技能和经验。 ...
[详细]
蜡笔小新 2024-11-16 08:54:03
java
从0到1搭建大数据平台
从0到1搭建大数据平台 ...
[详细]
蜡笔小新 2024-11-12 15:26:03
java
Zookeeper在Hadoop生态系统中的关键作用与应用分析
Zookeeper作为Apache Hadoop生态系统中的一个重要组件,主要致力于解决分布式应用中的常见数据管理难题。它提供了统一的命名服务、状态同步服务以及集群管理功能,有效提升了分布式系统的可靠性和可维护性。此外,Zookeeper还支持配置管理和临时节点管理,进一步增强了其在复杂分布式环境中的应用价值。 ...
[详细]
蜡笔小新 2024-11-04 15:48:51
string
Redis:缓存与内存数据库详解
本文介绍了数据库的基本分类,重点探讨了关系型与非关系型数据库的区别,并详细解析了Redis作为非关系型数据库的特点、工作模式、优点及持久化机制。 ...
[详细]
蜡笔小新 2024-11-18 14:16:11
string
8个IDC大数据基础定义解析丨IDC
本文针对IDC数据行业相关名词术语进行解析,分为4组相关概念,希望大家读完 ...
[详细]
蜡笔小新 2024-11-16 18:25:46
string
Hadoop 架构详解:核心组件解析
本文介绍了Hadoop的核心组件,包括高可靠性和高吞吐量的分布式文件系统HDFS、分布式的离线并行计算框架MapReduce、作业调度与集群资源管理框架YARN以及支持其他模块的工具模块Common。 ...
[详细]
蜡笔小新 2024-11-16 12:13:59
java
Java EE 平台的 13 种核心技术
Java EE 平台集成了多种服务、API 和协议,旨在支持基于 Web 的多层应用程序开发。本文将详细介绍 Java EE 中的 13 种关键技术规范,帮助开发者更好地理解和应用这些技术。 ...
[详细]
蜡笔小新 2024-11-15 21:15:35
default
HDFS API
Hadoop的文件操作位于包org.apache.hadoop.fs里面,能够进行新建、删除、修改等操作。比较重要的几个类:(1)Configurati ...
[详细]
蜡笔小新 2024-11-13 17:31:50
java
Python 数据可视化实战指南
本文详细介绍如何使用 Python 进行数据可视化,涵盖从环境搭建到具体实例的全过程。 ...
[详细]
蜡笔小新 2024-11-13 06:03:30
java
【漫画解析】数据已删,存储空间为何未减?揭秘背后真相
在数据迁移过程中,即使删除了原有数据,存储空间却未必会相应减少。本文通过漫画形式解析了这一现象背后的真相。具体来说,使用 `mysqldump` 命令进行数据导出时,该工具作为 MySQL 的逻辑备份工具,通过连接数据库并查询所需数据,将其转换为 SQL 语句。然而,这种操作并不会立即释放存储空间,因为数据库系统可能保留了已删除数据的碎片信息。文章进一步探讨了如何优化存储管理,以确保数据删除后能够有效回收存储空间。 ...
[详细]
蜡笔小新 2024-11-04 17:11:49
java
Hadoop集群搭建常见问题与解决方案(一):避免配置过程中的常见陷阱
在搭建Hadoop集群以处理大规模数据存储和频繁读取需求的过程中,经常会遇到各种配置难题。本文总结了作者在实际部署中遇到的典型问题,并提供了详细的解决方案,帮助读者避免常见的配置陷阱。通过这些经验分享,希望读者能够更加顺利地完成Hadoop集群的搭建和配置。 ...
[详细]
蜡笔小新 2024-11-03 19:59:23
default
Hadoop 2.6 日志文件解析与MapReduce日志管理深入探讨
Hadoop 2.6 主要由 HDFS 和 YARN 两大部分组成,其中 YARN 包含了运行在 ResourceManager 的 JVM 中的组件以及在 NodeManager 中运行的部分。本文深入探讨了 Hadoop 2.6 日志文件的解析方法,并详细介绍了 MapReduce 日志管理的最佳实践,旨在帮助用户更好地理解和优化日志处理流程,提高系统运维效率。 ...
[详细]
蜡笔小新 2024-11-03 16:23:38
许祥生老师
这个家伙很懒,什么也没留下!
Tags | 热门标签
regex
runtime
process
instance
ascii
char
cPlusPlus
java
cmd
select
uml
triggers
random
dockerfile
typescript
copy
plugins
testing
join
bitmap
less
python3
dagger
cpython
frameworks
string
rsa
const
blob
default
RankList | 热门文章
1
ubnt路由器详细设置教程?
2
ref,out,params参数的理解
3
windows10 绰号 bug10,是真的吗?
4
vue 图片上传 回显 删除
5
开发笔记:Java实现短信验证码设置发送间隔时间,以及有效时间(Java+Redis)
6
滬字意思 在新华字典的读音解释笔画常用组词起名
7
2个dom oracle,oracle 基本元素转
8
计算机内存die,从内存时序的角度告诉你 三星BDIE为何成为高端所用
9
git将项目上传到远程仓库,如 github
10
ubuntu无法打开外接硬盘
11
AngularJS的双向绑定是如何实现的?
12
python创建窗口接收消息_14.1.2 创建窗口
13
WAMP环境中扩展oracle函数库(oci),wampoci
14
没有用户名的ASP.NET登录控件 - ASP.NET Login control without a Username
15
和你关系不好的U3D主程不愿意被你知道的性能优化知识
PHP1.CN | 中国最专业的PHP中文社区 |
DevBox开发工具箱
|
json解析格式化
|
PHP资讯
|
PHP教程
|
数据库技术
|
服务器技术
|
前端开发技术
|
PHP框架
|
开发工具
|
在线工具
Copyright © 1998 - 2020 PHP1.CN. All Rights Reserved |
京公网安备 11010802041100号
|
京ICP备19059560号-4
| PHP1.CN 第一PHP社区 版权所有








 京公网安备 11010802041100号
京公网安备 11010802041100号