作者:Irises---_372 | 来源:互联网 | 2023-07-15 17:38
1、大数据采集
1.1 大数据采集概念
数据采集(DAQ)又称数据获取,通过RFID射频数据、传感器数据、社交网络数据、移动互联网数据等方式获得各种类型的结构化、半结构化及非结构化的海量数据。
1.2 常用的数据采集方式
大数据的采集通常采用多个数据库来接收终端数据,包括智能硬件端、多种传感器端、网页端、移动APP应用端等,并且可以使用数据库进行简单的处理工作。
1.3 大数据采集的研究分类
1.3.1 智能感知层
包括数据传感体系、网络通信体系、传感适配体系、智能识别体系及软硬件资源接入系统,实现对结构化、半结构化、非结构化的海量数据的智能化识别、定位、跟踪、接入、传输、信号转换、监控、初步处理和管理等。涉及有针对大数据源的智能识别、感知、适配、传输、接入等技术。随着物联网技术、智能设备的发展,这种基于传感器的数据采集会越来越多,相应对于这类的研究和应用也会越来越重要。
1.3.2 基础支撑层
提供大数据服务平台所需的虚拟服务器,结构化、半结构化及非结构化数据的数据库及物联网络资源等基础支撑环境。重点要解决分布式虚拟存储技术,大数据获取、存储、组织、分析和决策操作的可视化接口技术,大数据的网络传输与压缩技术,大数据隐私保护技术等。
1.4 常见的数据采集工具
高可用性、高可靠性、可扩展性是日志收集系统所具有的基本特征。常用的日志系统有Hadoop的Chukwa、Cloudera的Flume、Facebook的Scrible和LinkedIn的Kafka这些工具大部分采用分布式架构,来满足大规模日志采集的需求
 1.4.1 Chukwa
1.4.1 Chukwa


1.4.2 Flume

1.4.3 Scribe

1.4.4 Kafka

1.4.5 网络数据采集方法
“网络数据采集”是利用互联网搜索引擎技术对数据进行针对性、行业性、精准性的抓取,并按照一定规则和筛选标准进行将数据进行归类,形成数据库文件的一个过程。互联网网络数据是大数据的重要来源之一通过网络爬虫或网站公开API等方式可以将非结构化数据从网页中抽取出来,将其存储为统一的本地数据文件,并以结构化的方式存储。
1.4.6 数据库采集
一些企业会使用传统的关系型数据库MySQL和Oracle等来存储数据。这些数据库中存储的海量数据,相对来说结构化更强,也是大数据的主要来源之一。其采集方法支持异构数据库之间的实时数据同步和复制,基于的理论是对各种数据库的Log日志文件进行分析,然后进行复制。
2 大数据预处理

2.1 导入/预处理
虽然采集端本身有很多数据库,但是如果要对这些海量数据进行有效的分析,还是应该将这些数据导入到一个集中的大型分布式数据库或者分布式存储集群当中,同时,在导入的基础上完成数据清洗和预处理工作。也有一些用户会在导入时使用来自Twitter的Storm来对数据进行流式计算,来满足部分业务的实时计算需求。
现实世界中数据大体上都是不完整、不一致的“脏”数据,无法直接进行数据挖掘,或挖掘结果差强人意,为了提高数据挖掘的质量,产生了数据预处理技术。
2.2 数据清洗
数据清洗时发现并纠正数据文件中可识别的错误的最后一道程序,包括对数据一致性的检查,无效值和缺失值得处理。
数据清洗的原理是利用有关技术如数据挖掘或预定义的清理规则将脏数据转化为满足数据质量要求的数据。
 2.3 数据的清洗方法
2.3 数据的清洗方法
 2.4 数据集成
2.4 数据集成
数据集成是将不同应用系统、不同数据形式,在原应用系统不做任何改变的条件下,进行数据采集、转换好储存的数据整合过程。其主要目的是在解决多重数据储存或合并时所产生的数据不一致、数据重复或冗余的问题,以提高后续数据分析的精确度和速度。
2.5 数据转换
数据转换(data transfer)时采用线性或非线性的数学变换方法将多维数据压缩成较少维的数据,消除他们在时间、空间、属性及精度等特征表现方面的差异。实际上就是将数据从一种表示形式变为另一种表现形式的过程。
数据转换方法:



2.6 数据归约
数据归约技术可以用来得到数据集的归约表示,它很小,但并不影响原数据的完整性,结果与归约前结果相同或几乎相同。所以,我们可以说数据归约是指在尽可能保持数据原貌的前提下,最大限度地精简数据量保持数据的原始状态。
数据归约分类:
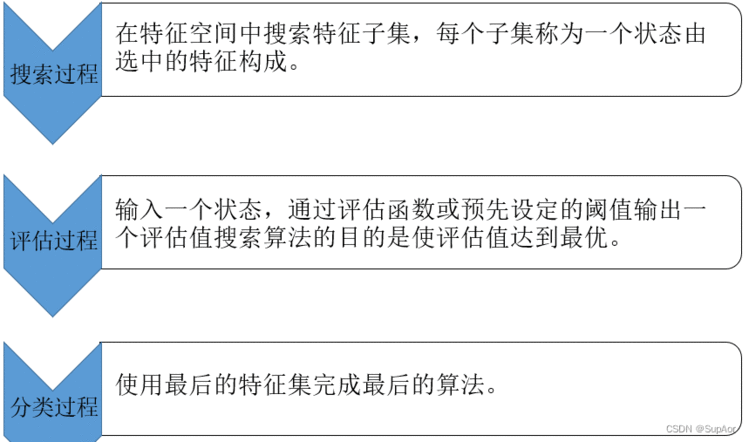
 特征值规约算法三个步骤:
特征值规约算法三个步骤:
3 常用ETL工具
ETL(Extract-Transform-Load)是一种数据仓库技术,即数据抽取(Extract)、转换(Transform)、装载(Load)的过程,其本质是数据流动的过程,将不同异构数据源流向统一的目标数据。
ETL转换过程:

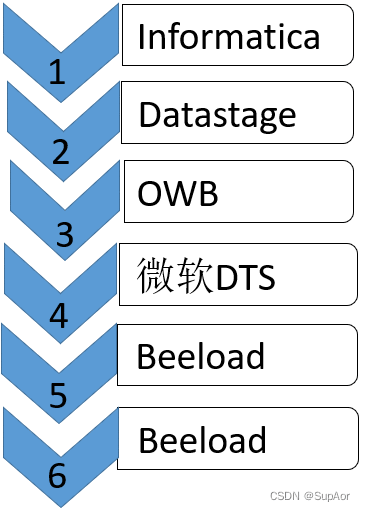
典型ETL工具:
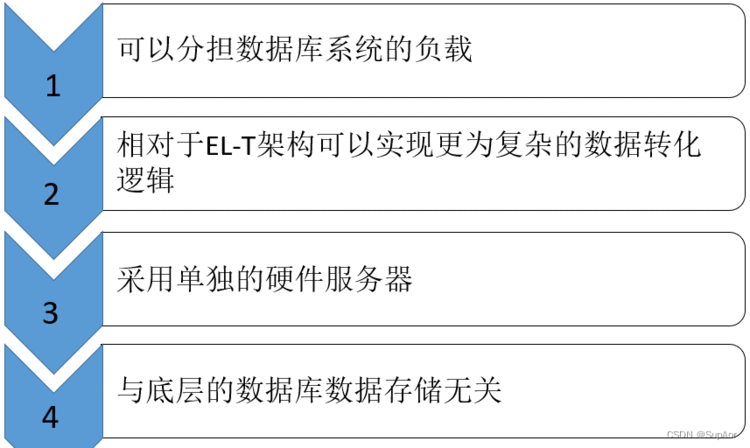
ETL架构优势:









 京公网安备 11010802041100号
京公网安备 11010802041100号