大家好,我是kaiyuan。今天一起来看百度KDD2021的一篇工作,关于工业界语义检索召回系统,落地场景非常值得借鉴~
先简单介绍一下论文要解决的任务,「根据用户搜索的query,从千亿级别的候选池中筛选出一定量的满足用户要求的网页doc」 。也可以简单理解为NLP中的文本匹配任务,但是一旦涉及真实数据和工业应用场景,就会复杂很多。
关于信息检索和网页搜索,更详细的可以参考我们之前的综述文章:
先验知识 最近特别有感触,找到问题所在比找到答案更重要。来看看当前网页搜索面临的主要挑战:
「语义匹配」 :这无疑是搜索最需要关注和解决的一块。目前query的形式多样化与口语化,像一些传统的靠词之间的硬匹配算法,很容易就错过同义表达;并且,query和doc两者长度另外,除了query和doc这两个客观的实体,更进一步的话还需要考虑用户的偏好,这在电商搜索中尤为重要。
「数据分布」 :在搜索中,大多数的query和doc对于搜索引擎来说都是第一次见的,如何让模型很好地解决这种长尾数据。
「工程部署」 :召回系统面向的是千亿级别的候选池,如何在保证模型效果的同时兼顾线上效率,毕竟用户体验才是产品的第一位。
长期follow我们内容的同学应该对上述问题都已经有一些个人基础的解法,下面来看看搜索巨头百度是如何做的。另外推荐一些下文所涉及的先验知识:
NLP预训练模型
万字梳理!BERT之后,NLP预训练模型发展史
NLP预训练家族 | Transformer-XL及其进化XLNet
芝麻街跨界NLP | 预训练模型专辑(三)
芝麻街跨界NLP,没有一个ERNIE是无辜的
详解ERNIE-Baidu进化史及应用场景
信息检索与文本匹配:
模型细节 任务目标是建模 query-doc之间的 「相关性匹配」 (注意与「语义匹配」 的区别)
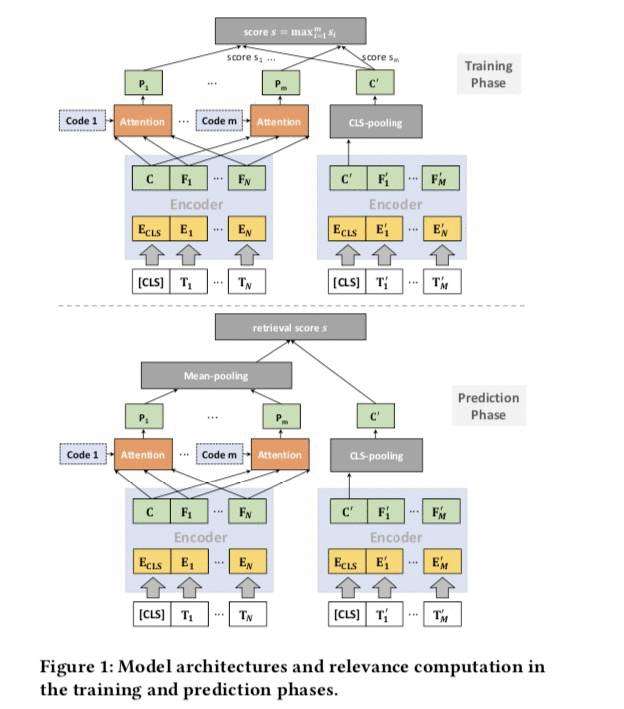
模型骨架是ERNIE,最近出了一波ERNIE-3,不知道有没有更新安排上。双塔是工业届召回的标配,另外顶层交互方式参考了poly-encoder的模式,如下图。训练和预测阶段会有一点不同:
模型的细节参考poly-encoder:
由于上线性能的要求,计算相关性得分时在模型训练和预测阶段不一样:
数据挖掘 数据作为模型的上限,自然是非常重要。搜索系统实际数据来源主要是:
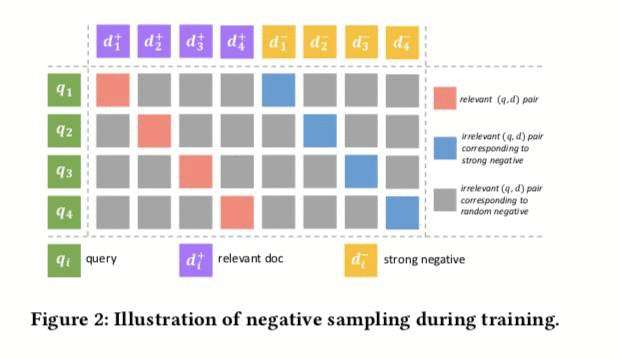
上述样本作为hard negative,由于召回是从大量不相关doc中找到非常小部分的相关doc(
easy negative,即在同一batch中随机sample。最终batch训练正负样本数据如下
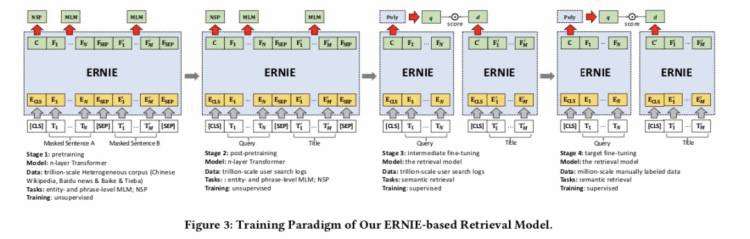
训练范式 为了让更多的领域知识融入模型,让模型具有更好的泛化性能,设计了多阶段训练模式。整个训练过程分四步:
「ERNIE 通用预训练」 :单塔,NSP+MLM任务,用于热启动;
「ERNIE 领域预训练」 :数据为一个月的搜索日志,query + title,单塔,输入格式[CLS] QUERY [SEP] TITLE [SEP],仅仅是训练数据与Vanilla ERNIE不同;
「ERNIE 一次任务微调」 :搜索日志,query/title,双塔,任务变成分类任务,即从一系列不相关doc中找到正确的相关doc,进一步贴近最终目标;
「ERNIE 二次任务微调」 :精细人工标注数据,query/title,双塔,任务同第三步。
损失优化 工程部署 向量压缩和量化 简单说,压缩就是把768的ERNIE向量通过FC转成256维度,量化就是把float32的变成int8。
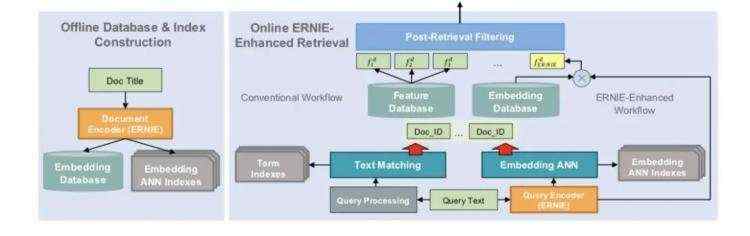
召回框架
离线部分(左侧):计算doc端的embedding,cache保存
在线部分(右侧):分为召回和排序。召回部分又包括传统query特征计算,以及ERNIE-query向量计算。ERNIE-query-emb和ERNIE-doc-emb计算相似度打分,与传统特征一起作为上层排序的特征。注意这里的排序是召回系统内部的排序,不属于搜索大框架下的排序模块,目的是进一步缩小优化召回候选集,模型为RankSVM或GBRank;
一起交流 想和你一起学习进步!『NewBeeNLP』 目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定要备注信息 才能通过)
- END -
聊一聊大火的对比学习
2021-08-12
百度提前批算法工程师面筋!效率有、高
2021-08-09
Focal Loss --- 从直觉到实现
2021-07-28
动荡下如何自救 | 社招一年收割BATDK算法offer
2021-07-27

















 京公网安备 11010802041100号
京公网安备 11010802041100号