作者:mobiledu2502934573 | 来源:互联网 | 2023-09-07 12:10
前言 hi~大家好,今天分享一下微服务/分布式常见的面试问题,不过这些问题都是针对应届生的,对于比较senior的求职者应该会深入很多。题目都是来自2021大厂真实面经!
没有了解过分布式/微服务的老哥们也不要担心看不懂这篇文章,内容我都是大白话讲出来的,非常易懂,带你速览分布式/微服务。
文末有福利,记得查看哦!
概览(看看自己能回答几题):
1.为什么要网关?
1.为什么要网关? 微服务下一个系统被拆分为多个服务,但是像 安全认证,流量控制,日志,监控等功能是每个服务都需要的,没有网关的话,我们就需要在每个服务中单独实现,这使得我们做了很多重复的事情并且没有一个全局的视图来统一管理这些功能。
综上:一般情况下,网关一般都会提供请求转发、安全认证(身份/权限认证)、流量控制、负载均衡、容灾、日志、监控这些功能。
上面介绍了这么多功能实际上网关主要做了一件事情:**请求过滤 。**权限校验、流量控制这些都可以通过过滤器实现,请求转也是通过过滤器实现的。
2.你知道有哪些常见的网关系统? 我所了解的目前经常用到的开源 API 网关系统有:
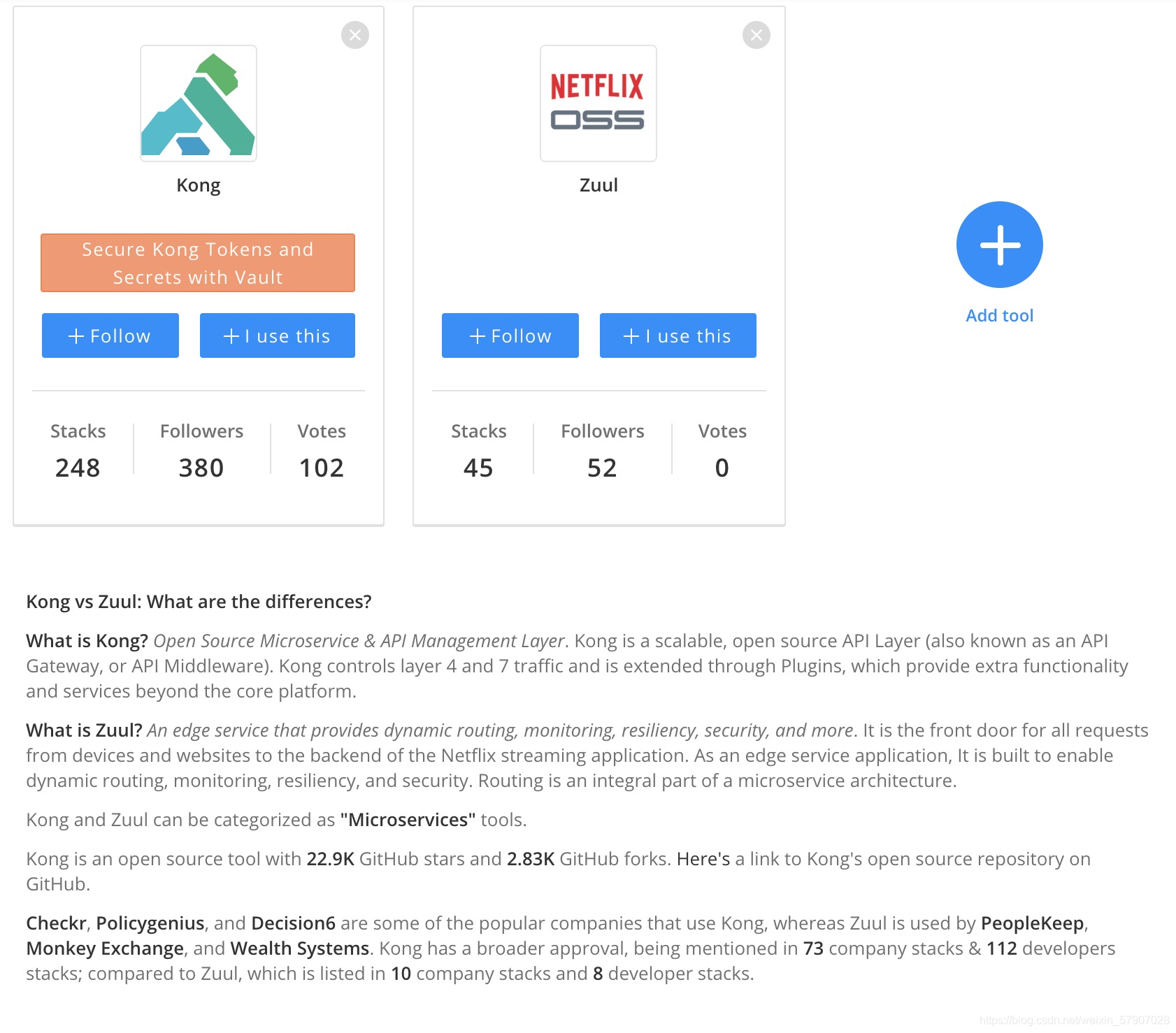
下图来源:https://www.stackshare.io/stackups/kong-vs-zuul
可以看出不论是社区活跃度还是 Star数, Kong 都是略胜一筹。总的来说,Kong 相比于 Zuul 更加强大并且简单易用。Kong
OpenResty(也称为 ngx_openresty)是一个全功能的 Web 应用服务器。它打包了标准的 Nginx
通过揉和众多设计良好的 Nginx 模块,OpenResty 有效地把 Nginx 服务器转变为一个强大的 Web
另外, Kong 还提供了插件机制来扩展其功能。
比如、在服务上启用 Zipkin 插件
$ curl - X POST http: / / kong: 8001 / services/ { service} / plugins \-- data "name=zipkin" \-- data "config.http_endpoint=http://your.zipkin.collector:9411/api/v2/spans" \-- data "config.sample_ratio=0.001"
ps:这里没有太深入去探讨,需要深入了解的话可以自行查阅相关资料。
3.限流的算法有哪些? 简单介绍 4 种非常好理解并且容易实现的限流算法!
下图的图片不是桃子自己画的哦!图片来源于 InfoQ 的一篇文章《分布式服务限流实战,已经为你排好坑了》。
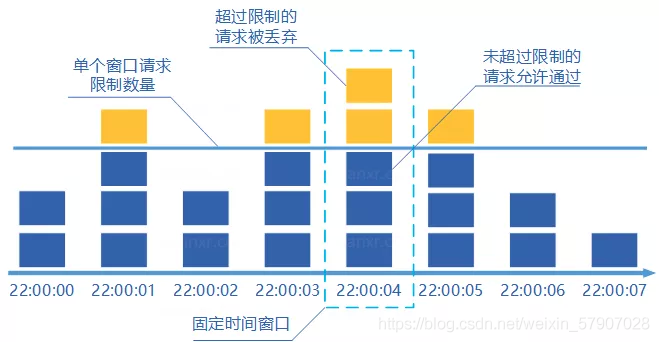
固定窗口计数器算法
规定我们单位时间处理的请求数量。比如我们规定我们的一个接口一分钟只能访问10次的话。使用固定窗口计数器算法的话可以这样实现:给定一个变量counter来记录处理的请求数量,当1分钟之内处理一个请求之后counter+1,1分钟之内的如果counter=100的话,后续的请求就会被全部拒绝。等到 1分钟结束后,将counter回归成0,重新开始计数(ps:只要过了一个周期就讲counter回归成0)。
这种限流算法无法保证限流速率,因而无法保证突然激增的流量。比如我们限制一个接口一分钟只能访问10次的话,前半分钟一个请求没有接收,后半分钟接收了10个请求。滑动窗口计数器算法
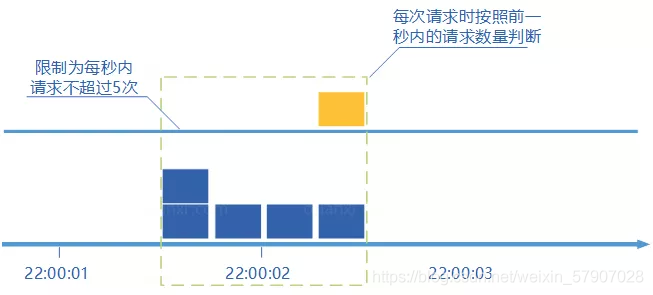
算的上是固定窗口计数器算法的升级版。滑动窗口计数器算法相比于固定窗口计数器算法的优化在于:它把时间以一定比例分片。例如我们的借口限流每分钟处理60个请求,我们可以把 1 分钟分为60个窗口。每隔1秒移动一次,每个窗口一秒只能处理 不大于 60(请求数)/60(窗口数) 的请求, 如果当前窗口的请求计数总和超过了限制的数量的话就不再处理其他请求。
很显然:当滑动窗口的格子划分的越多,滑动窗口的滚动就越平滑,限流的统计就会越精确。漏桶算法
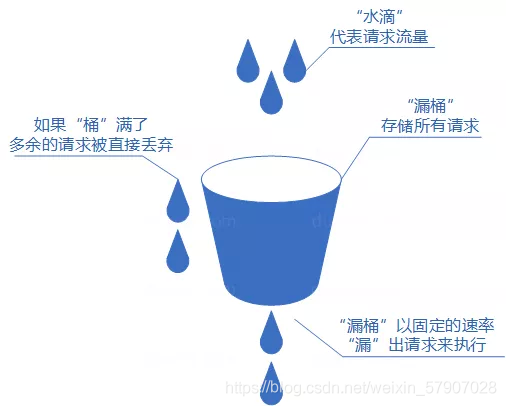
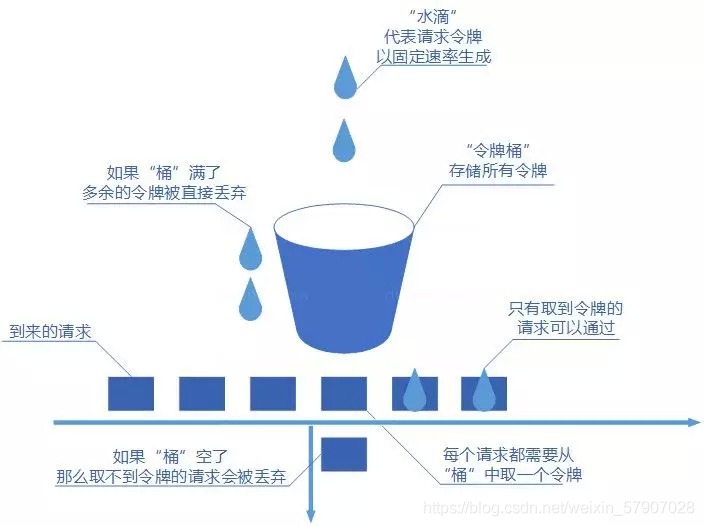
我们可以把发请求的动作比作成注水到桶中,我们处理请求的过程可以比喻为漏桶漏水。我们往桶中以任意速率流入水,以一定速率流出水。当水超过桶流量则丢弃,因为桶容量是不变的,保证了整体的速率。如果想要实现这个算法的话也很简单,准备一个队列用来保存请求,然后我们定期从队列中拿请求来执行就好了。令牌桶算法
令牌桶算法也比较简单。和漏桶算法算法一样,我们的主角还是桶(这限流算法和桶过不去啊)。不过现在桶里装的是令牌了,请求在被处理之前需要拿到一个令牌,请求处理完毕之后将这个令牌丢弃(删除)。我们根据限流大小,按照一定的速率往桶里添加令牌。
4.为什么要分布式 id ? 这部分内容来自:分布式id生成方案总结
ID是数据的唯一标识,传统的做法是利用UUID和数据库的自增ID,在互联网企业中,大部分公司使用的都是Mysql,并且因为需要事务支持,所以通常会使用Innodb存储引擎,UUID太长以及无序,所以并不适合在Innodb中来作为主键,自增ID比较合适,但是随着公司的业务发展,数据量将越来越大,需要对数据进行分表,而分表后,每个表中的数据都会按自己的节奏进行自增,很有可能出现ID冲突。这时就需要一个单独的机制来负责生成唯一ID,生成出来的ID也可以叫做分布式ID ,或全局ID 。
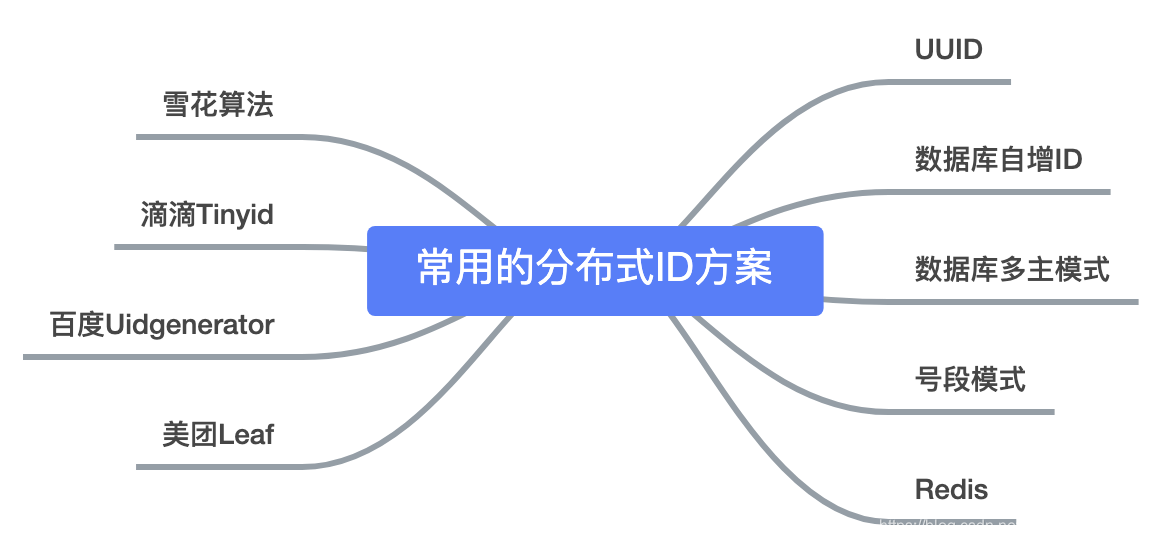
5.分布式 id 生成策略有哪些?
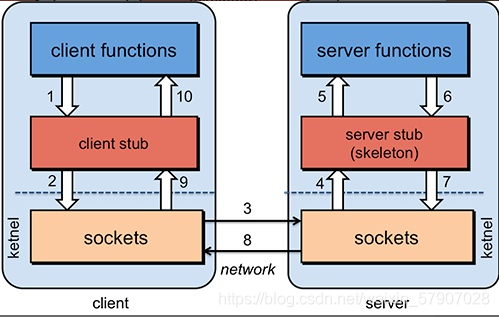
6.了解RPC吗? RPC(Remote Procedure Call)—远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。比如两个不同的服务 A、B 部署在两台不同的机器上,那么服务 A 如果想要调用服务 B 中的某个方法该怎么办呢?使用 HTTP请求 当然可以,但是可能会比较慢而且一些优化做的并不好。 RPC 的出现就是为了解决这个问题。
RPC原理是什么?
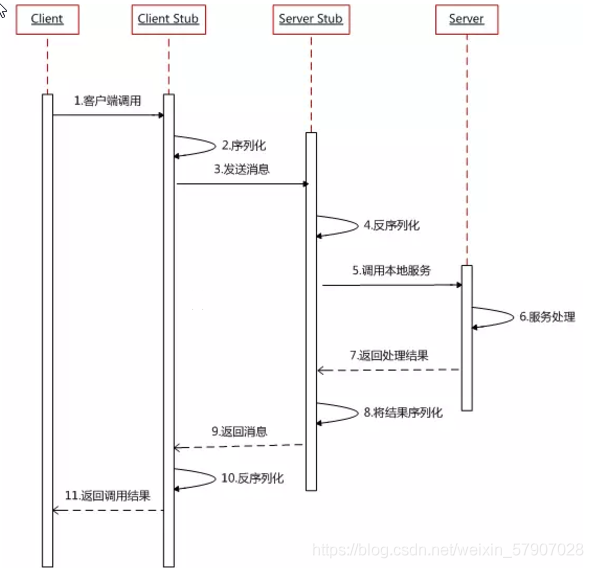
服务消费方(client)调用以本地调用方式调用服务; client stub接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体; client stub找到服务地址,并将消息发送到服务端; server stub收到消息后进行解码; server stub根据解码结果调用本地的服务; 本地服务执行并将结果返回给server stub; server stub将返回结果打包成消息并发送至消费方; client stub接收到消息,并进行解码; 服务消费方得到最终结果。 下面再贴一个网上的时序图:
结语 好啦~今天的文章就更新到这里啦!如果觉得本文对你有帮助,记得三连一下哦!最近我也整理了一份面试大全,如果有需要可以点开下方文档领取!
最全学习笔记大厂真题+微服务+MySQL+分布式+SSM框架+Java+Redis+数据结构与算法+网络+Linux+Spring全家桶+JVM+高并发+各大学习思维脑图+面试集合









 京公网安备 11010802041100号
京公网安备 11010802041100号