作者:拍友2702938227 | 来源:互联网 | 2023-06-09 14:12

(扫描图片二维码,回看公开课精彩视频)
数字化浪潮席卷全球。在这个一切皆可智能化的时代,数据正在成为产业发展基本业务单元和重要资产,数据经营能力也成为了企业发展的关键能力。
数据智能通过分析数据获得价值,将原始数据加工为信息和知识,进而转化为决策或行动,已成为推动数字化转型不可或缺的关键技术。如何利用数据来满足未来更加多维的业务场景需求,成为企业业务能否推进所必须解决的问题。
面对此问题,近日滴普科技FastData产品线总裁杨磊开启了《数据智能技术前沿与挑战——以开放心态迎接高密度数据场景新挑战》演讲,我们或许能从中探寻一二。
数据平台工程化成为企业发展关键
伴随5G、大数据、AI、IoT的发展,数据呈现大规模、多样性的极速增长态势。为了应对多变的业务诉求,高密度数据应用场景对于数据平台提出了新的要求。
在数据类型方面,新兴业务场景不断涌现,非结构化、半结构化的数据逐渐增多,单一的数据库已难以匹配日益增长的数据复杂度需求。而且,现在整个数据密度的发展非常快,很多企业中已经从几百GB数据变成PB级别的数据处理场景。数据趋势方面,从来源的多样化、数据量和数据类型增多,向云化方式提供的数据服务趋势演进。
除了以上几种情况,在数据处理方面也面临着变化。传统的大数据架构技术复杂。例如:在实际应用过程中,多种数据类型扩展方面非常困难;流式处理实时性差;难以适应多云、混合云等不同的基础设施;集群升级和运维困难,为企业业务带来了IT架构扩展难的问题。
“随着技术及应用的发展,现代数据架构正在往流批一体、湖仓一体方向演进。”杨磊讲到,主要体现在四点:第一,数据类型可扩展,多模态,需要结合存算分离模式使得计算从数据中“解放”出来。第二,端到端的流式处理能力,也逐渐成为企业在生产和运营过程中所需要的能力之一。第三,基于云原生容器化技术的应用,需要做到的是如何通过云原生的方式能够简化部署,实现跨云服务能力。最后就是数据的完整性问题,治理体系能力的建设是否完整。
正是基于这些要求,在数据架构方面,企业需要建立许多不同的架构平台,如数据仓库、数据工程、流处理,和数据科学/ML来处理不同的数据工作,由于它们是不同的技术,通常不能良好地协同工作。
在企业业务发展的过程中,IT架构也在不断增大及复杂化。在这个过程中,业务方面需要某一个数据时,就需要多种角色的技术人员来处理,而这些角色也可能面临着相互重叠的可能性。一系列的问题就导致,企业在使用数据的过程中,变得非常低效和困难。
面对数据类型多,平台能力多及基础设施多的三大挑战下,针对数据平台工程化方面创新发展上的要求,杨磊分别从数据特点、技术债务、平台能力、扩展和演进四个方面做了阐述。
以数据特点为例,数据的时效性正逐渐从T+1到T+0的方向发展,在数据类型方面,半结构和非结构正成为主流。正如前文所提到的,现在的数据存量和数据增量成指数级增长。
湖仓一体是核心,分层能力是关键
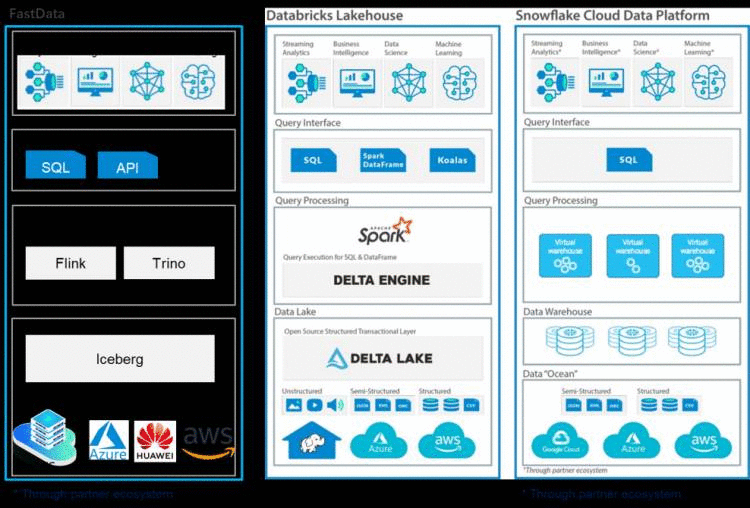
课程中,杨磊通过几个典型企业数据平台为我们介绍了业内不同类型的数据平台形态。首先就是Snowflake 。Snowflake 是从先建数据仓库,之后再向数据湖延伸。从原先解决结构化数据能力向半结构化数据能力演进。把ML能力集成到数仓中,来解决一些ML相关联的一些操作。
Databricks作为数仓一体的代表,它是基于Databricks引擎统一的数据湖,基于数据湖构建数据仓库。因数据湖具有分析能力,就能轻松解决结构化、半结构化和非结构化的数据的一些问题。同时加入多种引擎,可以实现统一SQL、Spark Dataframe和Keales。
FastData 是滴普科技推出的云原生数据智能平台,它和Snowflake Cloud Data Platform是同一种方式。先建立数据湖能力,通过在数据湖上面建立数据仓库,底层是利用Iceberg进行一个能力提升,中间层是应用Flink和Trino能力。而且,FastData 是全面拥抱开源的。
杨磊讲到,从三个数据平台形态可以看出,最终都是归为数仓一体。不仅如此,不同的数据平台产品,从存储引擎、多样性计算引擎,到最后的查询接口,也都体现出一个分层能力。
FastData:一站式云原生数据智能平台
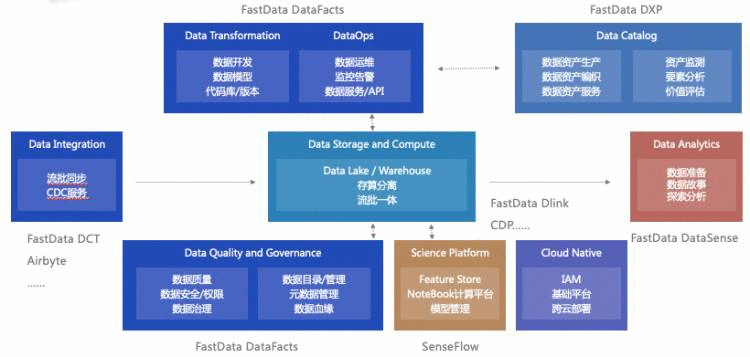
FastData,主要是服务于企业建立流批一体和湖仓一体的数据存储计算平台和数据科学分析平台。

FastData采用了分层架构,主要由实时PB级数据引擎DLink、数据智能开发平台DataFacts、数据科学分析平台DataSense,以及数据资产管理和运营平台DXP组成。整个架构的目标就是有效保障稳态业务规模化数据分析场景和敏捷业务的创新数据分析场景。
杨磊介绍到,作为FastData的核心数据引擎DLink,它基于 Iceberg、Flink 和Trino 技术栈,提供多种数据类型的统一存储能力,支持高质量的流批一体数据整合,包括海量数据存储处理、多样数据格式与来源、新数据高速产出、数据解释可变性高、数据遵循流畅一致性强、可供消费数据波动性高等特点。
DLink融合了实时数仓和数据湖服务,采用存算分离架构,弹性扩容、高并发、低延时,支持PB级多模数据存储与处理,无缝连接大数据生态,提供一站式的数据探索、实时开发、数据分析和数据科学/ML,满足BI、实时看板等应用需求。
从开源中来,到开源中去
我们知道,开源虽然解决了功能性问题,但工程性问题并没有得到解决。杨磊表示,滴普在进行专业的数据工程化创新的同时,也在拥抱开源生态,致力于打造 DEEPNOVA 开发者社区。
DEEPNOVA 开发者社区是面向技术开发者的交流学习、生态共创平台,目的是促进圈层交流,学习互助,开拓技术视野;建立技术生态,合作共赢。DEEPNOVA 是由 DEEPEXI+SUPERNOVA 组合而成,包含了滴普科技的“建社心愿”—— 滴普科技为技术开发者打造的一颗超新星。
杨磊讲到,DEEPNOVA希望打造的湖仓一体平台能够开放给DEEPNOVA 社区,大家能够有更多的发挥空间,能够利用DEEPNOVA的开源产品解决实际的场景落地问题。目前DEEPNOVA已经将Iceberg、Flink和Trino等内部已实现的优势能力提供出来,帮助社区用户解决社区版本在面向商业应用的过程中所遇到的痛点问题。

正是基于开源的底层逻辑,DEEPNOVA提出了open data stack概念。杨磊解释道,DEEPNOVA认为数据能力是要全面开放的,包括数据集成能力、数据存储、数据运维等。全面开放的好处就是能够让更多的社区用户一起协作发现问题、解决问题,并且帮助社区用户在他们的商业项目和研究中发挥作用。“这也是open data stack的初衷!”杨磊说道。
我们不难发现,在“数据 + 算力 + 算法”定义的新时代,数据已成为企业核心价值的新定义。谁拥有了数据,谁就拥有了未来!企业只有当数据和应用能够灵活运用时,才能实现真正的商业价值。







 京公网安备 11010802041100号
京公网安备 11010802041100号