讲师介绍

代海鹏
新炬网络资深数据库工程师
分享大纲:
-
面对数据泄密,DBA能做什么?
-
面对数据丢失,DBA能做什么?
-
数据库备份及演练
我把数据的安全事件简单分为两类,第一类是泄密事件,第二类是数据丢失事件。
先说说近年来影响比较大的数据泄密事件:
-
洲际酒店在内的10大酒店泄密大量客人开房的信息包括姓名、身份证被泄密,直接导致客人量下降;
-
下一个是韩国2000万信用卡信息泄露,引发“销户潮”;
-
某网数据泄漏,全国各地有39名用户被骗,诈骗金额高达140多万。像这类数据泄露,如果你的亲属朋友是被骗人之一,我相信感受一定与光看数字的感触不同;
-
某贷宝被脱裤,导致10G裸条泄露。
再说说近期影响较大的数据丢失事件:
-
Gitlab99%数据丢失:1月份时,某外国工程师对自认为是空文件夹的文件夹做了一个删除,过了两秒他反应过来了,我是不是搞错服务器了,后果是几百G的数据文件被删得就剩下3个G;
-
炉石传说30%数据丢失:有4人在1月份提议把1月份作为数据安全月,也不至于。这是怎么回事呢?炉石传说的数据库哥们带病运行了两天以后又回滚到故障以前,导致几天的数据全部丢失。这里我们不去深究到底什么技术原因导致竟然无法修复。
对此,我想说的是:我们的运维团队并没有我们想象中那么牛逼,所以我们要对生产抱有敬畏之心。
一、面对数据泄密,DBA能做什么?
1、用户管理
清理和锁定无用的数据库帐号。进了一个新环境,核心库账户是必查项。
select b.username,a.sql_id ,count(*)from
DBA_HIST_ACTIVE_SESS_HISTORY a,dba_users b where a.user_id=b.user_id
group by b.username,a.sql_id
order by count(*);
-
如果无法抓出相关信息,这时候就进行汇报,然后申请锁定用户。
-
11G有非常多的用户,附件word 有其中最常见的31个用户的详细信息,包括用户名字以及这个用户是哪个Oracle默认组件会使用到的。

(点击文末链接下载查看)
2、用户Profile
除了用户本身以外,还有用户的profile要进行检查,首先就是密码的验证算法,11G默认是没有算法的,我们要用脚本@?/rdbms/admin/utlpwdmg.sql创建名叫VERIFY_FUNCTION_11G的验证函数。
VERIFY_FUNCTION_11G函数验证项如下:
profile中有两类属性:
-
第一类是资源控制,控制逻辑读、SGA、空闲会话存活时长等等。这一类需要将参数resource_limit设置为TRUE才能生效;
-
第二类是密码策略,包括 错误几次、密码失效、密码可重用周期、最多可重用次数、验证函数、密码锁定时间、到期后缓期执行等,该类型无需resource_limit参数配置。
3、权限管理
权限管理很简单,就是最小化原则。
最小化应用账户,在工作中我个人经验为默认给开发及应用账户的权限,就connect、resource、创建视图的权限即可。
reousrce的权限是有很多,可以创建视图,我只给这么多,如果你还想要别的,可以向DBA团队申请,DBA团队来给你审批。然后是数据库字典,普通用户禁止访问。为了禁止普通用户的访问可以用下面的07-DICTIONARY-ACCESSIBILTY进行限制。安全和便利总是相对的,越安全,那么操作起来就越复杂,所以说这里是否进行限制就见仁见智。我们可以把权限汇集成Role,一类应用所需的权限可以归类为一个单独的role,以后只要是类似应用上线不要再管理。而应用下线也可以通过Role快速回收对应权限。通过Role赋权是我的建议之一。
最小化DBA权限用户,一种是操作系统上面DBA组,其中操纵系统帐号最好就Oracle一个,因为DBA组所属用户可以通过操作系统验证直接以sysdba的权限登录到库里。另外一种,数据库里面有DBA角色,或者有大权限的帐号也一定要审查一下,如果有可疑的账户虽然没有DBA角色,但相关的权限却全部拥有的,更是一定要进行检查核对。
4、日志管理
日志管理主要是说审计,在后面发现问题时可以快速知道是之前谁做的操作。我们可以把审计配置好以后关闭审计,如果某天系统已经上生产后老板说你给我把这个库审计一下,我们只需一条命令就可以审计了,不需要再做一系列配置及资源申请。
审计涉及的参数:
有几点注意事项:
11G新参数ENABLE_DDL_LOGGING,开这个参数可以在alert日志中记录所有的DDL语句,不过记录的内容相对简单,只有时间和语句。
在11.2.0.4之前,这个功能是有bug的,rename操作是不做记录的。
到12C 这个参数更加完善了,如图右,除了语句以外 还有IP 、机器名等信息,在我们不开审计的情况下,也能获取DDL执行信息。
5、漏洞管理
及时的升级对应的PSU,尤其是修复的重要安全bug的PSU。
关于漏洞,我简单地贴了一个文章,1454618.1。

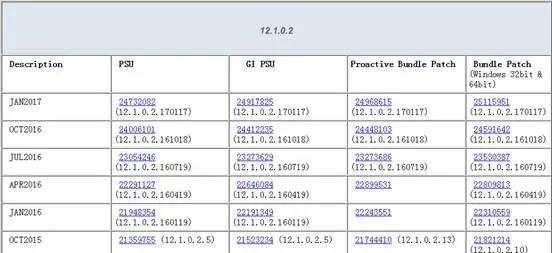
上面有很多数据都可以通过MOS文章一把拉出来。讲这个的主要原因是强调我们要紧跟着自身版本的PSU,这个不代表说本月发布的PSU,我们必须本月升级,而是应该有计划进行升级。比如以延迟半年为计划,或者延迟一个季度为计划。除了这方面,还有业内会经常爆出一些严重BUG,如像DBAplus这样的社群是会第一时间发出声明及处理方案,我们一定要时刻关注,不能等问题真的到我们头上了才知道,那样公司请你就没有价值了。
以上所述都是应对数据泄密的措施。简单来说,我认为数据泄密方面DBA和运维人员只是做了辅助作用,因为很多公司会有自己的安全团队,会从外面请一些公司去做整体的扫描,会给出一系列建议、配置性的更改,我们只需要针对数据库这方面调整,就够了。
前面说那么多东西是为什么呢?大家都知道了,去年下半年有比特币勒索,大家在网上了下载了一些破解工具,如PLSQL DEV、SCRT等,有一部分工具被放置恶意的脚本,然后当你通过很大的权限(如SYSDBA)连接到数据库,这些工具会自己创建一个存储过程,存过名字起跟真的一样,里面还给你加密。一定时期以后(如三年)这个函数会自己执行,把你的数据全部搞乱搞废掉,然后会在报错信息里面提供包含比特币链接的勒索信息,大致意思是你给我钱,我就给你把数据库恢复。
那么我们前面做的,收用户、收权限,就是保证,当我们DBA自身使用的工具是安全的情况下就能保证数据库不受勒索。如果你大的权限在下面飘着,就不能保证研发、应用的哥们究竟安全意识如何,到时候连防都不好防。
如果面对数据泄密是DBA是辅助类工作的话,面对数据丢失,DBA有无法推卸的责任,这个“锅”你是甩不出去的。
二、面对数据丢失,DBA能做什么?

在平时运行维护时,总会有种种情况导致业务数据丢失或者损坏,无论丢失是多是少,我们DBA都应该尽量避免发生。
下列是我们平时遇到的4种可能会造成数据丢失的类型:
-
系统故障: CPU、内存、主板、等主机层面的故障
-
存储故障:UPS掉电、控制器损坏、物理硬盘损坏等
-
数据库BUG:因触发数据库BUG导致刷入存储的数据块逻辑损坏
-
人为操作故障,错误执行删除数据命令
就Oracle本身来讲,它有自己的高可用体系产品及功能。
1、应对主机层面的故障
这种故障正常来说是丢失未提交的数据,大部分情况我们是无需在意这些丢失数据的。这时候主要以恢复业务为目的来设计数据。我们通过使用主机层面高可用技术RAC,来解决这个问题,主机层面高可用指,两套内存、CPU等运算资源,但是使用同一套数据文件。当RAC中某主机损坏时,业务可以在下次连接的时候连入另外的节点。
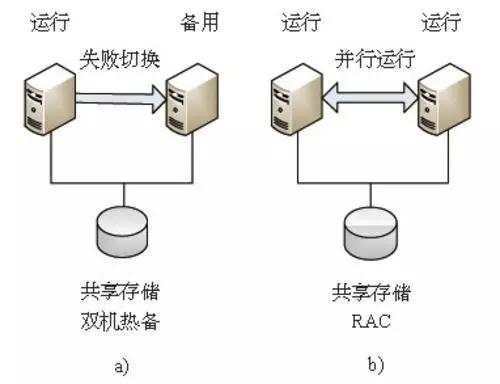
在Oracle 9i之前,RAC的名称叫做OPS,而9i之前每次传输块的时候,需要先将数据刷入硬盘,然后另外的节点从硬盘上读取。
RAC进化的最重要的一点,就是有了CACHE-FUSION的特性,最新的当前块数据可以通过私网进行传输了。
使用RAC的注意点:
-
尽量减少cache-fusion,通过应用切割的模式;
-
第二个注意点,CPU、内存这些计算资源,最好不要上60,相对内存来说,CPU更是。如果平时跑每个节点的CPU就飙上60%,那么当发生故障的时候,存活节点是不是能抗住是要打问号的;
-
如果资源吃紧,提前对业务进行提前梳理这套库上面哪些业务是重要的,哪些业务是较为不重要的,哪些最不重要。便于紧急时刻可停止非关键业务释放资源供给核心业务。
2、应对存储层面发生故障或损坏
这个层面的故障和损坏RAC是无法保护的,因此Oracle提供了DG进行存储保护。
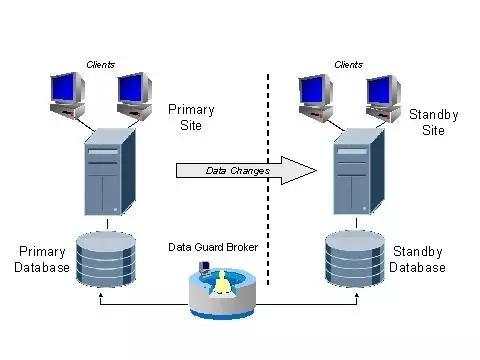
当存储出现故障的时候,丢失多少数据都是有可能的,这时候如果DG存在,我们可以激活备库,将应用的IP调整为备库及时的恢复应用,并且可以做到尽量不丢失数据,这里可以给大家分享的经验是,建立内网域名服务器,将IP都设置为对应的域名,以后发生容灾切换的时候 只需要调整域名服务器的映射即可,无需每个应用单独调整。
在11G以后DG的standby端可以以readonly的模式进行打开,并对外提供只读服务。这也是尽量将物理资源利用起来。
3、应对BUG导致的数据丢失
两种情况,一种是归档好着,只是刷块的时候有问题,导致刷坏了。这种普通DG就可以搞定,另外一种归档被写坏,而传到standby 应用也会导致备库数据块坏掉。
这时候我们就需要讲DG进行延时应用,注意这里只是延时应用,日志还是会自动传输的。哪怕生产坏掉了,除了需要追一定时间的归档外,不会有数据丢失,延时语句如下:
alter database recover managed standby database delay 120 disconnect from session;
120的单位是分。
这里2小时只是代表standby 和生产端真实时间差距,并不代表生产发生down机, standby 必须两个小时才能追平归档。
4、应对误操作
说实话靠个人是很难避免的,谁都有个精神不好的时候,犯迷糊的时候。这时候就需要通过规范和制度来保证这种事情不发生。
经验分享:
-
一定要有变更方案,详细列出每条要执行的命令,并且多人评审;
-
具体实施过程中,除非排障,否则命令一律不得手敲;
-
执行危险命令时,一定要ifconfig 查看一下IP,以防万一;
-
生产和测试环境的窗口不要同时打开,如果非要打开,命名对应窗口,并使用不同的文字背景;
-
变更方案要有对应的回退方案,如果执行变更的时候出现了问题,当时如状态并不好,建议直接回退,不要勉强自己排错。
三、数据库备份及演练
作为一个DBA,如果想要睡得踏实,那么备份一定要有。
当前数据库中数据越来越大,几十T的库屡见不鲜,有时候可能真的没那么大空间做演练 。经验小分享:调整备份手段,将业务表空间分散开,每份单独与system sysaux等组成一个备份集。分批采用进行全备。
最后验证时可以只验证一份,这样数据量就小很多了。不过很多地方为了保证安全,两地三中心都搞出来了,几十T空间并没有想象中贵,这点投入是完全值得的。
今天分享就到这儿了,希望大家的系统平安,做好防范。谢谢!
Q&A
Q1:有一次客户那边的账户突然锁了,我查了其它的信息表空间,发现并没有因为多次密码登陆错,排除这个情况外还有什么原因?
A1:你说的是资源,profile分口令规则和资源限制,资源限制是需要和resource_limit参数进行配合的。有两种情况,第一种情况是有人直接进行手工锁定,第二种情况是密码试错过多导致被锁定的。
(接上问)
Q2:我的意思是排除密码输错,也不是人为锁的。
A2:到期了。
Q3:到期的时间不是没有限制吗?
A3:资源是没有限制的。
Q4:资源参数没打。
A4:资源参数部分是不生效,跟口令参数是无关的。
Q5:可以告诉我多长时间吗?
A5:默认180天。
Q6:PPT一开始rf删掉以后,我去年做过暴力测试,是可以恢复备份的。国外的那个没有吗?
A6:国外哥们的库是不一样的。他那边有三到四重的备份方案,各种各样的容灾,全部都没有用。最后恢复不是采用正常手段恢复的,是用其它系统的数据传回来的,非常佩服他们把恢复进度在推特上面进行公布,以每小时5%的进度慢慢恢复。当时这篇文章也炒得很火了。
原文发布时间为:2017-04-25
本文来自云栖社区合作伙伴DBAplus








 京公网安备 11010802041100号
京公网安备 11010802041100号