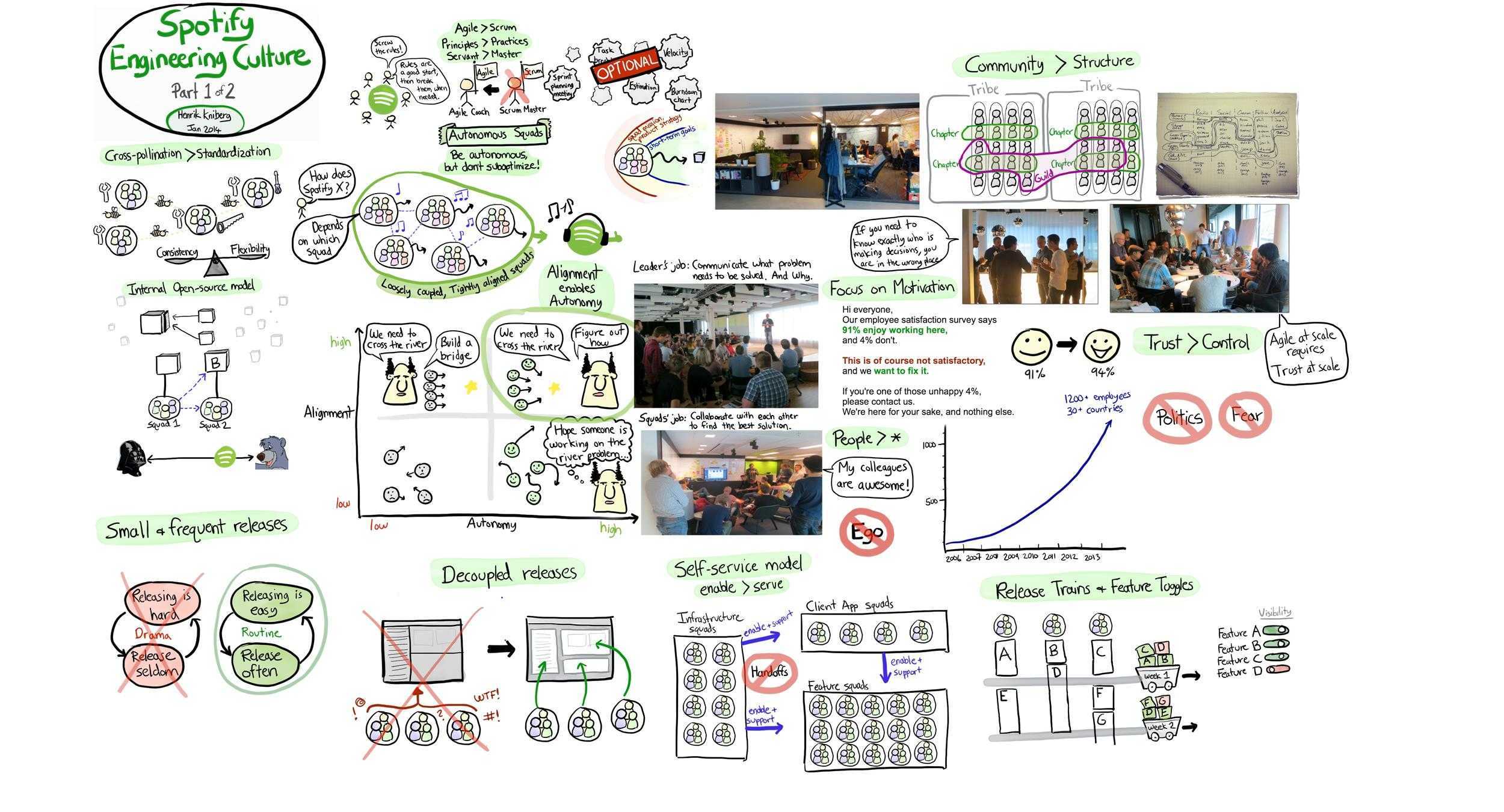
作者:JAYBRYANT-24 | 来源:互联网 | 2023-09-12 15:02
Week 5, Big Data Analytics using Spark
Programing in Spark

Spark Core: Programming in Spark using RDD in pipelines

RDD 创建过后,会有两种操作,Transformation 和 Action. 只有到了Action 阶段才会验证Transformation 操作是否正确,所以经常看到Action阶段有很多报错. 叫 lazy

下图是一个具体的例子. 教程里提到了cache功能,比如从数据库query 数据放到RDD里,这个过程比较耗时,为了防止每次都去执行query操作,我们就可以把第一次的结果cache起来,但是注意使用cache 很耗内存,可能会造成瓶颈..



Spark Core: Transformation
RDD本身不能被改变,只能通过transformtion操作转成一个新的RDD

Map transformation

flatMap transfromation, 一对多
map 和 flatMap 是narrow tranformation. narrow transformation 只依赖于一个partition上的数据,并且 data suffering is not nessary.

Filter transformation

Coalesce transformation, 比如

上面谈的都是narrow transformation, 都是本地处理数据不需要在网络上传输数据。
接下来谈wide transformation

先看看reduceByKey 和 groupByKey 的区别.
groupByKey 需要跨节点的shuffle 操作,输出是一个由 初始数字 1 组成的列表

reduceByKey 其实就是 groupByKey + reduce

narrow transformation 和 wide transformation 区别: 就看有没有跨节点的 shuffle 操作, 也就是有没有跨节点取数据做操作

Spark Core: Actions

第一个Action操作是很常见的collect, 它从worker node 收集最终的结果数据copy到driver node.


其中Reduce 最常用
Main models in Spark eco
Spark SQL
做什么的?优势?



Spark SQL 提供了API可以使query来的data转成 DataFrame

具体怎么做?





Spark SQL summary

Spark Streaming




Spark Streaming summary

Spark MLlib





Spark GraphX







Spark GraphX summary





 京公网安备 11010802041100号
京公网安备 11010802041100号