本文很长,谨慎阅读
现在在我们的面前摆着太多的分布式数据库可以让我们选择,那么如果我想先让大家思考一下,如果你来做一次分布式数据库选型,第一件要做的事情是什么呢?这是一个开放式的问题,可以有很多答案,并且可能没有一个最佳的答案,因为每个客户的特点以及需求会有很大的不同。不过如果你是一个一定要选择一个分布式数据库才能解决你的问题的数据库用户,那么,如何回答这个问题就十分重要了。分布式数据库的架构千差万别,功能特点、适用场景也存在很大的不同,因此数据库选型决定了你以后遇到的坑的多寡。如果我来回答这个问题,那么在数据库选型工作中,要做的第一件事情就是深入分析候选数据库的基础架构与特点,不仅仅是要了解某种数据库的长处,而更重要的是要了解某种数据库的弱点。事实上后者是比较难做的,因为没有一个数据库厂商会十分清晰的把自己的缺点都摆在明处,而作为友商,一般也只是会比较含蓄的提出一些他们的竞品与自己的差距。
事实上,我和Mether的观点类似,没有一种数据库是完美的,只要它适合你的业务场景,就放心去用吧,只有大规模用了,你才能在某个数据库上积累足够的应用研发、运维、优化方面的经验,这些才是对某个企业最为关键的。盲目的去深入分析数据库的架构也价值不大,纯粹的技术研究对企业数据库选型并无太大的帮助。你在分析数据库架构的时候需要从你的应用特点出发,明确你的应用需要从分布式数据库中获得什么样的能力,从而进行相关的分析和比较。今天我从几个方面分析一下分布式数据库选型时应该注意的问题。
如果你仅仅需要解决高可用的问题,让任何软硬件故障都不会引起业务的中断和抖动,那么你只需要重点考虑高可用与易用性、可管理能力等方面的因素就可以了,千万不要得陇望蜀,除了你最关注的问题之外,非要把分布式事务性能、可扩展能力等也放在主要选择因素里,因为加上了这些干扰项,你最终可能会做出十分糟糕的选择。
周五的文章发布之后,有网友在文章后面留言说:做了分布式数据库几年了,他认为分布式数据库并不是为了解决高性能高并发的,这也不是分布式数据库的初衷,分布式数据库更多的是在解决高可用,无缝切换,平滑扩容,极致运维体验方面。我比较赞同他的观点,不过他说的只是分布式数据库设计的一种场景,不是所有场景。他从事的行业可能是金融行业,目前金融行业执着的追求分布式数据库,主要看重的就是可用性问题。在其他行业确实也存在高并发,高性能方面的需求。这个案例也说明了按照需求去选择产品特性的重要性。一切好的东西都是有代价的,目前还真没有任何地方都十分完美的数据库产品,特别是分布式数据库产品,那就更是如此了。
深入分析数据库的特点与架构还有助于了解一些数据库的一些不太容易发现的优缺点。这些问题可能是通过深入分析某个数据库的架构特点,了解其实现算法的过程中自己分析出来的。这样有助于你通过设置相应的测试用例来分析某些数据库的弱项是否能够达到你的最低需求。了解某个数据库的短处并不是为了找理由不去使用它,而是为了更好的使用它。因为了解了这些之后,可以指导你在应用系统设计与建设的时候扬长避短。
Mether在回复Steinar Gunderson的时候也指出SQL引擎、存储引擎、架构等的不同都会对数据库的特性产生很大的影响。这句话不仅仅针对集中式数据库有效,针对分布式数据库也是有效的。数据库在底层架构上的特性,其带来的优势的同时必然会存在一定的缺陷,这种缺陷甚至很难通过数据库版本的升级来得到彻底的解决,因此你必须十分注意。
存储引擎对数据库的性能的影响是十分深远的,不同的存储引擎可能对不同的应用负载更为有效,而对于一些其他的负载引擎可能就会很糟糕。以CockroachDB(以下简称CRDB)和YugabyteDB为例,他们都是使用PostgreSQL语法引擎的,不过底层的存储架构不同,CRDB采用KV存储Rocksdb,而YugabyteDB采用文档存储引擎。架构上二者都使用了无中心化的SHARDING架构。从二者的性能对比上看,针对带事务的操作方面CRDB绝对领先Yugabytedb,而如果是不带事务的操作,则完全相反。这是因为底层存储架构决定了其对不同业务负载的支撑能力。当然不同团队的研发水平也会存在一定的差异。
目前的分布式数据库采用的存储引擎大致有堆表(有些分类把堆表归纳到BTREE表,实际上还是有些细微的不同)、BTREE、LSM-TREE、文档引擎这几类。这些存储引擎的优缺点今天我们先不展开讨论了。几个月前我曾经写过一篇关于BTREE/LSM-TREE存储引擎的差别的文章,大家有兴趣可以参考,那篇文章的名字是《聊聊LSM-TREE存储引擎》,大家有兴趣可以去搜索。
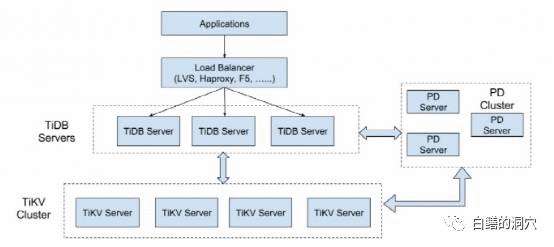
除了存储引擎,对于分布式数据库而言,有一个更大的影响因素,那就是中心化架构和SHARDING架构这两种架构的选择。如果把Oracle RAC也算是分布式数据库的话,那么Oracle RAC是存储中心化的数据库(共享存储架构),而现在的分布式数据库大多数是SHARE NOTHING的SHARDING架构,也就是分区架构。这种SHARDING架构是一种无中心的架构,每个分片包含一个SQL引擎外加一系列的存储引擎,采用这种架构的典型数据库是OCEANBASE、CRDB、YugabyteDB等。还有一些无中心化架构的数据库,每个SHARDING实际上都是一个独立的数据库,包含存储与计算,比如TDSQL、Polardb-X、HOTDB、POSTGRES-XC等。
上图是OB的架构图,下图是YugabyteDB的架构图,大家可以看出这是十分典型的SHARDING结构。大家可能感觉到我漏掉了什么,是的,我还没说TIDB。这是因为TIDB采用了和上面的这些分布式数据库完全不同的架构路线,TIDB从本质上说,是一种带中心的分布式数据库。因为TIDB的架构中,对于每个计算节点TIDB来说,每个存储节点TIKV都是一样的。每个TIDB SERVER就是一个计算中心,SQL语句只有分解为AST之后,才能细化出一些算子,将这些算子推送到下层的TIKV中去计算。我们来做一个假设,如果所有的TIDB SERVER之间能够支持缓冲区融合,后端的TiKV region存储在共享存储里,那么TIDB就变成ORACLE RAC了。当然这只是一个假设,TiDB不可能这么去设计。
从上面的TIDB的架构图我们可以看出,TIDB和上面的SHARDING方式的数据库之间,架构上存在巨大的差异。SHARDING架构与带中心的分布式数据库其架构上的特点就决定了在一些应用场景上的性能差异。Tidb数据库在创建表的时候,不需要考虑SHARDING键的问题,可以用类似集中式数据库的方式去进行表分区设计。而采用SHARDING模式的数据库就要认真设计SHARDING键了,如果SHARDING键设计的不合理,会对今后应用的性能产生较大的影响。
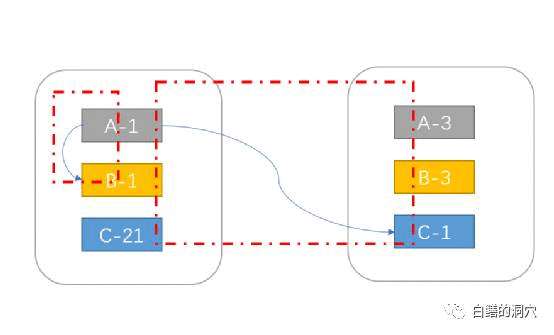
上图所示,如果A-1和B-1的数据进行JOIN,那么效率是很高的,而如果要进行A-1/C-1的JOIN,就需要跨分区进行了,对于SHARDING数据库来说,这样的JOIN成本开销就明显增加了。而采用中心化架构的TIDB不存在这个问题。曾经有一次我和一个客户的IT主管讨论过这个问题,他认为TIDB这种计算与存储完全分离的不带SHARDING的架构可能更适合他们的应用场景。确实,对于传统行业的应用开发模式而言,TiDB的架构特点可以让他们的研发人员更容易上手。
当然SHARDING架构也并不都是缺点,在某些场景下,SHARDING架构比中心化架构更有优势。在分布式数据库中,为了获得更好的性能,充分发挥多服务器的优势,计算节点必须能把算子下推到存储层。
在SHARDING架构下,算子的下推可以是在SQL层进行,因此针对过滤性较好的SQL,SHARDING架构可以更有效的过滤无效数据,因此那些不需要跨实例JOIN的SQL的执行效率,可能在SHARDING架构下会有更好的效率。而采用中心化架构的TIDB数据库只能通过优化器下推一部分算子到KV层,在KV层实现一部分数据过滤,其执行计划的优化的难度要比以SQL层的算子下推高得多。另外SHARDING架构下,每个数据库实例的DB CACHE具有更高的效率,可以更有效的减少IO,从而节约系统资源。在消除热点方面,SHARDING架构也更容易实现。不过要发挥出上面的优势的前提是我们的应用系统的数据架构可以很好的根据SHARDING KEY进行优化设计。
另外,无中心架构的数据库很适合异地多活的部署/同城双活部署,而有中心架构的分布式数据库虽然也支持这种部署架构,不过因为网络延时增加后会对分布式事务产生较大的影响,这也是我们在选择数据库时需要关注的。
谈到异地多活或者同城双活,这里免不了就要多说几句,那就是分布式数据库的异地多活部署模式下,还需要不需要容灾和备份呢?可能很多数据库厂商和客户都认为不需要了,实际上这是一种十分危险的观点。因为这个数据库就是一个单点,对于金融级高可用的场景要求下,绝对不是所谓“金融级分布式数据库”就可以替代两地三中心的传统容灾架构的。二十多年前我给深交所实施过灾备系统,哪怕深交所用的是NONSTOP的容错主机,依然是需要一套灾备系统来保证其任何情况下都不出问题的。
从上面的分析,我们可以看出,每种架构都有其优缺点,对某种类型的应用的适配性也会有较大的不同,根据你的应用特点去选择合适的分布式数据库架构依然是十分关键的。
在分布式事务的实现上也存在几个流派。目前主要使用的方法有两种:一种是类似XA的分布式事务,使用SHARDING分区的数据库实例原生态的事务来实现本地事务,在数据库集群层面使用2PC的模型实现全局分布式事务,大部分存储引擎直接使用某种开源数据库的分布式数据库都采用这种方式,这种方式其实也算是下面提到的Percolator模型的一种简化版的变体;另外一种是完全基于谷歌BIGTABLE相关论文之一《Large-scale Incremental Processing Using Distributed Transactions and Notifications》中提出的基于两阶段提交(2PC)的Percolator模型。
TIDB、Yugabytedb、CRDB等数据库都是在谷歌的2PC模型的基础上改造的。OB数据库中的2PC是不是参考了这个模型,蚂蚁的人没有明确的说法,我这里就不加猜测了,不过我想其基本原理应该也差不太多。
Percolator模型很适合在分布式数据库上建立SNAPSHOT ISOLATION级别的ACID强一致性事务,因此十分广泛的被分布式数据库使用。其lock、write、data分离的模式实现起来架构十分清晰,不过因为一个事务被分为三个控制结构,因此在事务控制中需要更多的网络交互,因此会增加分布式事务的成本。谷歌为了解决这个问题,使用了一种高精度的原子钟,从而避免在全球部署的数据库环境中产生中心点,同时也通过砸钱解决了昂贵的网络延时问题。而TiDB使用了论文中提到的TSO(Timestamp Oracle),这让PD成为了一个中心点。CRDB为了去中心化,没有使用集中式的TSO。采用了一种更为廉价的实现方式,通过NTP来同步集群节点之间的时钟,从而获得不太精确的全局TIMESTAMP。
基于这个原因,使用Percolator模型的分布式数据库,其乐观锁的性能比较好,而如果要支持悲观锁,需要有更大的分布式事务锁的开销。使用乐观锁的时候,Percolator模型可以减少在SQL执行过程中锁的探测,在内存中完成prewrite,提交时进行锁冲突的检查,如果存在写写冲突,回滚事务就可以了。
如果要支持悲观锁,那么在每个数据修改操作进行时,都需要检测行上面是否有锁,如果有锁就要等待。似乎普通的事务锁也是这样的,不过在分布式2PC模型Percolator中,因为需要在一个网络环境下支持一致性读和SNAPSHOT隔离,在算法上有一个无法避开的缺陷,那就是部分读操作也可能会被写操作锁阻塞。这一点已经超出了我们对MVCC的认知了,事实上,在分布式数据库环境中,一些并发方面的概念虽然还是用了集中式数据库的名字,但是其内在含义可能会略有不同。由于读阻塞的存在,这种等待的代价会被极大的放大(关于这方面的原理,因为篇幅有限,我们下回另外找时间探讨)。
因为这个原因,我们在使用基于Percolator模型改进的2PC分布式事务的数据库上做应用开发的时候,就应该注意两点,第一是,如果不是十分必要,尽可能使用乐观锁来替代我们在使用集中式数据库中时习惯的悲观锁(注意写好对COMMIT的异常检测,大多数应用就能很好的支持乐观锁了),只有在乐观锁的COMMIT异常处理比较麻烦或者成本太高的场合选择悲观锁。第二是,每个事务的批量尽可能保持在一个合理的范围,比如100-500条数据。如果提交频率太高,单个事务包含的修改量过少,应用的整体性能会受到影响,而如果在这种分布式数据库中写太大的事务,可能会引起数据库整体的性能问题。
最后我们无法规避SQL引擎的问题,一个数据库产品,SQL引擎的性能,优化器的水平,对数据库的性能影响是最大的。在这方面,国内的大厂家在优化CBO优化器上投入较大,优化效果也比较好。而一些产品基本上沿用了开源的SQL引擎,在其上面的优化能力有限。把一个集中数据库的引擎迁移到分布式数据库上,还是有很大的差别的。这个问题不太好展开谈,因为我们并没有对这些SQL引擎做特别深入的研究。不过我以前见过一个分布式数据库,其语法完全兼容ORACLE,但是我随便跑了几条SQL发现,这哥们居然没有CBO优化器,我的SQL中两张表的顺序颠倒一下,执行计划就变了。
本来想用两篇文章把一些大家关心的分布式数据库的问题讲清楚,写的过程中才发现,这是一个无法完成的任务,分布式数据库涉及太广的知识面,很难用几千文字描述清楚,因此这篇文章也只能是浅浅的点一下分布式数据库选择中应该注意的几个基本概念。可能有对分布式数据库感兴趣的朋友还想继续了解一些分布式数据库的知识,不过我想明天先换个话题,如果有朋友对分布式数据库的某些方面仍然有需要探讨的地方,可以留言,我思考思考,过几天再写一篇文章讨论吧。
这周PGCONF 2021要在线上召开了,到时候我也有一个关于数据库运维的演讲和大家分享,欢迎有兴趣的朋友到时候去听一听。









 京公网安备 11010802041100号
京公网安备 11010802041100号