2017年Panqu Wang发表,空洞卷积用于语义分割,提出了HDC和DUC设计原则,取得了图像分割的好效果,Understanding Convolution for Semantic Segmentation,官方代码(MXNet)设计思想:
- 空洞卷积(扩张卷积):尽量保留内部数据结构和避免下采样,就是增大感受野的情况下保留更多信息,代替pooling
- 卷积前的下采样可以增大卷积核的感受野,作用的每一点就相当于以前的两个点。即便再上采样不行,信息无法重建。
- 反卷积:反方向卷积,完成上采样。
- HDC 混合空洞卷积设计原则,为了消除在连续使用dilation convolution时容易出现的网格影响(像素点丢失)。
- DUC 密集上采样卷积设计原则,相当于用通道数来弥补卷积/池化等操作导致的尺寸的损失。
- 语义分割的难点:
- 分类任务pooling损失可以接受,但像素级别的图像分割任务中,pooling丢失的信息对拼合能力很不利,很难准确的对像素分割。
- pixel-wise的输出,需要pooling来增大感受野,再upsampling还原尺寸
- 内部数据结构丢失、空间层级化信息丢失。
- 小物体信息无法重建。假设有四个pooling层则任何小于2^4 = 16pixel的物体信息将理论上无法重建
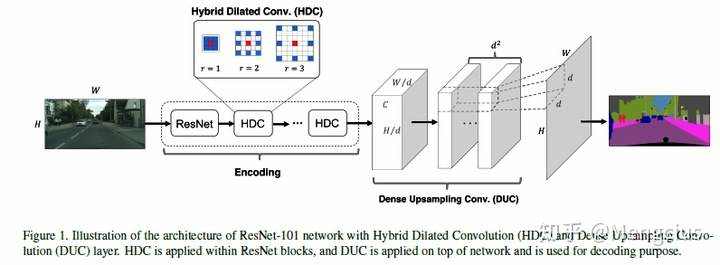
网络结构:
展示了有 HDC 和 DUC 层的ResNet-101网络的语义分割网络结构。HDC应用于ResNet块内,用于编码;DUC应用于网络顶部,用于解码。
空洞卷积
- 在卷积核中间填充0,扩大感受野,但没用下采样,没用大卷积核
- (a) 1-dilated conv,等于普通3*3卷积,没有填充空洞0
- (b) 2-dilated conv,卷积核3*3,空洞1,1-dilated + 2-dilated = 7*7conv大小的感受野。只用2倍空洞卷积会忽略掉很多点,可以与1倍的结合起来用。
- (c) 4-dilated conv,卷积核3*3,空洞4, 1-dilated + 2-dilated + 4-dilated = 15*15conv。每个元素的感受野为15*15,与每个层相关联的参数的数量是相同的,感受野呈指数增长,而参数数量呈线性增长。
- 对比传统的conv操作,3层3x3的卷积加起来,stride为1的话,只能达到(kernel-1)*layer+1=7的感受野(7->5->3),也就是和层数layer成线性关系,而dilated conv的感受野是指数级的增长。
Dilated Conv的潜在问题
- kernel 并不连续,也就是并不是所有的 pixel 会被计算到,同样会忽略掉一些点的信息。
- 只采用大 dilation rate conv 检测小体积效果不理想,很多像素点考虑不到。可以做多尺度的变换,但会增加网络复杂度。
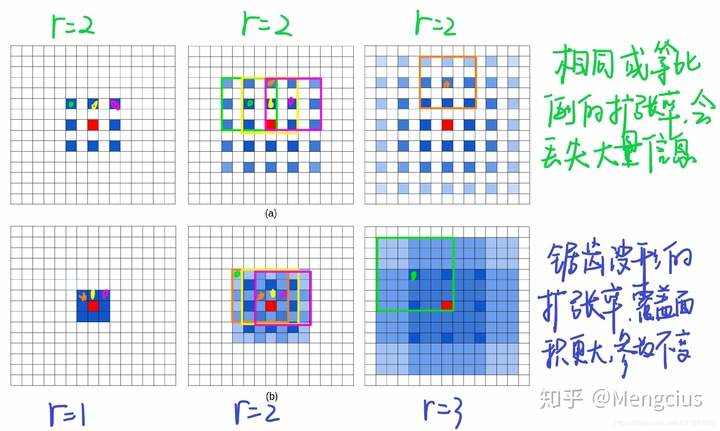
HDC
- HDC原则 (Hybrid Dilated Convolution) - 图森组
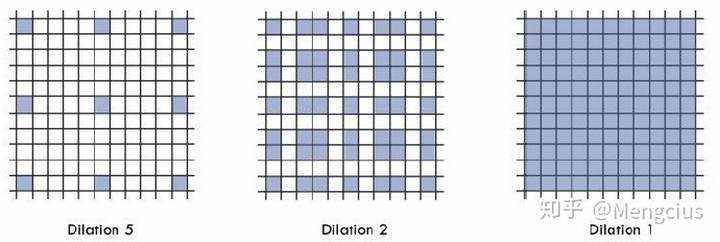
- 混合空洞卷积,在每一层使用不同的rate,把dilatioin rate 变成锯齿形式的也就是不同层之间的dilation不断变化。目标是最后的接收野全覆盖整个区域。
- 1. 叠加卷积的 dilation rate 不能有大于1的公约数。比如 [2, 4, 6] 则不是一个好的三层卷,有些点永远不会被考虑
- 2. 将 dilation rate 设计成锯齿状结构。例如[1, 2, 3, 1, 2, 3] 循环结构,覆盖了所有点,如上图
- 3. 需要满足一下这个式子&#xff0c;M<&#61;K&#xff1a;
- dilation rate是空洞卷积率&#xff0c;记为 ri&#xff0c;就是扩张倍数&#xff1b;K是卷积核尺寸
- 举例&#xff1a;对于常见的扩张卷积核大小K&#61;3&#xff0c;如果r&#61;[1,2,5] 则
- 此时M2&#61;2 ≤ K&#61;3 满足设计要求&#xff0c;设计的示意图如下&#xff1a;
DUC
- 双线性插值问题&#xff1a;如果模型的d&#61;16 d&#61;16d&#61;16&#xff0c;即输入到输出下采样了16倍。如果一个目标物的长或宽长度小于16个pixel&#xff0c;训练label map需要下采样到与模型输出维度相同&#xff0c;即下采样16倍时已经丢失了许多细节, 对应的模型预测结果双线性插值上采样是无法恢复这个信息。
- 密集上采样卷积DUC (Dense Upsampling Convolution)&#xff0c;做的事情就是改变原本top layer输出的shape&#xff0c;提高了小目标物的识别率&#xff0c;验证了DUC可以恢复双线性插值上采样损失的信息。
- DUC模块&#xff0c;将所有特征图分成d^2个子集&#xff08;d代表图像的降维比例&#xff09;。假如原始图像大小为H*W&#xff0c;卷积之后变为H/d*W/d&#xff0c;用h*w代替&#xff0c;具体为&#xff1a;
- 先将原先的h*w*c变成h*w*(d^2*L)&#xff0c;L为分割的类别数目
- 将此后的输出reshape为H*W*L&#xff0c;以此引入多个学习的参数&#xff0c;提升对细节的分割效果
反卷积 VS 空洞卷积
- Decon是上采样&#xff0c;Dilated Conv是增大感受野但不下采样
- Deconv是在像素之间填充空白的像素
- Dilated Conv是忽略掉了一些像素
- 反卷积还原图像尺寸&#xff0c;要下采样
空洞卷积的应用场景
- 像素级任务&#xff0c;属于背景还是前景&#xff0c;前景中的哪一种
- 如语义分割任务&#xff0c;明显HDC原则的空洞卷积ResNet更好实现了语义分割网络
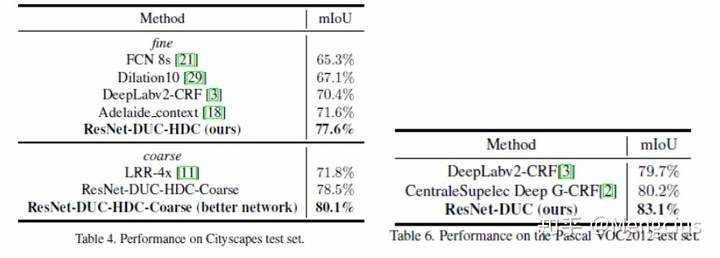
论文实验结果
在语义分割领域的CityScapes、PASCAL VOC 2012、Kitti Road benchmark数据集取得了当时最先进的成果。
推荐阅读&#xff1a;
本论文解析&#xff1a;https://blog.csdn.net/u011974639/article/details/79460893
反卷积&#xff1a; https://www.zhihu.com/question/43609045/answer/132235276
ASPP网络(Atrous Spatial Pyramid Pooling)-港中文和商汤组
另外在我的主页中还能看到其他系列专栏&#xff1a;【OpenCV图像处理】【斯坦福CS231n笔记】

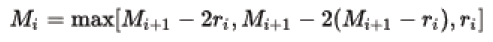
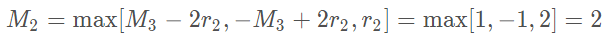








 京公网安备 11010802041100号
京公网安备 11010802041100号