一、环境说明
1、机器:一台物理机 和一台虚拟机
2、linux版本:[spark@S1PA11 ~]$ cat /etc/issue
Red Hat Enterprise Linux Server release 5.4 (Tikanga)
3、JDK: [spark@S1PA11 ~]$ java -version
java version "1.6.0_27"
Java(TM) SE Runtime Environment (build 1.6.0_27-b07)
Java HotSpot(TM) 64-Bit Server VM (build 20.2-b06, mixed mode)
4、集群节点:两个 S1PA11(Master),S1PA222(Slave)
二、准备工作
1、安装Java jdk前一篇文章撰写了:http://blog.csdn.net/stark_summer/article/details/42391531
2、ssh免密码验证 :http://blog.csdn.net/stark_summer/article/details/42393053
3、下载Hadoop版本:http://mirror.bit.edu.cn/apache/hadoop/common/
三、安装Hadoop
这是下载后的hadoop-2.6.0.tar.gz压缩包,
1、解压 tar -xzvf hadoop-2.6.0.tar.gz
2、move到指定目录下:[spark@S1PA11 software]$ mv hadoop-2.6.0 ~/opt/
3、进入hadoop目前 [spark@S1PA11 opt]$ cd hadoop-2.6.0/
[spark@S1PA11 hadoop-2.6.0]$ ls
bin dfs etc include input lib libexec LICENSE.txt logs NOTICE.txt README.txt sbin share tmp
配置之前,先在本地文件系统创建以下文件夹:~/hadoop/tmp、~/dfs/data、~/dfs/name。 主要涉及的配置文件有7个:都在/hadoop/etc/hadoop文件夹下,可以用gedit命令对其进行编辑。
~/hadoop/etc/hadoop/hadoop-env.sh
~/hadoop/etc/hadoop/yarn-env.sh
~/hadoop/etc/hadoop/slaves
~/hadoop/etc/hadoop/core-site.xml
~/hadoop/etc/hadoop/hdfs-site.xml
~/hadoop/etc/hadoop/mapred-site.xml
~/hadoop/etc/hadoop/yarn-site.xml
4、进去hadoop配置文件目录
[spark@S1PA11 hadoop-2.6.0]$ cd etc/hadoop/
[spark@S1PA11 hadoop]$ ls
capacity-scheduler.xml hadoop-env.sh httpfs-env.sh kms-env.sh mapred-env.sh ssl-client.xml.example
configuration.xsl hadoop-metrics2.properties httpfs-log4j.properties kms-log4j.properties mapred-queues.xml.template ssl-server.xml.example
container-executor.cfg hadoop-metrics.properties httpfs-signature.secret kms-site.xml mapred-site.xml yarn-env.cmd
core-site.xml hadoop-policy.xml httpfs-site.xml log4j.properties mapred-site.xml.template yarn-env.sh
hadoop-env.cmd hdfs-site.xml kms-acls.xml mapred-env.cmd slaves yarn-site.xml
4.1、配置 hadoop-env.sh文件-->修改JAVA_HOME
# The java implementation to use.
export JAVA_HOME=/home/spark/opt/java/jdk1.6.0_37
4.2、配置 yarn-env.sh 文件-->>修改JAVA_HOME
# some Java parameters
export JAVA_HOME=/home/spark/opt/java/jdk1.6.0_37
4.3、配置slaves文件-->>增加slave节点
S1PA222
4.4、配置 core-site.xml文件-->>增加hadoop核心配置(hdfs文件端口是9000、file:/home/spark/opt/hadoop-2.6.0/tmp、)
4.5、配置 hdfs-site.xml 文件-->>增加hdfs配置信息(namenode、datanode端口和目录位置)
4.6、配置 mapred-site.xml 文件-->>增加mapreduce配置(使用yarn框架、jobhistory使用地址以及web地址)
4.7、配置 yarn-site.xml 文件-->>增加yarn功能
5、将配置好的hadoop文件copy到另一台slave机器上
[spark@S1PA11 opt]$ scp -r hadoop-2.6.0/ spark@10.126.34.43:~/opt/
四、验证
1、格式化namenode:
[spark@S1PA11 opt]$ cd hadoop-2.6.0/
[spark@S1PA11 hadoop-2.6.0]$ ls
bin dfs etc include input lib libexec LICENSE.txt logs NOTICE.txt README.txt sbin share tmp
[spark@S1PA11 hadoop-2.6.0]$ ./bin/hdfs namenode -format
[spark@S1PA222 .ssh]$ cd ~/opt/hadoop-2.6.0
[spark@S1PA222 hadoop-2.6.0]$ ./bin/hdfs namenode -format
2、启动hdfs:
[spark@S1PA11 hadoop-2.6.0]$ ./sbin/start-dfs.sh
15/01/05 16:41:04 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [S1PA11]
S1PA11: starting namenode, logging to /home/spark/opt/hadoop-2.6.0/logs/hadoop-spark-namenode-S1PA11.out
S1PA222: starting datanode, logging to /home/spark/opt/hadoop-2.6.0/logs/hadoop-spark-datanode-S1PA222.out
Starting secondary namenodes [S1PA11]
S1PA11: starting secondarynamenode, logging to /home/spark/opt/hadoop-2.6.0/logs/hadoop-spark-secondarynamenode-S1PA11.out
15/01/05 16:41:21 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[spark@S1PA11 hadoop-2.6.0]$ jps
22230 Master
30889 Jps
22478 Worker
30498 NameNode
30733 SecondaryNameNode
19781 ResourceManager
3、停止hdfs:
[spark@S1PA11 hadoop-2.6.0]$./sbin/stop-dfs.sh
15/01/05 16:40:28 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Stopping namenodes on [S1PA11]
S1PA11: stopping namenode
S1PA222: stopping datanode
Stopping secondary namenodes [S1PA11]
S1PA11: stopping secondarynamenode
15/01/05 16:40:48 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[spark@S1PA11 hadoop-2.6.0]$ jps
30336 Jps
22230 Master
22478 Worker
19781 ResourceManager
4、启动yarn:
[spark@S1PA11 hadoop-2.6.0]$./sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/spark/opt/hadoop-2.6.0/logs/yarn-spark-resourcemanager-S1PA11.out
S1PA222: starting nodemanager, logging to /home/spark/opt/hadoop-2.6.0/logs/yarn-spark-nodemanager-S1PA222.out
[spark@S1PA11 hadoop-2.6.0]$ jps
31233 ResourceManager
22230 Master
22478 Worker
30498 NameNode
30733 SecondaryNameNode
31503 Jps
5、停止yarn:
[spark@S1PA11 hadoop-2.6.0]$ ./sbin/stop-yarn.sh
stopping yarn daemons
stopping resourcemanager
S1PA222: stopping nodemanager
no proxyserver to stop
[spark@S1PA11 hadoop-2.6.0]$ jps
31167 Jps
22230 Master
22478 Worker
30498 NameNode
30733 SecondaryNameNode
6、查看集群状态:
[spark@S1PA11 hadoop-2.6.0]$ ./bin/hdfs dfsadmin -report
15/01/05 16:44:50 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Configured Capacity: 52101857280 (48.52 GB)
Present Capacity: 45749510144 (42.61 GB)
DFS Remaining: 45748686848 (42.61 GB)
DFS Used: 823296 (804 KB)
DFS Used%: 0.00%
Under replicated blocks: 10
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Live datanodes (1):
Name: 10.126.45.56:50010 (S1PA222)
Hostname: S1PA209
Decommission Status : Normal
Configured Capacity: 52101857280 (48.52 GB)
DFS Used: 823296 (804 KB)
Non DFS Used: 6352347136 (5.92 GB)
DFS Remaining: 45748686848 (42.61 GB)
DFS Used%: 0.00%
DFS Remaining%: 87.81%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Mon Jan 05 16:44:50 CST 2015
7、查看hdfs:http://10.58.44.47:50070/
8、查看RM:http://10.58.44.47:8088/
9、运行wordcount程序
9.1、创建 input目录:[spark@S1PA11 hadoop-2.6.0]$ mkdir input
9.2、在input创建f1、f2并写内容
[spark@S1PA11 hadoop-2.6.0]$ cat input/f1
Hello world bye jj
[spark@S1PA11 hadoop-2.6.0]$ cat input/f2
Hello Hadoop bye Hadoop
9.3、在hdfs创建/tmp/input目录
[spark@S1PA11 hadoop-2.6.0]$ ./bin/hadoop fs -mkdir /tmp
15/01/05 16:53:57 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[spark@S1PA11 hadoop-2.6.0]$ ./bin/hadoop fs -mkdir /tmp/input
15/01/05 16:54:16 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
9.4、将f1、f2文件copy到hdfs /tmp/input目录
[spark@S1PA11 hadoop-2.6.0]$ ./bin/hadoop fs -put input/ /tmp
15/01/05 16:56:01 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
9.5、查看hdfs上是否有f1、f2文件
[spark@S1PA11 hadoop-2.6.0]$ ./bin/hadoop fs -ls /tmp/input/
15/01/05 16:57:42 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 2 items
-rw-r--r-- 3 spark supergroup 20 2015-01-04 19:09 /tmp/input/f1
-rw-r--r-- 3 spark supergroup 25 2015-01-04 19:09 /tmp/input/f2
9.6、执行wordcount程序
[spark@S1PA11 hadoop-2.6.0]$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount /tmp/input /output
15/01/05 17:00:09 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
15/01/05 17:00:09 INFO client.RMProxy: Connecting to ResourceManager at S1PA11/10.58.44.47:8032
15/01/05 17:00:11 INFO input.FileInputFormat: Total input paths to process : 2
15/01/05 17:00:11 INFO mapreduce.JobSubmitter: number of splits:2
15/01/05 17:00:11 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1420447392452_0001
15/01/05 17:00:12 INFO impl.YarnClientImpl: Submitted application application_1420447392452_0001
15/01/05 17:00:12 INFO mapreduce.Job: The url to track the job: http://S1PA11:8088/proxy/application_1420447392452_0001/
15/01/05 17:00:12 INFO mapreduce.Job: Running job: job_1420447392452_0001
9.7、查看执行结果
[spark@S1PA11 hadoop-2.6.0]$ ./bin/hadoop fs -cat /output/part-r-0000
15/01/05 17:06:10 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Caogao

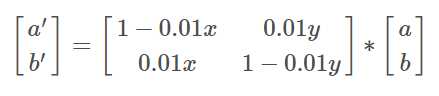


![[c++基础]STL](https://img.php1.cn/3c972/1edc8/c5a/a04ecc977fd8ed28.jpeg)


 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 

