
作者 | 马超
责编 | 张红月
出品 | CSDN博客
Serverless的核心理念就是函数式计算,开发者无需再关注具体的模块,云上部署的粒度变成了程序函数,自动伸缩、扩容等工作完全由云服务负责。
Serverless Computing,即”无服务器计算”,其实这一概念在刚刚提出的时候并没有获得太多的关注,直到2014年AWS Lambda这一里程碑式的产品出现。Serverless算是正式走进了云计算的舞台。2018年5月,Google在KubeCon+CloudNative 2018期间开源了gVisor容器沙箱运行时并分享了它的设计理念和原则。随后2018年的Google Next大会上Google推出了自己的 Google Serverless平台 —— gVisor。同年AWS又放了颗大炮仗-Firecracker,这是一款基于Rust语言编写的安全沙箱基础组件,用于函数计算服务Lambda和托管的容器服务。
值得注意的是Google也并没有死守自己一手缔造的Go语言平台,而是选择了Go与Rust的模式,据说Google在Rust方面也开始招兵买马,也要用Rust重写之前基于Go编写的Serverless平台。
笔者写本文的初衷,其实就是要回答为什么在这个高并发大行其道的时代,以性能著称的C语言和以安全高效闻名的Java都不香了呢?
高并发模式初探
在这个高并发时代最重要的设计模式无疑是生产者、消费者模式,比如著名的消息队列kafka其实就是一个生产者消费者模式的典型实现。其实生产者消费者问题,也就是有限缓冲问题,可以用以下场景进行简要描述,生产者生成一定量的产品放到库房,并不断重复此过程;与此同时,消费者也在缓冲区消耗这些数据,但由于库房大小有限,所以生产者和消费者之间步调协调,生产者不会在库房满的情况放入端口,消费者也不会在库房空时消耗数据。详见下图:
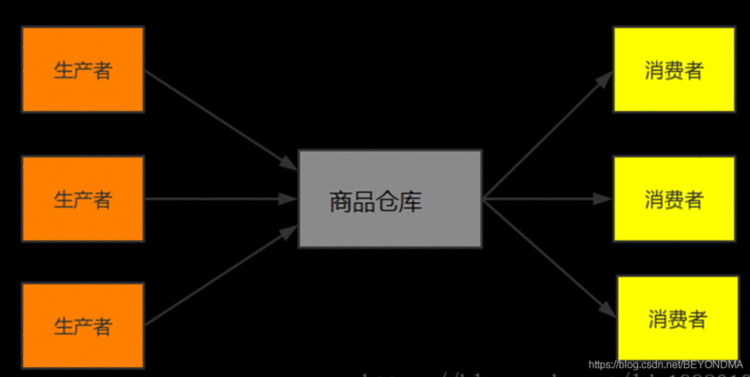
而如果在生产者与消费者之间完美协调并保持高效,这就是高并发要解决的本质问题。

C语言的高并发案例
笔者曾经介绍过 TDEngine 的相关代码,其中 Sheduler 模块的相关调度算法就使用了生产、消费者模式进行消息传递功能的实现,也就是有多个生产者(producer)生成并不断向队列中传递消息,也有多个消费者(consumer)不断从队列中取消息。
后面我们也会说明类型功能在Go、Java 等高级语言中类似的功能已经被封装好了,但是在C语言中你就必须要用好互斥体( mutex)和信号量(semaphore)并协调他们之间的关系。由于C语言的实现是最复杂的,先来看结构体设计和他的注释:
typedef struct {char label[16];//消息内容sem_t emptySem;//此信号量代表队列的可写状态sem_t fullSem;//此信号量代表队列的可读状态pthread_mutex_t queueMutex;//此互斥体为保证消息不会被误修改,保证线程程安全int fullSlot;//队尾位置int emptySlot;//队头位置int queueSize;#队列长度int numOfThreads;//同时操作的线程数量pthread_t * qthread;//线程指针SSchedMsg * queue;//队列指针
} SSchedQueue;
再来看Shceduler初始化函数,这里需要特别说明的是,两个信号量的创建,其中emptySem是队列的可写状态,初始化时其值为queueSize,即初始时队列可写,可接受消息长度为队列长度,fullSem是队列的可读状态,初始化时其值为0,即初始时队列不可读。具体代码及我的注释如下:
void *taosInitScheduler(int queueSize, int numOfThreads, char *label) {pthread_attr_t attr;SSchedQueue * pSched &#61; (SSchedQueue *)malloc(sizeof(SSchedQueue));memset(pSched, 0, sizeof(SSchedQueue));pSched->queueSize &#61; queueSize;pSched->numOfThreads &#61; numOfThreads;strcpy(pSched->label, label);if (pthread_mutex_init(&pSched->queueMutex, NULL) <0) {pError("init %s:queueMutex failed, reason:%s", pSched->label, strerror(errno));goto _error;}//emptySem是队列的可写状态&#xff0c;初始化时其值为queueSize&#xff0c;即初始时队列可写&#xff0c;可接受消息长度为队列长度。if (sem_init(&pSched->emptySem, 0, (unsigned int)pSched->queueSize) !&#61; 0) {pError("init %s:empty semaphore failed, reason:%s", pSched->label, strerror(errno));goto _error;}//fullSem是队列的可读状态&#xff0c;初始化时其值为0&#xff0c;即初始时队列不可读if (sem_init(&pSched->fullSem, 0, 0) !&#61; 0) {pError("init %s:full semaphore failed, reason:%s", pSched->label, strerror(errno));goto _error;}if ((pSched->queue &#61; (SSchedMsg *)malloc((size_t)pSched->queueSize * sizeof(SSchedMsg))) &#61;&#61; NULL) {pError("%s: no enough memory for queue, reason:%s", pSched->label, strerror(errno));goto _error;}memset(pSched->queue, 0, (size_t)pSched->queueSize * sizeof(SSchedMsg));pSched->fullSlot &#61; 0;//实始化时队列为空&#xff0c;故队头和队尾的位置都是0pSched->emptySlot &#61; 0;//实始化时队列为空&#xff0c;故队头和队尾的位置都是0pSched->qthread &#61; malloc(sizeof(pthread_t) * (size_t)pSched->numOfThreads);pthread_attr_init(&attr);pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_JOINABLE);for (int i &#61; 0; i
}
再来看读消息的taosProcessSchedQueue函数这其实是消费者一方的实现&#xff0c;这个函数的主要逻辑是&#xff1a;
1.使用无限循环&#xff0c;只要队列可读即sem_wait(&pSched->fullSem)不再阻塞就继续向下处理&#xff1b;
2.在操作msg前&#xff0c;加入互斥体防止msg被误用&#xff1b;
3.读操作完毕后修改fullSlot的值&#xff0c;注意这为避免fullSlot溢出&#xff0c;需要对于queueSize取余。同时退出互斥体&#xff1b;
4.对emptySem进行post操作&#xff0c;即把emptySem的值加1&#xff0c;如emptySem原值为5&#xff0c;读取一个消息后&#xff0c;emptySem的值为6&#xff0c;即可写状态&#xff0c;且能接受的消息数量为6。
具体代码及注释如下&#xff1a;
void *taosProcessSchedQueue(void *param) {SSchedMsg msg;SSchedQueue *pSched &#61; (SSchedQueue *)param;//注意这里是个无限循环&#xff0c;只要队列可读即sem_wait(&pSched->fullSem)不再阻塞就继续处理while (1) {if (sem_wait(&pSched->fullSem) !&#61; 0) {pError("wait %s fullSem failed, errno:%d, reason:%s", pSched->label, errno, strerror(errno));if (errno &#61;&#61; EINTR) {/* sem_wait is interrupted by interrupt, ignore and continue */continue;}}//加入互斥体防止msg被误用。if (pthread_mutex_lock(&pSched->queueMutex) !&#61; 0)pError("lock %s queueMutex failed, reason:%s", pSched->label, strerror(errno));msg &#61; pSched->queue[pSched->fullSlot];memset(pSched->queue &#43; pSched->fullSlot, 0, sizeof(SSchedMsg));//读取完毕修改fullSlot的值&#xff0c;注意这为避免fullSlot溢出&#xff0c;需要对于queueSize取余。pSched->fullSlot &#61; (pSched->fullSlot &#43; 1) % pSched->queueSize;//读取完毕修改退出互斥体if (pthread_mutex_unlock(&pSched->queueMutex) !&#61; 0)pError("unlock %s queueMutex failed, reason:%s\n", pSched->label, strerror(errno));//读取完毕对emptySem进行post操作&#xff0c;即把emptySem的值加1&#xff0c;如emptySem原值为5&#xff0c;读取一个消息后&#xff0c;emptySem的值为6&#xff0c;即可写状态&#xff0c;且能接受的消息数量为6if (sem_post(&pSched->emptySem) !&#61; 0)pError("post %s emptySem failed, reason:%s\n", pSched->label, strerror(errno));if (msg.fp)(*(msg.fp))(&msg);else if (msg.tfp)(*(msg.tfp))(msg.ahandle, msg.thandle);}
}
最后写消息的taosScheduleTask函数也就是生产的实现&#xff0c;其基本逻辑是
1.写队列前先对emptySem进行减1操作&#xff0c;如emptySem原值为1&#xff0c;那么减1后为0&#xff0c;也就是队列已满&#xff0c;必须在读取消息后&#xff0c;即emptySem进行post操作后&#xff0c;队列才能进行可写状态。
2.加入互斥体防止msg被误操作&#xff0c;写入完成后退出互斥体
3.写队列完成后对fullSem进行加1操作&#xff0c;如fullSem原值为0&#xff0c;那么加1后为1&#xff0c;也就是队列可读&#xff0c;咱们上面介绍的读取taosProcessSchedQueue中sem_wait(&pSched->fullSem)不再阻塞就继续向下。
int taosScheduleTask(void *qhandle, SSchedMsg *pMsg) {SSchedQueue *pSched &#61; (SSchedQueue *)qhandle;if (pSched &#61;&#61; NULL) {pError("sched is not ready, msg:%p is dropped", pMsg);return 0;}//在写队列前先对emptySem进行减1操作&#xff0c;如emptySem原值为1&#xff0c;那么减1后为0&#xff0c;也就是队列已满&#xff0c;必须在读取消息后&#xff0c;即emptySem进行post操作后&#xff0c;队列才能进行可写状态。if (sem_wait(&pSched->emptySem) !&#61; 0) pError("wait %s emptySem failed, reason:%s", pSched->label, strerror(errno));
//加入互斥体防止msg被误操作if (pthread_mutex_lock(&pSched->queueMutex) !&#61; 0)pError("lock %s queueMutex failed, reason:%s", pSched->label, strerror(errno));pSched->queue[pSched->emptySlot] &#61; *pMsg;pSched->emptySlot &#61; (pSched->emptySlot &#43; 1) % pSched->queueSize;if (pthread_mutex_unlock(&pSched->queueMutex) !&#61; 0)pError("unlock %s queueMutex failed, reason:%s", pSched->label, strerror(errno));//在写队列前先对fullSem进行加1操作&#xff0c;如fullSem原值为0&#xff0c;那么加1后为1&#xff0c;也就是队列可读&#xff0c;咱们上面介绍的读取函数可以进行处理。if (sem_post(&pSched->fullSem) !&#61; 0) pError("post %s fullSem failed, reason:%s", pSched->label, strerror(errno));return 0;
}

Java的高并发实现
从并发模型来看&#xff0c;Go和Rust都有channel这个概念&#xff0c;也都是通过Channel来实现线&#xff08;协&#xff09;程间的同步&#xff0c;由于channel带有读写状态且保证数据顺序&#xff0c;而且channel的封装程度和效率明显可以做的更高&#xff0c;因此Go和Rust官方都会建议使用channel&#xff08;通信&#xff09;来共享内存&#xff0c;而不是使用共享内存来通信。
为了让帮助大家找到区别&#xff0c;我们先以Java为例来&#xff0c;看一下没有channel的高级语言Java&#xff0c;生产者消费者该如何实现&#xff0c;代码及注释如下&#xff1a;
public class Storage {// 仓库最大存储量private final int MAX_SIZE &#61; 10;// 仓库存储的载体private LinkedList list &#61; new LinkedList();// 锁private final Lock lock &#61; new ReentrantLock();// 仓库满的信号量private final Condition full &#61; lock.newCondition();// 仓库空的信号量private final Condition empty &#61; lock.newCondition();public void produce(){// 获得锁lock.lock();while (list.size() &#43; 1 > MAX_SIZE) {System.out.println("【生产者" &#43; Thread.currentThread().getName()&#43; "】仓库已满");try {full.await();} catch (InterruptedException e) {e.printStackTrace();}}list.add(new Object());System.out.println("【生产者" &#43; Thread.currentThread().getName() &#43; "】生产一个产品&#xff0c;现库存" &#43; list.size());empty.signalAll();lock.unlock();}public void consume(){// 获得锁lock.lock();while (list.size() &#61;&#61; 0) {System.out.println("【消费者" &#43; Thread.currentThread().getName()&#43; "】仓库为空");try {empty.await();} catch (InterruptedException e) {e.printStackTrace();}}list.remove();System.out.println("【消费者" &#43; Thread.currentThread().getName()&#43; "】消费一个产品&#xff0c;现库存" &#43; list.size());full.signalAll();lock.unlock();}
}
在Java、C#这种面向对象&#xff0c;但是没有channel语言中&#xff0c;生产者、消费者模式至少要借助一个lock和两个信号量共同完成。其中锁的作用是保证同是时间&#xff0c;仓库中只有一个用户进行数据的修改&#xff0c;而还需要表示仓库满的信号量&#xff0c;一旦达到仓库满的情况则将此信号量置为阻塞状态&#xff0c;从而阻止其它生产者再向仓库运商品了&#xff0c;反之仓库空的信号量也是一样&#xff0c;一旦仓库空了&#xff0c;也要阻其它消费者再前来消费了。

Go的高并发实现
我们刚刚也介绍过了Go语言中官方推荐使用channel来实现协程间通信&#xff0c;所以不需要再添加lock和信号量就能实现模式了&#xff0c;以下代码中我们通过子goroutine完成了生产者的功能&#xff0c;在在另一个子goroutine中实现了消费者的功能&#xff0c;注意要阻塞主goroutine以确保子goroutine能够执行&#xff0c;从而轻而易举的就这完成了生产者消费者模式。下面我们就通过具体实践中来看一下生产者消费者模型的实现。
package mainimport ("fmt""time"
)func Product(ch chan<- int) { //生产者for i :&#61; 0; i <3; i&#43;&#43; {fmt.Println("Product produceed", i)ch <- i //由于channel是goroutine安全的,所以此处没有必要必须加锁或者加lock操作.}
}
func Consumer(ch <-chan int) {for i :&#61; 0; i <3; i&#43;&#43; {j :&#61; <-ch //由于channel是goroutine安全的,所以此处没有必要必须加锁或者加lock操作.fmt.Println("Consmuer consumed ", j)}
}
func main() {ch :&#61; make(chan int)go Product(ch)//注意生产者与消费者放在不同goroutine中go Consumer(ch)//注意生产者与消费者放在不同goroutine中time.Sleep(time.Second * 1)//防止主goroutine退出/*运行结果并不确定&#xff0c;可能为Product produceed 0Product produceed 1Consmuer consumed 0Consmuer consumed 1Product produceed 2Consmuer consumed 2*/}
可以看到和Java比起来使用GO来实现并发式的生产者消费者模式的确是更为清爽了。
Rust的高并发实现
不得不说Rust的难度实在太高了&#xff0c;虽然笔者之前在汇编、C、Java等方面的经验可以帮助我快速掌握Go语言。但是假期看了两天Rust真想大呼告辞&#xff0c;太劝退了。在Rust官方提供的功能中&#xff0c;其实并不包括多生产者、多消费者的channel&#xff0c;std:sync空间下只有一个多生产者单消费者&#xff08;mpsc)的channel。其样例实现如下&#xff1a;
use std::sync::mpsc;
use std::thread;
use std::time::Duration;fn main() {let (tx, rx) &#61; mpsc::channel();let tx1 &#61; mpsc::Sender::clone(&tx);let tx2 &#61; mpsc::Sender::clone(&tx);thread::spawn(move || {let vals &#61; vec![String::from("1"),String::from("3"),String::from("5"),String::from("7"),];for val in vals {tx1.send(val).unwrap();thread::sleep(Duration::from_secs(1));}});thread::spawn(move || {let vals &#61; vec![String::from("11"),String::from("13"),String::from("15"),String::from("17"),];for val in vals {tx.send(val).unwrap();thread::sleep(Duration::from_secs(1));}});thread::spawn(move || {let vals &#61; vec![String::from("21"),String::from("23"),String::from("25"),String::from("27"),];for val in vals {tx2.send(val).unwrap();thread::sleep(Duration::from_secs(1));}});for rec in rx {println!("Got: {}", rec);}
}
可以看到在Rust下实现生产者消费者是不难的&#xff0c;但是生产者可以clone多个&#xff0c;不过消费者却只能有一个&#xff0c;究其原因是因为Rust下没有GC也就是垃圾回收功能&#xff0c;而想保证安全Rust就必须要对于变更使用权限进行严格管理。在Rust下使用move关键字进行变更的所有权转移&#xff0c;但是按照Rust对于变更生产周期的管理规定&#xff0c;线程间权限转移的所有权接收者在同一时间只能有一个&#xff0c;这也是Rust官方只提供MPSC的原因。
use std::thread;fn main() {let s &#61; "hello";let handle &#61; thread::spawn(move || {println!("{}", s);});handle.join().unwrap();
}
当然Rust下有一个API比较贴心就是join&#xff0c;他可以所有子线程都执行结束再退出主线程&#xff0c;这比Go中要手工阻塞还是要有一定的提高。而如果你想用多生产者、多消费者的功能&#xff0c;就要入手crossbeam模块了&#xff0c;这个模块掌握起来难度也真的不低。

总结
通过上面的比较我们可以用一张表格来说明几种主流语言的情况对比&#xff1a;
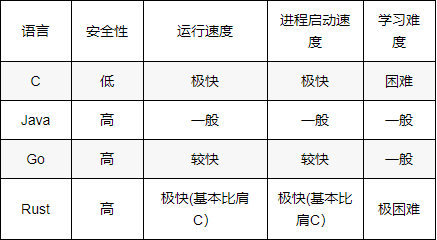
可以看到Rust以其高安全性、基本比肩C的运行及启动速度必将在Serverless的时代独占鳌头&#xff0c;Go基本也能紧随其后&#xff0c;而C语言程序中难以避免的野指针&#xff0c;Java相对较低的运行及启动速度&#xff0c;可能都不太适用于函数式运算的场景&#xff0c;Java在企业级开发的时代打败各种C#之类的对手&#xff0c;但是在云时代好像还真没有之前统治力那么强了&#xff0c;真可谓是打败你的往往不是你的对手&#xff0c;而是其它空间的降维打击。








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有