作者:mobiledu2502876867 | 来源:互联网 | 2023-09-23 20:46
从右向左。是因为从右向左的匹配在第一步就筛选掉大量的不符合条件的最右节点(叶子节点)。而从左向右的匹配规则的性能都浪费在了失败的查找上,简单来说,浏览器从右向左进行查找的好处是为了
从右向左。是因为从右向左的匹配在第一步就筛选掉大量的不符合条件的最右节点(叶子节点)。而从左向右的匹配规则的性能都浪费在了失败的查找上,简单来说,浏览器从右向左进行查找的好处是为了尽量过滤调一些无关的样式规则和元素,具体如下。
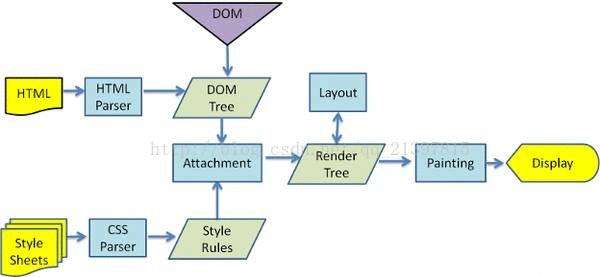
HTML 经过解析生成 DOM Tree;而在 CSS 解析完毕后,需要将解析的结果与 DOM Tree 的内容一起进行分析建立一棵 Render Tree,最终用来进行绘图。Render Tree 中的元素与 DOM 元素相对应,但非一一对应:一个 DOM 元素可能会对应多个 renderer,如文本折行后,不同的行会成为 render tree 种不同的 renderer。也有的 DOM 元素被 Render Tree 完全无视,比如 display:none 的元素。
在建立 Render Tree 时,浏览器就要为每个 DOM Tree 中的元素根据 CSS 的解析结果(Style Rules)来确定生成怎样的 renderer。对于每个 DOM 元素,必须在所有 Style Rules 中找到符合的 selector 并将对应的规则进行合并。选择器的解析实际是在这里执行的,在遍历 DOM Tree 时,从 Style Rules 中去寻找对应的 selector。 因为所有样式规则可能数量很大,而且绝大多数不会匹配到当前的 DOM 元素(因为数量很大所以一般会建立规则索引树),所以有一个快速的方法来判断这个 selector 不匹配当前元素就是极其重要的。
如果正向解析,例如「div div p em」,我们首先就要检查当前元素到 html 的整条路径,找到最上层的 div,再往下找,如果遇到不匹配就必须回到最上层那个 div,往下再去匹配选择器中的第一个 div,回溯若干次才能确定匹配与否,效率很低。逆向匹配则不同,如果当前的 DOM 元素是 div,而不是 selector 最后的 em,那只要一步就能排除。只有在匹配时,才会不断向上找父节点进行验证。但因为匹配的情况远远低于不匹配的情况,所以逆向匹配带来的优势是巨大的。同时我们也能够看出,在选择器结尾加上「*」就大大降低了这种优势,这也就是很多优化原则提到的尽量避免在选择器末尾添加通配符的原因。
简单的来说浏览器从右到左进行查找的好处是为了尽早过滤掉一些无关的样式规则和元素。



 京公网安备 11010802041100号
京公网安备 11010802041100号