2019独角兽企业重金招聘Python工程师标准>>> 
之前已经谈论了很多hadoop体系理论上的东西,而关于MR的编写并没有涉及很多。这里系统的讲一下MR的原理以及实战,迈好我们进行大数据处理的第一步。
MapReduce的原理
很简单,如图所示,已经重复了千万遍,别嫌麻烦:
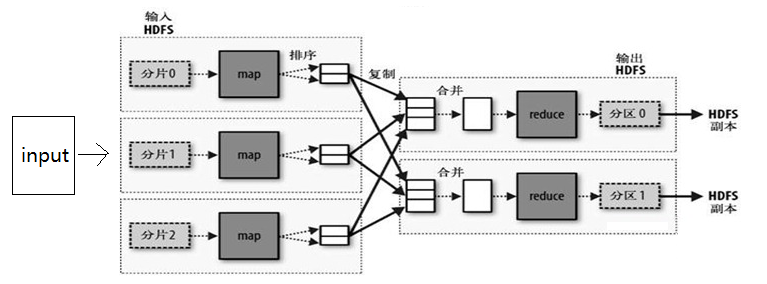
1. 首先, 我们能确定我们有一份输入, 而且他的数据量会很大
2. 通过split之后, 他变成了若干的分片, 每个分片交给一个Map处理
3. map处理完后, tasktracker会把数据进行复制和排序, 然后通过输出的key和value进行partition的划分, 并把partition相同的map输出, 合并为相同的reduce的输入.
4. ruducer通过处理, 把数据输出, 每个相同的key, 一定在一个reduce中处理完, 每一个reduce至少对应一份输出(可以通过扩展MultipleOutputFormat来得到多份输出)
5.下图是MP的一个例子:
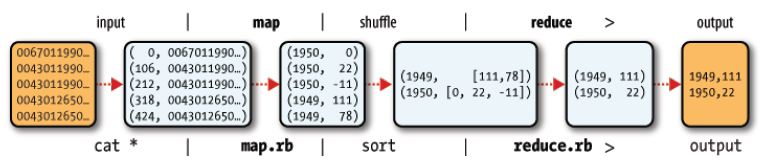
5.1 输入的数据可能就是一堆文本
5.2 mapper会解析每行数据, 然后提取有效的数据, 作为输出. 这里的例子是 从日志文件中提取每一年每天的气温, 最后会计算每年的最高气温
5.3 map的输出就是一条一条的key-value
5.4 通过shuffle之后, 变成reduce的输入, 这是相同的key对应的value被组合成了一个迭代器
5.5 reduce的任务是提取每一年的最高气温, 然后输出
Mapper原理
1. mapper可以选择性地继承 MapreduceBase这个基类, 他只是把一些方法实现了而已, 即使方法体是空的.
2. mapper必须实现 Mapper 接口(0.20以前的版本), 这是一个泛型接口, 需要执行输入和输出的key-value的类型, 这些类型通常都是Wriable接口的实现类
3. 实现map方法, 方法有四个参数, 前面两个就是输入的 Key 和 value, 第三个参数是 OuputCollector, 用于收集输出的, 第四个是reporter,用来报告一些状态的,可以用于debug
3.1 input 默认是一行一条记录, 每天记录都放在value里边
3.2 output每次搜集一条 K-V记录, 一个K可以对应多个value, 在reduce 里面体现为一个 iterator
4. 覆盖 configure方法可以得到JobConf的实例, 这个JobConf是在Job运行时传递过来的, 可以跟外部资源进行数据交互
Reducer
1. reduce也可以选择继承 MapreduceBase这个基类, 功能跟mapper一样.
2. reducer必须实现Reducer接口, 这个接口同样是泛型接口, 意义跟Mapper的类似
3. 实现reduce方法, 这个方法也有四个参数, 第一个是输入的key, 第二个是输入的 value的迭代器, 可以遍历所有的value,相当于一个列表, outputCollector跟map的一样, 是输出的搜集器, 每次搜集都是key-value的形式, report的作用跟map的相同.
4. 在新版本中, hadoop已经将后面两个参数合并到一个context对象里边了, 当然还会兼容就版本的 接口. >0.19.x
5. 覆盖configure方法, 作用跟map的相同
6. 覆盖close 方法,可以做一些reduce结束后的处理工作.(clean up)
Combiner
1. combiner的作用是, 将map的输出,先计算一遍,得到初步的合并结果, 减少reduce的计算压力.
2. combiner的编写方法跟reduce是一样的, 他本来就是一个Reducer的实现类
3. 当reducer符合函数 F(a,b) = F(F(a), F(b)) 时, combinner可以与reduce相同. 比如 sum(a,b,c,d,e,f,g) = sum(sum(a,b) ,sum(c,d,e,f) , sum(g)) 还有max, min等等.
4. 编写正确的combiner可以优化整个mapreduce程序的性能.(特别是当reduce是性能瓶颈的时候.)
5. combiner可以跟reducer不同.
Configuration
1. 后加的属性的值会覆盖前面定义的相同名称的属性的值.
2. 被定义为 final的属性(在属性定义中加上
3. 系统属性比通过资源定义的属性优先级高, 也就是通过System.setProperty()方法会覆盖在资源文件中定义的属性的值.
4. 系统属性定义必须在资源文件中有相应的定义才会生效.
5. 通过 -D 选项定义的属性, 比在资源文件中定义的属性优先级要高.
Run Jobs
1. 设置 inputs & output
1.1 先判断输入是否存在 (不存在会导致出错,最好利用程序来判断.)
1.2 判断输出是否已经存在(存在也会导致出错)
1.3 养成一种好的习惯(先判断,再执行)
2. 设置 mapper、reducer、combiner. 各个实现类的class对象. XXXX.class
3. 设置 inputformat & outputformat & types
3.1 input和output format都有两种, 一种是 textfile, 一种是sequencefile. 简单理解, textfile是文本组织的形式,sequence file是 二进制组织的形式.
3.2 Types的设置, 根据输入和输出的数据类型, 设置各种Writable接口的实现类的class对象.
4. 设置reduce count
4.1 reduce count可以为0, 当你的数据无需reduce的时候.
4.2 reduce数量最好稍微少于当前可用的slots的数量, 这样reduce就能在一波计算中算好. (一个slot可以理解为一个计算单元(资源).)
其他的一些细节.
1. ChainMapper可以实现链式执行mapper 他本身就是一个Mapper的实现类. 提供了一个addMapper的方法.
2. ChainReducer 跟ChainMapper类似, 可以实现链式执行reducer, 他是Reducer的实现类.
3. 多个job先后运行, 可以通过先后执行 JobClient.runJob方法来实现先后顺序
4. 扩展MultipleOutputFormat接口, 可以实现一个reduce对应多份输出 (而且可以指定文件名哦)
5. Partitioner 接口用于将 Map的输出结果进行分区, 分区相同的key对应的数据会被同一个reducer处理
5.1 提供了一个接口方法: public int getPartition(K2 key, V2 value, int numReduceTasks)
5.2 可以自己定义, 根据key的某些特指来划分, 也可以根据value的某些特质来划分.
5.3 numReduceTasks就是设置的reduce的个数.一般返回的partition的值应该都小于这个值.(%)
6. reporter的作用
6.1 reporter.incrCounter(key, amount). 比如对数据计算是, 一些不合规范的脏数据, 我们可以通过counter来记录有多少
6.2 reporter.setStatus(status); 方法可以设置一条状态消息, 当我们发现job运行出现这条消息是, 说明出现了我们预期的(错误或者正确)的情况, 用于debug.
6.3 reporter.progress(), 像mapreduce框架报告当前运行进度. 这个progress可以起到心跳的作用. 一个task要是超过10分钟没有想mapreduce框架报告情况, 这个reduce会被kill掉. 当你的任务处理会比较旧是, 最好定时向mapreduce汇报你的状态.
7. 通过实现Wriable接口, 我们可以自定义key和value的类型, 使用起来就像pojo, 不需要每次都进行parse. 如果你的自定义类型是Key的类型, 则需要同时实现Comparable 接口, 用于排序. 比如MapWritable就是一个例子.
实战.(简单篇)
简单篇:
1. 需求: 统计某个站点每天的PV
2. 数据输入: 以天为分区存放着的日志数据, 一条日志代表一个PV
3. 数据输出: 日期 PV
4. Mapper编写
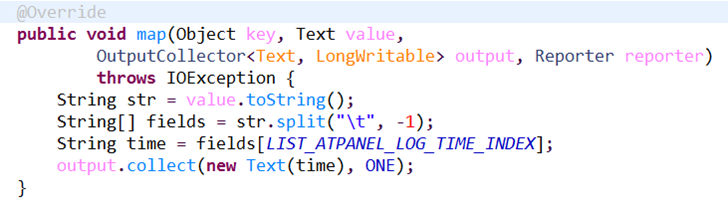
主要的工作很简单, split每一条日志, 取出日期, 并对该日期的PV搜集一条记录, 记录的value为ONE(1, 一条记录代表一个PV)
5. Reducer编写

reduce的任务是将每天(key相同的为同一天) 的日志进行汇总(sum), 最后以天为key输出汇总结果.
6. 设置环境, 指定job(Run)
6.1 设置输入路径.
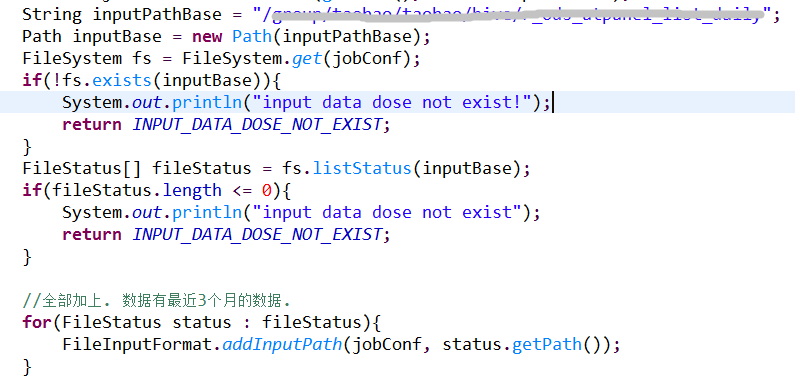
6.2 设置输出路径
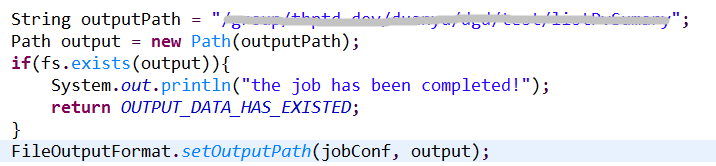
6.3 设置Mapper/Reducer和输入数据的数据格式和数据类型
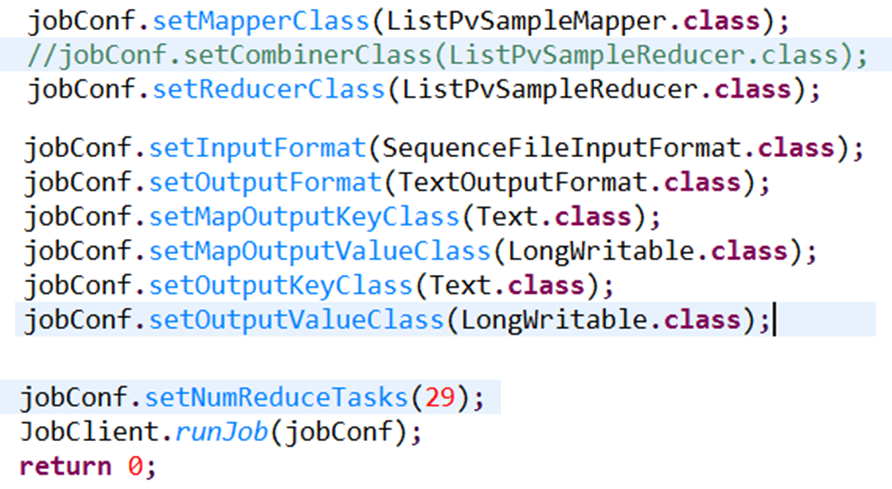
6.4 执行命令:
hadoop jar site-pv-job.jar org.jiacheo.SitePVSumSampleJob
6.5 查看hadoop的web 工具, 显示当前job进度.

可以看出, 此次输入产生了14292个map,和29个reduce. reduce数这么少是因为我的reduce的slots数只有30, 所以设置为29, 以防一个挂了, 还能在一波reduce中算好.
6.6 计算结果.
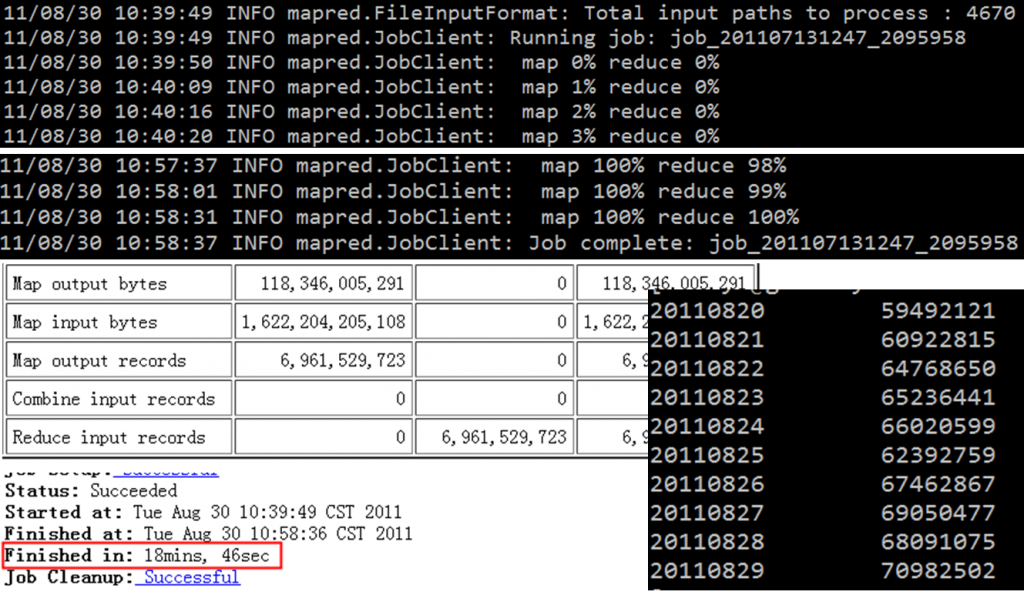
上面部分是hadoop cli客户端显示的进度, 中间是web工具显示的输入输出的一些数据的统计.可以看出, 此次输入数据总共有1.6TB大小, 设计的总记录数为69.6亿. 也就是这份数据记录了该站点的69.6亿的PV. 左下角可以看出, 执行时间比较长, 用了18分钟+46秒.这里慢的原因不在于reduce, 而是我的map的slots太少, 只有300个, 总共一万多个map, 那要分好几百波才能算完map, 所以瓶颈在map这里.右下角是统计的结果数据, 可以看出, 该站点的整体的PV是呈现上升趋势的.
至此, 一个简单的map/reduce程序就写好并运行了.





 京公网安备 11010802041100号
京公网安备 11010802041100号