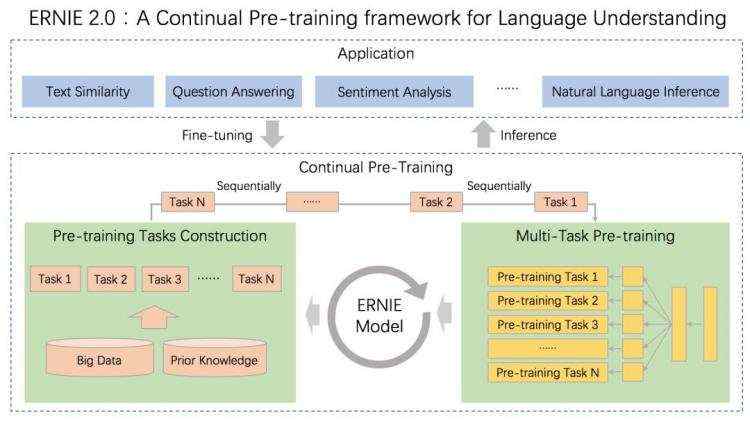
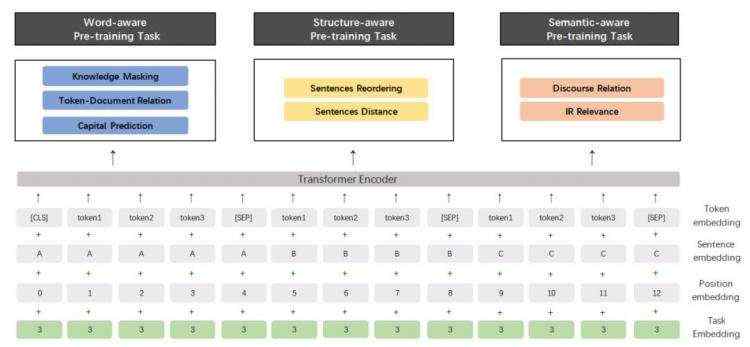
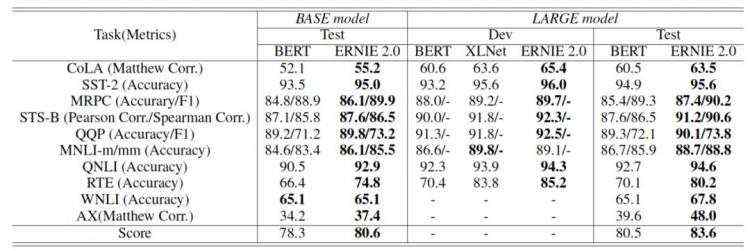
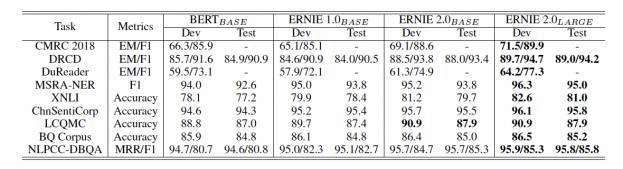
导读:2019 年 3 月,百度正式发布 NLP 模型 ERNIE,其在中文任务中全面超越 BERT 一度引发业界广泛关注和探讨。今天,百度发布了 ERNIE 2.0,指出其在英文任务方面取得全新突破,在共计 16 个中英文任务上超越了 BERT 和 XLNet,取得了 SOTA 效果。目前,ERNIE 2.0 代码和英文预训练模型已开源。
(*本文为 AI科技大本营整理文章,转载请联系微信 1092722531)
◆
精彩推荐
60+技术大咖与你相约 2019 AI ProCon!大会早鸟票已售罄,优惠票速抢进行中......2019 AI开发者大会将于9月6日-7日在北京举行,这一届AI开发者大会有哪些亮点?一线公司的大牛们都在关注什么?AI行业的风向是什么?2019 AI开发者大会,倾听大牛分享,聚焦技术实践,和万千开发者共成长。
推荐阅读
















 京公网安备 11010802041100号
京公网安备 11010802041100号