早在上古时代(那时候我大概正在读小学吧),大数据这个词还没那么火,业界对于海量数据的存储和处理相对来说比较粗糙,还在追求容量更大的硬盘、性能更强的服务器。当然了,分布式处理是有的,那时候应该是叫 网格计算 吧,就是很多的节点,然后存储是集中存放,通过SAN(storage area network)挂载到每一个计算节点上,各个节点之间通过MPI(Message Passing Interface)进行通信。
MPI 可以解决大规模的数据处理任务,但是它有着很多缺点,开发者需要自己去考虑节点间通信、节点故障检测与处理等容错、任务划分等等很细节的东西,利用MPI来处理大规模数据,可能大部分时间不是在对数据本身进行分析和处理,而是在解决层出不穷的bug。对于SAN来说,尽管有raid机制可以提升存储的可靠性,但是它没有解决节点故障带来的数据丢失问题,以及很难应付更大规模的数据存储问题,网络吞吐也往往容易成为瓶颈。
对于大数据处理,我们首先要能够存储如此大规模的数据量,其次是如何对这海量的数据进行处理,再然后是尽可能快的处理。
2003年开始Google发出的三篇论文 Google File System 、 MapReduce 、 BigTable 给大数据领域带来了曙光,分别解决了大数据存储、大数据处理,以及高效的结构化大数据存取,这三篇论文算是奠定了现代大数据处理的基石,说它是现代大数据处理的鼻祖也不为过。
诞生
不过Google并不热衷于开源(毕竟人家的工程师吊打一切,根本看不上社区的力量),只是给出了具体的设计和思路,所以当时大家也只能望梅止渴了。(现在Google也算是积极拥抱开源吧,推出了 Tensorflow 、 Kubernetes 等等powerful的项目,不过这是后话了)
尽管Google并没有开源代码,但是论文写的很详细,足够让外人按图索骥了。Nutch(一个搜索引擎,搜索引擎对于大数据处理的需求很强)的工程师 Doug Cutting 在看到这几篇论文之后开始按照论文里的设计思路来重构自己的系统,他们成功的将Hadoop部署到了数十台节点上并稳定的运行。
后来,负责人跳槽到了Yahoo!,领导一个独立的团队专门开发Hadoop系统,集群规模也开始扩大到数百个节点,并且剥离了与业务强相关的内容,逐渐成为一个通用系统。
在2008年,Hadoop成为了apache基金会的顶级开源项目,世人得以一睹Hadoop的强大,同时开源社区也逐渐成长。同年,Hadoop用时209秒完成了1T数据的 排序 任务,打破了当时的记录,并且随着不断调优,处理时间越来越短,数据量也越来越大。
蓬勃发展
相比较于MPI,Hadoop 具有可靠的大数据存储,通过冗余、容错等机制,即便是普通的服务器也能够很好的运行大数据处理任务。同时,Hadoop自带的task容错机制也使得用户能够专心数据分析任务,很少需要去关注容错。此外,MapReduce也大大简化了数据处理的复杂性,简化操作的同时也带来了可靠性。
学术界和业界都开始向Hadoop转移,贡献了很多的新功能、优化细节、bug修复,并以Hadoop为基础推出了更多的大数据处理平台,如列式存储HBase、数据仓库Hive等等,一些传统的单机算法也开始通过Hadoop走向分布式(那大概是大数据方向最好水论文的时代吧)。
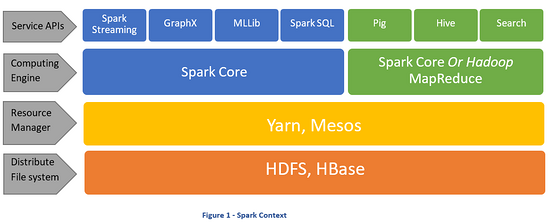
Hadoop 1 版本中资源分配与任务调度框架是跟mapredice等紧耦合的,随着Hadoop的成熟,在2.0版本时,这一套被独立出来,成为了一个通用的调度框架(YARN)供其他大数据平台使用,如Spark就支持使用YARN来做资源分配和任务调度。
老当益壮
从 2003 年到现在已经经过了16年的时光,在计算机这个飞速发展的领域,16年足以让一门技术从呱呱坠地到流行再到逐步淘汰的过程了。这么算的话,Hadoop现在也算是垂垂老矣,虽然Hadoop的热度减少,风头都被 Spark 、 Flink 等等后来者抢去了,但是依旧没有淡出人们的视线。一方面,虽然现在有了更加快、更加好用的工具,但是他们底层大多仍然依赖HDFS(一部分原因是足够好用,另一个是企业的数据迁移不便);另一方面,Hadoop也还远没有到被淘汰的地位,仍然有很多的任务用Hadoop运行,也一直在随着需求变迁而进步。我们实验室年初的一篇A会论文的实验就是在Hadoop上跑的( BENU: Distributed Subgraph Enumeration with Backtracking-based Framework )。
如果要说说Hadoop的不足之处,恐怕又能写满整整一张A4纸了:它的编程模型太过简单难以实现复杂需求、HDFS对小文件的处理能力太差、map和reduce的频繁落盘操作带来了很大的性能损失、namenode虽然支持HA但是依旧是瓶颈、基于批处理的模式使得延迟非常高、对于迭代型任务支持不好等等等等。但是Hadoop依旧有着很高的可用性,基于HDFS构建的HBase列式存储能够提供毫秒级的响应而且拓展能力很强。
现在我们说Hadoop,不仅仅是在只MapReduce、YARN这些东西,更多的是在指这个生态,从Hadoop诞生以来,有太多的组件/系统在此之上被构建,它的设计理念仍然会被新的系统所参考、借鉴。
总结
作为一个划时代的系统,Hadoop将大数据处理带上了一个新的高度。不再需要追击极致的单机性能,它的容错机制使得普通服务器就能提供可靠的服务;不再需要考虑那么多的节点协调、容错,用户只需要通过简单的接口就能完成海量数据的存储和处理工作,就像是在单机上处理这些任务一样,不需要去考虑太多的硬件故障、网络故障等;针对日益膨胀的数据,只需要简单的增加节点就可以,系统性能可以接近水平拓展。





 京公网安备 11010802041100号
京公网安备 11010802041100号