作者:jinyan胡_435 | 来源:互联网 | 2023-07-22 10:38
文章目录1Overview2Docker部署Flink&Beam2.2BeamFlink3Summary1Overview参考文章:https:medium.com0x0ecea-
文章目录
- 1 Overview
- 2 Docker 部署 Flink & Beam
- 3 Summary
1 Overview
参考文章: https://medium.com/@0x0ece/a-quick-demo-of-apache-beam-with-docker-da98b99a502a
Apache Beam 是什么?
Apache Beam 是统一的批/流数据处理的编程模型。本文主要是参考官方文档,用 Docker 来快速跑起来一个用 Beam 来构建的 Flink 程序来处理数据的 Demo。
2 Docker 部署 Flink & Beam
首先利用 Docker Compose 来将 Flink Cluster 跑起来。
git clone https://github.com/ecesena/docker-beam-flink.git
cd docker-beam-flink
然后大家可以看看文件夹的树状结构。
➜ docker-beam-flink git:(master) tree
.
├── LICENSE
├── README.md
├── base
│ ├── Dockerfile
│ └── supervisor.conf
├── beam-flink
│ ├── Dockerfile
│ └── config-flink-load-jar.sh
├── build.sh
├── docker-compose.yml
├── flink
│ ├── Dockerfile
│ ├── conf
│ │ ├── flink-conf.yaml
│ │ ├── log4j.properties
│ │ ├── logback-yarn.xml
│ │ ├── logback.xml
│ │ └── slaves
│ └── config-flink.sh
└── screenshots└── showplan.png
从文件结构看,项目中包含了三个 Dockerfile,其依赖的顺序可以是 base/Dockerfile -> flink/Dockerfile -> beam-flink/Dockerfile。
base 中的 Dockerfile 是 Ubuntu 的基础镜像,这里就不分析了。剩下的逐一分析一下,分析写在里 Dockerfile 里。
flink
FROM base# add passless key to ssh
RUN ssh-keygen -f ~/.ssh/id_rsa -t rsa -N ''
RUN cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys && chmod 600 ~/.ssh/*## 安装 Flink 1.0.3
RUN mkdir ~/downloads && cd ~/downloads && \wget -q -O - http://apache.mirrors.pair.com/flink/flink-1.0.3/flink-1.0.3-bin-hadoop26-scala_2.10.tgz | tar -zxvf - -C /usr/local/
RUN cd /usr/local && ln -s ./flink-1.0.3 flink# 设置 Dockerfile 的环境变量
ENV FLINK_HOME /usr/local/flink
ENV PATH $PATH:$FLINK_HOME/bin# 将 Flink 的一些配置放入镜像中
ADD conf/flink-conf.yaml /usr/local/flink/conf/
ADD config-flink.sh /usr/local/flink/bin/# 设置配置脚本的权限
RUN chmod +x /usr/local/flink/bin/config-flink.sh# 端口映射
EXPOSE 6123
EXPOSE 22CMD ["/usr/local/flink/bin/config-flink.sh", "taskmanager"]
beam-flink
# 从依赖的 flink 镜像开始构建镜像
FROM flink# 下载 beam-starter,可以先理解为一个预先写好的基于 Beam 的 Flink 作业
RUN curl -L https://github.com/ecesena/beam-starter/releases/download/v0.1/beam-starter-0.1.jar > /root/downloads/beam-starter-0.1.jar# 下载一段文本文件
RUN curl http://www.gutenberg.org/cache/epub/1128/pg1128.txt > /tmp/kinglear.txt# 将本地的文件复制到镜像的目录里
ADD config-flink-load-jar.sh /usr/local/flink/bin/# Flink 上传 jar 包的脚本
RUN chmod +x /usr/local/flink/bin/config-flink-load-jar.sh# 运行 taskmanager
CMD ["/usr/local/flink/bin/config-flink.sh", "taskmanager"]
以上 Dockerfile 其实很容易理解,就不赘述了。然后用 docker-compose 来运行 Flink。
docker-compose up -d
运行之后,可以看看 Docker 正在 Running 的容器就有了。
➜ docker-beam-flink git:(master) docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2de232e58df8 dataradiant/beam-flink "/usr/local/flink/bi…" 6 hours ago Up 6 hours 6121-6123/tcp, 0.0.0.0:32768->22/tcp docker-beam-flink_taskmanager_1
98b52be9c56e dataradiant/beam-flink "/usr/local/flink/bi…" 6 hours ago Up 6 hours 6123/tcp, 0.0.0.0:220->22/tcp, 0.0.0.0:48080->8080/tcp, 0.0.0.0:48081->8081/tcp docker-beam-flink_jobmanager_1
现在呢,我们基于上面的项目已经运行起来一个 Flink 集群,接下来,我们用 beam 的 Flink Runner 来跑起来一个 Flink 程序。
2.2 Beam Flink
打开 Flink 的 Web UI,然后在 Submit new Job 去提交作业。
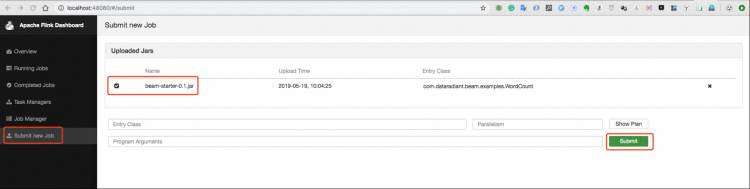
按照上图提示,提交的 jar 包是我们打镜像文件的时候打进去的。关于这个项目,我们可以先看看目录结构。
├── LICENSE
├── README.md
├── pom.xml
└── src├── main│ └── java│ └── com│ └── dataradiant│ └── beam│ ├── App.java│ └── examples│ ├── StreamWordCount.java│ └── WordCount.java└── test└── java└── com└── dataradiant└── beam└── AppTest.java
所以其实很容易理解,这个示例工程,其实就是基于 Beam 来创建的一个 Flink WordCount 程序而已。关于 WordCount 程序,核心代码如下。
Options options = PipelineOptionsFactory.fromArgs(args).withValidation().as(Options.class);
options.setRunner(FlinkRunner.class);
Pipeline p = Pipeline.create(options);p.apply("ReadLines", TextIO.Read.from(options.getInput())).apply(new CountWords()).apply(MapElements.via(new FormatAsTextFn())).apply("WriteCounts", TextIO.Write.to(options.getOutput()));p.run();
3 Summary
本文就是一个具体的例子,展示了如何用 Beam 来构建 Flink 作业,并且用 Docker 来运行这个程序。







 京公网安备 11010802041100号
京公网安备 11010802041100号