作者:手机用户2502931823 | 来源:互联网 | 2023-06-23 02:32
目录
1.写在前面
2.Maven依赖
3.代码实现-普通实现
4.集群测试
4.1 环境准备
4.2 查看任务结果
1.写在前面
Flink CDC有两种实现方式,一种是DataStream,另一种是FlinkSQL方式。
- DataStream方式:优点是可以应用于多库多表,缺点是需要自定义反序列化器(灵活)
- FlinkSQL方式:优点是不需要自定义反序列化器,缺点是只能应用于单表查询
2.Maven依赖
org.apache.flinkflink-java1.12.7org.apache.flinkflink-streaming-java_2.121.12.7org.apache.flinkflink-clients_2.121.12.7org.apache.hadoophadoop-client2.7.7mysqlmysql-connector-java5.1.49com.alibaba.ververicaflink-connector-mysql-cdc1.2.0com.alibabafastjson1.2.75org.apache.flinkflink-table-planner-blink_2.121.12.7org.apache.maven.pluginsmaven-assembly-plugin3.0.0jar-with-dependenciesmake-assemblypackagesingleorg.apache.maven.pluginsmaven-compiler-plugin88
3.代码实现-普通实现
package com.atguigu;import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;public class FlinkCDCWithSQL {public static void main(String[] args) throws Exception {//1.获取执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);//2.DDL方式建表,flink_sql的方式只能监控一张表tableEnv.executeSql("CREATE TABLE mysql_binlog ( " +" id STRING NOT NULL, " +" tm_name STRING, " +" logo_url STRING " +") WITH ( " +" 'connector' = 'mysql-cdc', " +" 'hostname' = '192.168.0.111', " +" 'port' = '3306', " +" 'username' = 'root', " +" 'password' = '123456', " +" 'database-name' = 'gmall2021', " +" 'table-name' = 'base_trademark' " +")");//3.查询数据Table table = tableEnv.sqlQuery("select * from mysql_binlog");//4.将动态表转换为流DataStream> retractStream = tableEnv.toRetractStream(table, Row.class);retractStream.print();//5.启动任务env.execute("FlinkCDCWithSQL");}}
4.集群测试
4.1 环境准备
- 启动ha-hadoop集群:sh ha-hadoop.sh start
-
创建作业归档目录,只需要创建一次:hdfs dfs -mkdir /flink-jobhistory
-
启动Flink集群和任务历史服务
- start-cluster.sh
- historyserver.sh start
- 运行该Flink任务:/opt/software/flink-1.12.7/bin/flink run -m yarn-cluster -ys 1 -ynm gmall-flink-cdc -c com.ucas.FlinkCDCWithCustomerDeserialization -d /root/mySoftware/gmall-flink-cdc.jar
4.2 查看任务结果
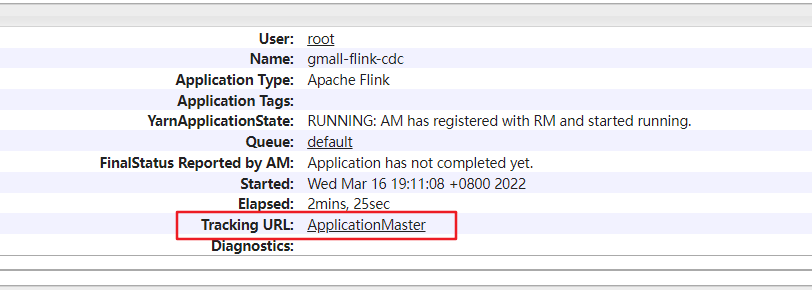
(1)打开yarn,查看任务:http://192.168.0.112:8088/cluster/apps,并且通过id点击进去
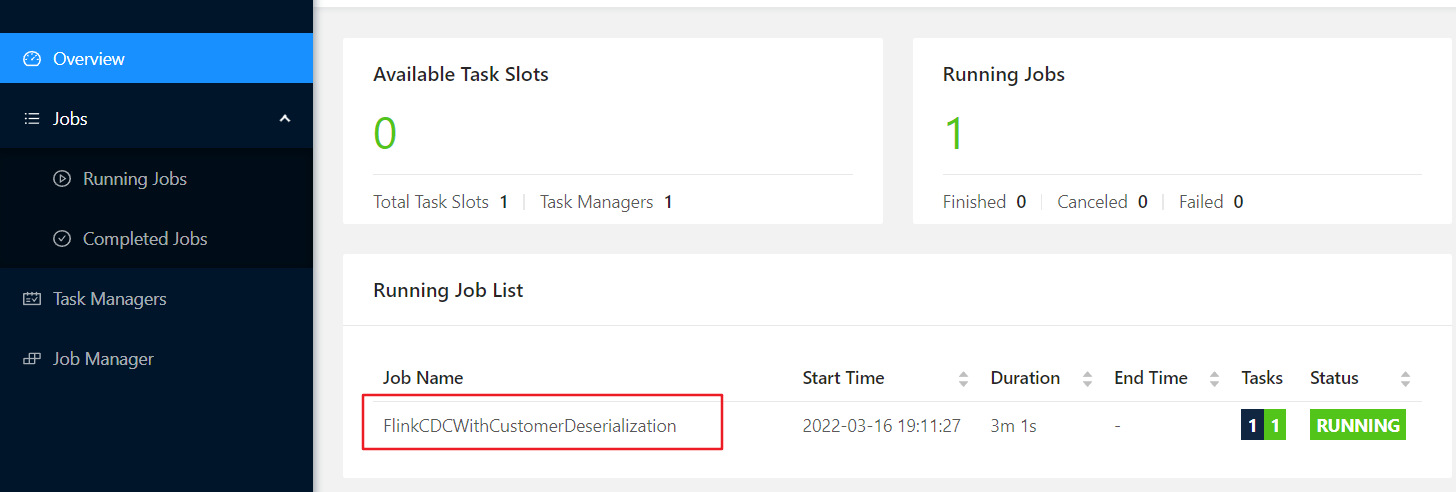
 (2)点击Tracking URL,进入FlinkWeb界面
(2)点击Tracking URL,进入FlinkWeb界面
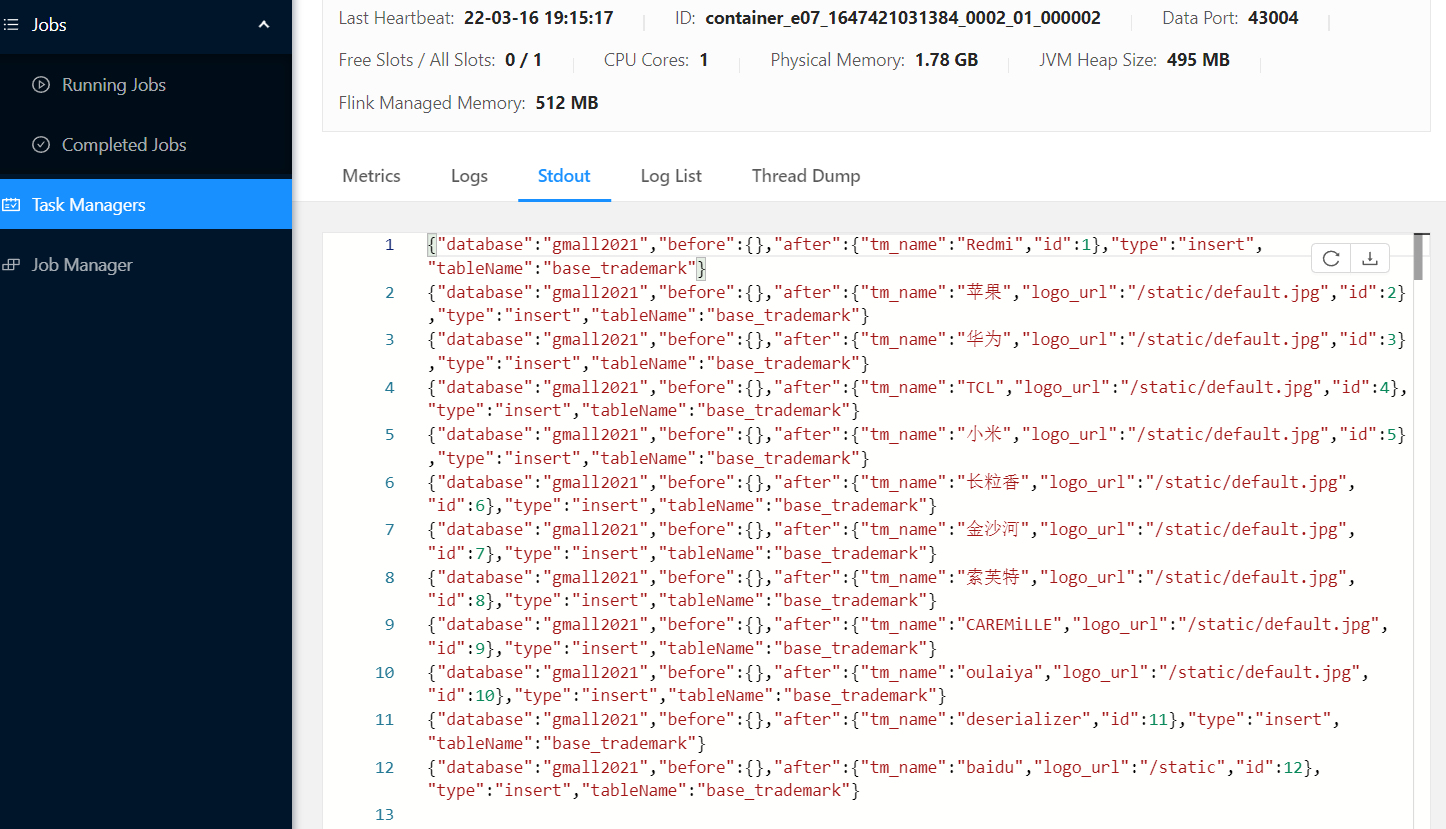
(3) 打开左侧TaskManagers中的Stdout查看控制台输出信息



 京公网安备 11010802041100号
京公网安备 11010802041100号