作者:诸暨巴黎婚纱 | 来源:互联网 | 2023-08-23 10:31

最近有小伙伴报喜,说终于拿到了鹅厂的Offer,3面时还只问了Kafka的吞吐设计!今天就给大家展开讲一讲大热的Kafka!
容器、Kubernetes、DevOps、微服务、云原生,这些技术名词的频繁出现,预兆着新的互联网技术时代的到来,大数据高并发将不再遥远,而是大部分项目都必须具备的能力了,而消息队列是必备的了。成熟的消息队列产品很多,说到海量数据下高吞吐高并发,Kafka不是针对谁,毋庸置疑的首选!
Kafka是一个分布式的基于发布订阅的消息队列,有着无与伦比的消息处理能力,相比与其他消息系统,具有以下特性:
正是因为Kafka优异的表现,现在已经被广泛应用于海量日志收集、大数据处理、流式处理等场景!下面我们来探讨下,Kafka到底是如何做到这么高的吞吐量和性能的呢?
首先,Kafka的消息数据是写在硬盘上的,保证了消息数据的可靠性,但写硬盘还能保证几十万条/秒的消息处理速度,是怎么做到的?
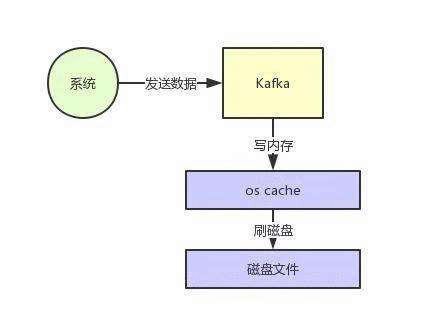
因为Kafka在这里有极为优秀和出色的设计!为了保证数据的写入性能,Kafka是基于操作系统的页缓存来实现文件写入的。
页缓存page cache,是操作系统自己管理的内存缓存,也叫os cache。写入消息时,是直接写入这个页缓存里,然后由操作系统自己决定什么时候把页缓存里的数据真的刷入磁盘文件中。
这样一来,消息写入性能就变成了写内存,不是在写磁盘,请看下图。
Kafka高性能写入的再一个设计是磁盘顺序写。一般磁盘写入都是随机写,随便找到文件的某个位置来写数据,这样的性能非常差,但是追加文件末尾按照顺序的方式来写数据的话,其写入性能跟写内存的性能差不多。
总结下, Kafka在写数据的时候,一方面基于了操作系统的page cache来写数据,另一方面是采用磁盘顺序写的方式,就实现了写入数据的超高性能,才能做到在普通服务器上每秒写入几十万条消息。
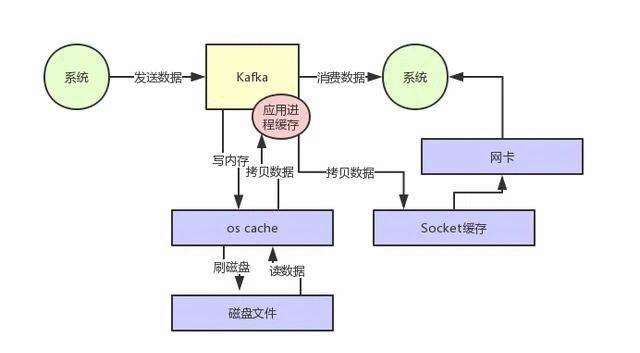
解决了写入问题,那消息读取呢?频繁的从磁盘读数据然后发给消费者,性能又是如何保证的?Kafka为了解决这个问题,在读数据的时候是引入零拷贝技术。
先看图1是常规的硬盘读写流程,操作系统读取硬盘数据后放在OS Cache,然后需要拷贝一次到Kafka进程,然后Kafka再将数据拷贝到Socket缓存才能发送到网卡,这样流程的性能当然没有保障。
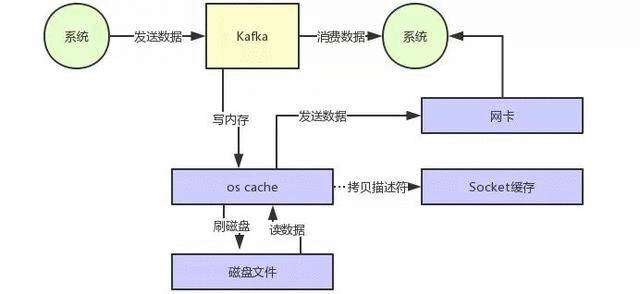
再看图2, Kafka的设计为直接将操作系统OS Cache中的数据发送到网卡,跳过了两次拷贝数据的步骤,Socket缓存中仅仅会拷贝一个描述符过去,不会拷贝数据到Socket缓存,大大提升了数据读取性能。

微服务、高并发、JVM调优、面试专栏等20大进阶架构师专题请关注公众号【RocketMQ】后在菜单栏查看。













 京公网安备 11010802041100号
京公网安备 11010802041100号