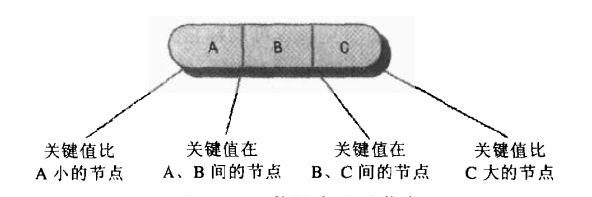
一、什么是2-3-4树
2-3-4树和红黑树一样,也是平衡树。只不过不是二叉树,它的子节点数目可以达到4个。
每个节点存储的数据项可以达到3个。名字中的2,3,4是指节点可能包含的子节点数目。具体而言:
1、若父节点中存有1个数据项,则必有2个子节点。
2、若父节点中存有2个数据项,则必有3个子节点。
3、若父节点中存有3个数据项,则必有4个子节点。
也就是说子节点的数目是父节点中数据项的数目加一。因为以上三个规则,使得除了叶结点外,其他节点必有2到4个子节点,不可能只有一个子节点。所以不叫1-2-3-4树。而且2-3-4树中所有叶结点总是在同一层。
二、如何构建2-3-4树。
首先需要明白二叉树一般不允许出现重复的关键字。分析问题时就不考虑这种情况。
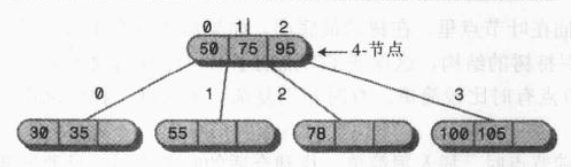
构建原则:
实例:
对于包含1或2个数据项的节点,构造原则相同。
搜索2-3-4树:
与二叉树方法类似,只不过比较过程较为复杂,处于不同的数据段之间转向不同的子树。结合上面的构造方法更好理解。
插入操作:
新的数据项总是插入在叶结点中,在树的最底层。这时可能有两种情况:
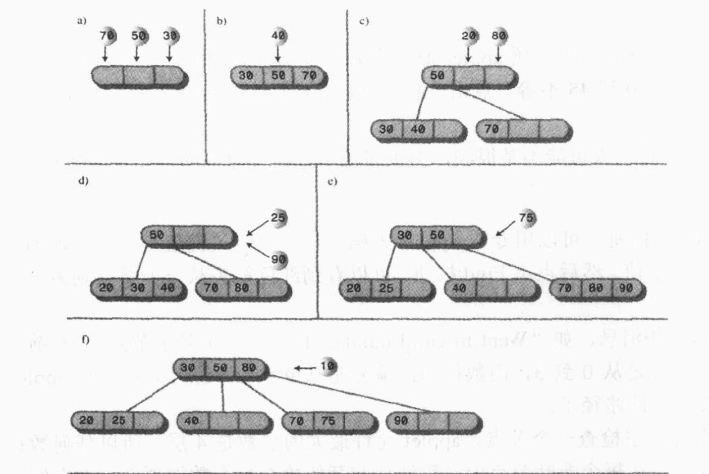
1.未遇到满节点
这种情况较为简单,只需找到相应的位置插入数据即可。
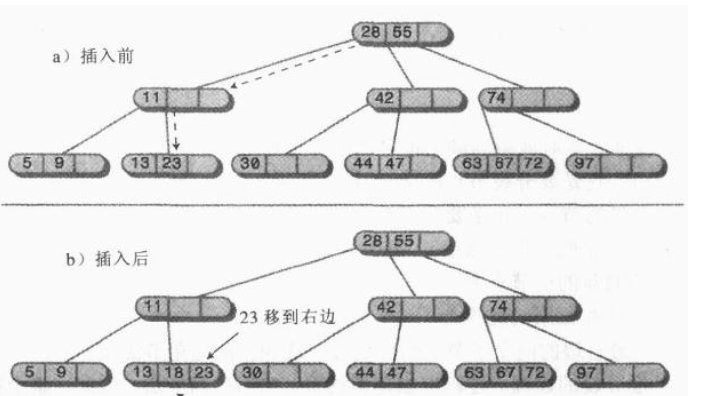
如下例:插入数据18
2、遇到满节点情况:
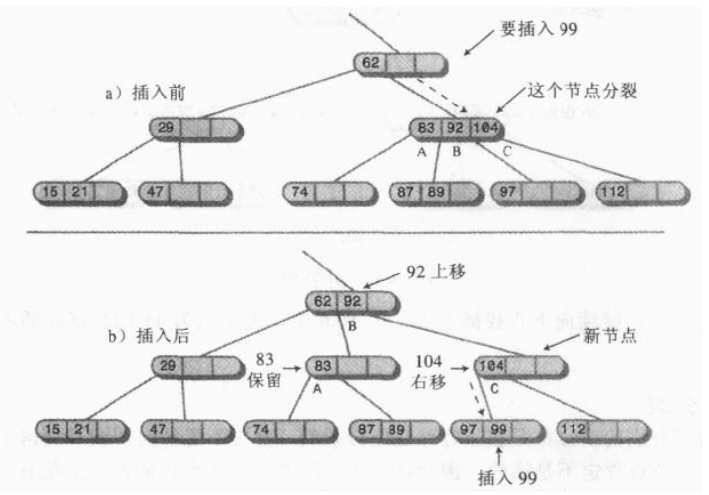
为了保证树的平衡和2-3-4树的结构,需要进行分裂操作。从上到下寻找插入位置时遇到的任何一个满节点都要进行分裂操作。
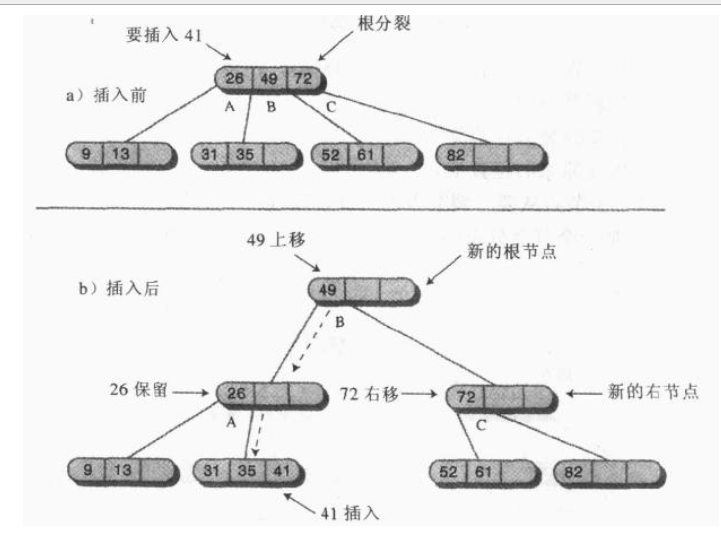
假设满节点中的数据项为A,B,C。根据节点是不是根又分为两种情况。
(1)满节点不是根
分裂方法:
·创建一个新的节点,与要分裂的节点是兄弟,且放在其右侧。
·把数据项C移动到新节点中。
·将数据项B移到父节点中的相应位置。
·将数据项A保留在原节点中。
·把原节点最右边的两个子节点(原节点为满节点,则一定有四个子节点或者是叶结点)从要分裂的节点上断开,连接到新的节点上。
实例:插入99
(2)满节点是根节点
分裂方法:
·创建一个新的根,作为要分裂节点的父节点。
·再创建一个新的节点,作为要分裂节点的兄弟节点,位于其右侧。
·数据项C移动到兄弟节点中。
·数据项B移动到父节点中。
·数据项A保留在原节点。
·把要分裂节点的最右边的两个子节点断开连接,重新连接到兄弟节点上。
实例:插入41
查找是从上到下的,所以分裂也是从最上方的满节点开始。这也保证了要分裂的节点的父节点一定是不满的,否则应该先分裂父节点。
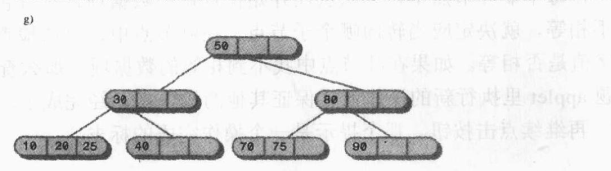
2-3-4树的完整构造过程:
三、2-3-4树的java实现代码
DataItem类表示节点中存储的数据项的数据类型。
class DataItem
{
public long dData; // 存储的数据类型,可以为其他复杂的对象或自定义对象
//--------------------------------------------------------------
public DataItem(long dd) // 构造函数{ dData = dd; }
//--------------------------------------------------------------
public void displayItem() // 显示数据{ System.out.print("/"+dData); }
//--------------------------------------------------------------
} // end class DataItem
Node类提供了三个重要方法:
findItem:依据关键字在当前节点的数据项数组itemArray中查找。
insertItem:把数据项插入到itemArray中,并保持有序
removeItem:根据关键字在itemArray中移除相应的数据项,并保持有序。
class Node
{
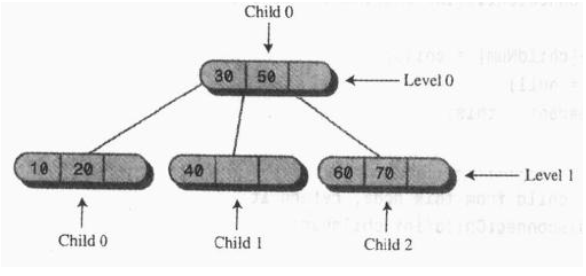
private static final int ORDER = 4;
private int numItems;//节点中实际存储的数据项数目,其值一定不大于3
private Node parent;
private Node childArray[] = new Node[ORDER];//子节点数组
private DataItem itemArray[] = new DataItem[ORDER-1];//存储数据项数组
//-------------------------------------------------------------
// 把参数中的节点作为子节点,与当前节点进行连接
public void connectChild(int childNum, Node child){childArray[childNum] = child;if(child != null)child.parent = this;//当前节点作为父节点}
//-------------------------------------------------------------
// 断开参数确定的节点与当前节点的连接,这个节点一定是当前节点的子节点。
public Node disconnectChild(int childNum){Node tempNode = childArray[childNum];childArray[childNum] = null; //断开连接return tempNode;//返回要这个子节点}
//-------------------------------------------------------------
public Node getChild(int childNum)//获取相应的子节点{ return childArray[childNum]; }
//-------------------------------------------------------------
public Node getParent()//获取父节点{ return parent; }
//-------------------------------------------------------------
public boolean isLeaf()//是否是叶结点{ return (childArray[0]==null) ? true : false; }//叶结点没有子节点
//-------------------------------------------------------------
public int getNumItems()//获取实际存储的数据项数目{ return numItems; }
//-------------------------------------------------------------
public DataItem getItem(int index) // 获取具体的数据项{ return itemArray[index]; }
//-------------------------------------------------------------
public boolean isFull()//该节点是否已满{ return (numItems==ORDER-1) ? true : false; }
//-------------------------------------------------------------
public int findItem(long key) // 查找{ for(int j=0; j
public int insertItem(DataItem newItem)//节点未满的插入{numItems++; long newKey = newItem.dData; // 获得关键字for(int j=ORDER-2; j>=0; j--) // 因为节点未满,所以从倒数第二项向前查找{ if(itemArray[j] == null) // 没存数据continue; else { long itsKey = itemArray[j].dData;//获得关键字if(newKey
public DataItem removeItem() // 移除数据项,从后向前移除{// 假设节点非空DataItem temp = itemArray[numItems-1]; // 要移除的数据项itemArray[numItems-1] = null; // 移除numItems--; // 数据项数目减一return temp; // 返回要移除的数据项}
//-------------------------------------------------------------
public void displayNode() // format "/24/56/74/"{for(int j=0; j
} // end class Node
关键方法
find:根据关键字查找树中是否存在。从根开始,依次调用getNextChild方法来向下查找,在每个节点上都调用Node类中的findItem方法在当前节点中查找。当在底层的叶结点查找完毕,整个查找过程就结束了。若仍未找到,则查找失败,返回-1。
insert:与find方法类似,不断向下查找,直到叶结点,插入数据项。这个过程中遇到满节点会先执行分裂操作,调用split方法,再来插入数据项。
split:按照之前介绍的分裂方法进行分裂。
class Tree234
{
private Node root = new Node(); // 创建树的根
//-------------------------------------------------------------
//获取查找的下一个节点
public Node getNextChild(Node theNode, long theValue)
{
int j;
// 假设这个节点不是叶结点
int numItems = theNode.getNumItems();//获得当前节点的数据项数目
for(j=0; j
}
//-------------------------------------------------------------
public int find(long key){Node curNode = root;int childNumber;while(true){if(( childNumber=curNode.findItem(key) ) != -1)//每次循环这句一定执行return childNumber; // found itelse if( curNode.isLeaf() )//叶结点上也没找到return -1; // can't find itelse // 不是叶结点,则继续向下查找curNode = getNextChild(curNode, key);} // end while}
//-------------------------------------------------------------
// 插入数据项
public void insert(long dValue){Node curNode = root;//当前节点标志DataItem tempItem = new DataItem(dValue);//插入数据项封装while(true){if( curNode.isFull() ) // 是满节点{split(curNode); // 分裂curNode = curNode.getParent(); // 回到分裂出的父节点上// 继续向下查找curNode = getNextChild(curNode, dValue);} // end if(node is full)
//后面的操作中节点都未满,否则先执行上面的代码else if( curNode.isLeaf() ) // 是叶结点,非满break; // 跳出,直接插入elsecurNode = getNextChild(curNode, dValue);//向下查找} // end whilecurNode.insertItem(tempItem); // 此时节点一定不满,直接插入数据项,} // end insert()
//-------------------------------------------------------------
public void split(Node thisNode) // 分裂{// 操作中节点一定是满节点,否则不会执行该操作DataItem itemB, itemC;Node parent, child2, child3;int itemIndex;itemC = thisNode.removeItem(); // 移除最右边的两个数据项,并保存为B和CitemB = thisNode.removeItem(); // child2 = thisNode.disconnectChild(2); // //断开最右边两个子节点的链接child3 = thisNode.disconnectChild(3); // Node newRight = new Node(); //新建一个节点,作为当前节点的兄弟节点if(thisNode==root) // 是根{root = new Node(); // 新建一个根parent = root; // 把新根设为父节点root.connectChild(0, thisNode); // 连接父节点和子节点}else // 不是根parent = thisNode.getParent(); // 获取父节点itemIndex = parent.insertItem(itemB); // 把B插入父节点中,返回插入位置int n = parent.getNumItems(); // 获得总数据项数目for(int j=n-1; j>itemIndex; j--) //从后向前移除{ Node temp = parent.disconnectChild(j); // 断开连接parent.connectChild(j+1, temp); // 连接到新的位置}parent.connectChild(itemIndex+1, newRight);//连接到新位置// 处理兄弟节点newRight.insertItem(itemC); // 将C放入兄弟节点中newRight.connectChild(0, child2); // 把子节点中最右边的两个连接到兄弟节点上newRight.connectChild(1, child3); //} // end split()
//-------------------------------------------------------------
// gets appropriate child of node during search for valuepublic void displayTree(){recDisplayTree(root, 0, 0);}
//-------------------------------------------------------------
private void recDisplayTree(Node thisNode, int level,int childNumber){System.out.print("level="+level+" child="+childNumber+" ");thisNode.displayNode(); // display this node// call ourselves for each child of this nodeint numItems = thisNode.getNumItems();for(int j=0; j
} // end class Tree234
Tree234App类,实现具体操作的main函数
import java.io.*;class Tree234App插入数据10,20,30,40,50,60,70后形成的2-3-4树为
{
public static void main(String[] args) throws IOException{long value;Tree234 theTree = new Tree234();theTree.insert(50);theTree.insert(40);theTree.insert(60);theTree.insert(30);theTree.insert(70);while(true){System.out.print("Enter first letter of ");System.out.print("show, insert, or find: ");char choice = getChar();switch(choice){case 's':theTree.displayTree();break;case 'i':System.out.print("Enter value to insert: ");value = getInt();theTree.insert(value);break;case 'f':System.out.print("Enter value to find: ");value = getInt();int found = theTree.find(value);if(found != -1)System.out.println("Found "+value);elseSystem.out.println("Could not find "+value);break;default:System.out.print("Invalid entry\n");} // end switch} // end while} // end main()
//--------------------------------------------------------------
public static String getString() throws IOException{InputStreamReader isr = new InputStreamReader(System.in);BufferedReader br = new BufferedReader(isr);String s = br.readLine();return s;}
//--------------------------------------------------------------
public static char getChar() throws IOException{String s = getString();return s.charAt(0);}//-------------------------------------------------------------
public static int getInt() throws IOException{String s = getString();return Integer.parseInt(s);}
//-------------------------------------------------------------
} // end class Tree234App
心得:
* 1、首先分析一个大操作分为几个部分,先进行什么操作,再进行什么操作,把操作的顺序和操作的类别搞清楚。
* 2、抽象出每个小的操作过程,不考虑具体实现,封装成函数名称。
* 3、对操作过程进行具体分析,从上到下,对每一种可能情况进行具体分析,这可能会涉及更具体的操作,可以根据情况直接实现。,或者再一次进行函数的封装。
* 4、编写具体函数从下到上,先分析小的操作实现,一步一步到大的操作上去。




 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有