作者:大学教授也是砖家 | 来源:互联网 | 2023-06-07 22:49
目录
Kafka快速回顾
消息队列:
发布/订阅模式:
Kafka 重要概念:
常用命令
整合说明
两种方式
两个版本API
在实际项目中,无论使用Storm还是SparkStreaming与Flink,主要从Kafka实时消费数据进行处理分析,流式数据实时处理技术架构大致如下:

技术栈: Flume/SDK/Kafka Producer API -> KafKa —> SparkStreaming/Flink/Storm(Hadoop YARN) -> Redis -> UI
1)、阿里工具Canal:监控MySQL数据库binlog文件,将数据同步发送到Kafka Topic中https://github.com/alibaba/canalhttps://github.com/alibaba/canal/wiki/QuickStart2)、Maxwell:实时读取MySQL二进制日志binlog,并生成 JSON 格式的消息,作为生产者发送给 Kafka,Kinesis、RabbitMQ、Redis、Google Cloud Pub/Sub、文件或其它平台的应用程序。http://maxwells-daemon.io/https://github.com/zendesk/maxwell
扩展:Kafka 相关常见面试题:
1)、Kafka 集群大小(规模),Topic分区函数名及集群配置?2)、Topic中数据如何管理?数据删除策略是什么?3)、如何消费Kafka数据?4)、发送数据Kafka Topic中时,如何保证数据发送成功?
Apache Kafka: 最原始功能【消息队列】,缓冲数据,具有发布订阅功能(类似微信公众号)。
Kafka快速回顾
Kafka 是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用与大数据实时处理领域。
消息队列:
Kafka 本质上是一个 MQ(Message Queue),使用消息队列的好处?(面试会问)
- 解耦:允许我们独立的扩展或修改队列两边的处理过程;
- 可恢复性:即使一个处理消息的进程挂掉,加入队列中的消息仍可以在系统恢复后被处理;
- 缓冲:有助于解决生产消息和消费消息的处理速度不一致的情况;
- 灵活性&峰值处理能力:不会因为突发的超负荷的请求而完全崩溃,消息队列能够使关键组件顶住突发的访问压力;
- 异步通信:消息队列允许用户把消息放入队列但不立即处理它;
发布/订阅模式:

一对多,生产者将消息发布到 Topic 中,有多个消费者订阅该主题,发布到 Topic 的消息会被所有订阅者消费,被消费的数据不会立即从 Topic 清除。
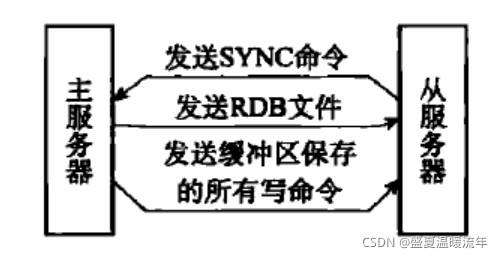
Kafka 框架架构图如下所示:

Kafka 存储的消息来自任意多被称为 Producer 生产者的进程,数据从而可以被发布到不同的 Topic 主题下的不同 Partition 分区。在一个分区内,这些消息被索引并连同时间戳存储在一起。其它被称为 Consumer 消费者的进程可以从分区订阅消息。Kafka 运行在一个由一台或多台服务器组成的集群上,并且分区可以跨集群结点分布。
Kafka 重要概念:
1)、Producer: 消息生产者,向 Kafka Broker 发消息的客户端;
2)、Consumer:消息消费者,从 Kafka Broker 取消息的客户端;
3)、Consumer Group:消费者组(CG),消费者组内每个消费者负责消费不同分区的数据,提高消费能力。一个分区只能由组内一个消费者消费,消费者组之间互不影响。所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者;
4)、Broker:一台 Kafka 机器就是一个 Broker。一个集群由多个 Broker 组成。一个 Broker 可以容纳多个 Topic;
5)、Topic:可以理解为一个队列,Topic 将消息分类,生产者和消费者面向的是同一个 Topic;
6)、Partition:为了实现扩展性,提高并发能力,一个非常大的 Topic 可以分布到多个 Broker (即服务器)上,一个 Topic 可以分为多个 Partition,每个 Partition 是一个 有序的队列;
7)、Replica:副本,为实现备份的功能,保证集群中的某个节点发生故障时,该节点上的 Partition 数据不丢失,且 Kafka 仍然能够继续工作,Kafka 提供了副本机制,一个 Topic 的每个分区都有若干个副本,一个 Leader 和若干个 Follower;
8)、Leader:每个分区多个副本的“主”副本,生产者发送数据的对象,以及消费者消费数据的对象,都是 Leader;
9)、Follower:每个分区多个副本的“从”副本,实时从 Leader 中同步数据,保持和 Leader 数据的同步。Leader 发生故障时,某个 Follower 还会成为新的 Leader;
10)、Offset:消费者消费的位置信息,监控数据消费到什么位置,当消费者挂掉再重新恢复的时候,可以从消费位置继续消费;
11)、Zookeeper:Kafka 集群能够正常工作,需要依赖于 Zookeeper,Zookeeper 帮助 Kafka 存储和管理集群信息;
常用命令
#启动kafka/export/server/kafka/bin/kafka-server-start.sh -daemon /export/server/kafka/config/server.properties #停止kafka/export/server/kafka/bin/kafka-server-stop.sh #查看topic信息/export/server/kafka/bin/kafka-topics.sh --list --zookeeper node1:2181#创建topic/export/server/kafka/bin/kafka-topics.sh --create --zookeeper node1:2181 --replication-factor 1 --partitions 3 --topic test#查看某个topic信息/export/server/kafka/bin/kafka-topics.sh --describe --zookeeper node1:2181 --topic test#删除topic/export/server/kafka/bin/kafka-topics.sh --zookeeper node1:2181 --delete --topic test#启动生产者--控制台的生产者--一般用于测试/export/server/kafka/bin/kafka-console-producer.sh --broker-list node1:9092 --topic spark_kafka# 启动消费者--控制台的消费者/export/server/kafka/bin/kafka-console-consumer.sh --bootstrap-server node1:9092 --topic spark_kafka --from-beginning
整合说明
两种方式
Receiver-based Approach:
1.KafkaUtils.createDstream基于接收器方式,消费Kafka数据,已淘汰,企业中不再使用;
2.Receiver作为常驻的Task运行在Executor等待数据,但是一个Receiver效率低,需要开启多个,再手动合并数据(union),再进行处理,很麻烦;
3.Receiver那台机器挂了,可能会丢失数据,所以需要开启WAL(预写日志)保证数据安全,那么效率又会降低;
4.Receiver方式是通过zookeeper来连接kafka队列,调用Kafka高阶API,offset存储在zookeeper,由Receiver维护;
5.Spark在消费的时候为了保证数据不丢也会在Checkpoint中存一份offset,可能会出现数据不一致;
Direct Approach (No Receivers):
1.KafkaUtils.createDirectStream直连方式,Streaming中每批次的每个job直接调用Simple Consumer API获取对应Topic数据,此种方式使用最多,面试时被问的最多;
2.Direct方式是直接连接kafka分区来获取数据,从每个分区直接读取数据大大提高并行能力
3.Direct方式调用Kafka低阶API(底层API),offset自己存储和维护,默认由Spark维护在checkpoint中,消除了与zk不一致的情况 ;
4.当然也可以自己手动维护,把offset存在MySQL/Redis中;

两个版本API
Spark Streaming与Kafka集成,有两套API,原因在于Kafka Consumer API有两套,文档:
http://spark.apache.org/docs/2.4.5/streaming-kafka-integration.html
1. Kafka 0.8.x版本 -早已淘汰
- 底层使用老的KafkaAPI:Old Kafka Consumer API
- 支持Receiver(已淘汰)和Direct模式:
2.Kafka 0.10.x版本-开发中使用
- 底层使用新的KafkaAPI: New Kafka Consumer API
- 只支持Direct模式









 京公网安备 11010802041100号
京公网安备 11010802041100号