作者:挽木城祠_ | 来源:互联网 | 2023-08-23 19:53
文章目录
- 一、热身赛
- 二、初赛
- 三、code记录
- 初赛两篇不错的总结
- 三、复活赛
- 四、复活赛其他组共享代码
- 五、民间数据集
一、热身赛
编程闯关:
用户贷款风险预测。要求参赛者建立准确的风控模型,预测用户是否会逾期还款。
评价标准:
速度为王,只要速度够快,准确率可以忽略不计。

问题分析
二分类问题:采用logistic回归算法对用户类型进行分类。
在此分类算法上依次采用L2正则化、影子滑动平均、学习衰减率、随机梯度下降、自适应梯度下降等优化策略。以提高收敛速度,保证泛化能力。
最终结果:不堪入目。
二、初赛
问题描述
通过金融风控的资金流水分析,可有效识别循环转账,辅助公安挖掘洗钱组织,帮助银行预防信用卡诈骗。基于给定的资金流水,检测并输出指定约束条件的所有循环转账。
评价标准:
在保证准确率的基础之上,速度为王!
结果一定要100%正确,否则无法参与评分。
问题分析
在有向图结构中找出所有长度在[3,7]的简单环,并按规则输出。详细规则 gitee链接-coding记录 中有记录。
思路一:
采用vector储存所有顶点信息,list存储所有边结构信息。采用 深度优先搜索+破环边结构 的方法搜索所有简单环。在官方给的56环数据中,该思路能正确运行;但在线上运行失败。故此路不通。
思路二:
先采用tarjan算法找出图中所有强连通子图;其后在各强连通子图采用johnson算法中寻找所有简单环。
此算法适用于强连通子图比较多的图结构。大赛线上表现一般。
推荐一位小哥的视频,该视频很好地讲诉了该算法的思路。
johnson找环算法视频
思路三:
暴力找环法。依次针对每个节点递归7层结构,只找以此节点为开头的环。该法能确保结果正确,但存在大量重复查找的过程。
针对思路三的提速:
提速一:改变图的存储结构,使用二维数组储存邻接表结构的图,提高访问速度。针对文件的输入,有两种方式。
一种是有序的图结构(按id大小排序):采用set记录所有顶点,并按顶点id大小排序。采用unordered_multimap储存所有边结构。采用unordered_map绑定顶点id与索引号。最终使得图结构按 ID升序排列。顶点ID+边顶点索引号。
一种是无序结构:采用unordered_map绑定顶点与其索引号,将边结构顶点的索引号(按查找的方式,从unordered_map对象中获得。 顶点ID顺序与其添加顺序有关。顶点ID+边顶点索引号。
提速二:每个起始结点只找比自己id号大的环结构,这样可保证输出的排序规则。
提速三:采用四线程,将数据分成4部分分别查找,最终将所有结果综合排序。
class Timer
{
public:Timer() : beg_(clock_::now()) {}void reset() { beg_ = clock_::now(); }double elapsed() const {return std::chrono::duration_cast<second_>(clock_::now() - beg_).count();}void out(std::string message = "") {double t = elapsed();std::cout << message << " elasped time:" << t << "s" << std::endl;reset();}
private:typedef std::chrono::high_resolution_clock clock_;typedef std::chrono::duration<double, std::ratio<1> > second_;std::chrono::time_point<clock_> beg_;
};Timer t;
t.out("Tatal");
#include
#include
#includestd::future <void> m1 = std::async(FFCC1, std::ref(g)); std::future <void> m2 = std::async(FFCC2, std::ref(g)); std::future <void> m3 = std::async(FFCC3, std::ref(g)); g.FC(); m1.wait();m2.wait();m3.wait();
提速四:一个剪枝的方法。递归消除所有出度为0的结点。
效果一般、牛人太多
团队最优成绩:4.9s
个人最好成绩:5.1s
三、code记录
gitee链接-coding记录
g++ -O3 baseline.cpp -o test -lpthread
perf stat ./test
推荐操纵服务器的两款不错的工具:
往服务器传送文件:WinSCP、Xftp6
命令行操纵服务器:Xshell6、putty
分享一个能找出所有环的baseline.cpp代码(待优化)。比赛结束了我才发现。。。。。
baseline.cpp
初赛两篇不错的总结
知乎大佬:图中所有简单环查找算法研究总结
知乎大佬删除了好多内容,可惜了。
CSDN大佬:深度遍历暴力求解所有简单环
三、复活赛
与初赛的差异:
转账记录 28W -> 200W
环个数 2914186 -> 2000W
转账金额比例约束 :如[A,B,X],[B,C,Y],要满足0.2 <= Y/X <= 3
算法策略:负三步标记剪枝, 正七步找环,其中后三步只在有标记的结点中寻找。
优化策略:mmap读入,写出; 双vector存图改为动态二维数组存图; 四线程交替分配数据。递归改七层迭代循环。
线上结果:
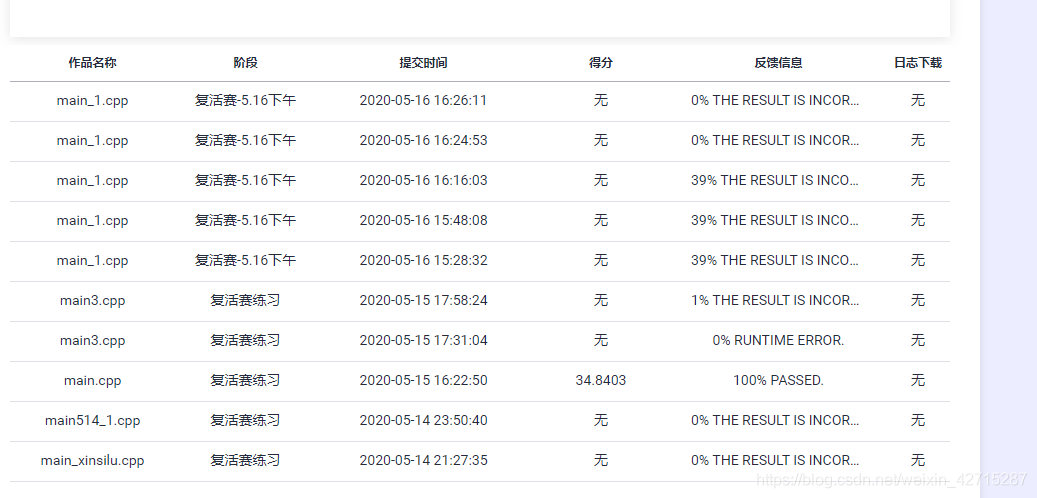
算法思路:
建图部分:(1936万环,1s)
1、mmap映射读入,将数据暂存在一个xxxx*3的二维数组中,同时vector记录所有第一个顶点。
2、使用sort为vector排序;使用unique去除重复元素。
3、unordered_map绑定顶点id值与其序号,按顺序依次加入各顶点信息。
4、借组unordered_map和xxxx*3二维数组绑定各边与顶点。建立子图与父图(正向图与反向图)。
5、正向图需对各边顶点序号排序。
找环部分:(1936万环,14s)(直接用动态二维数组可达8s,但对菊花图易造成空间不够。)
a、针对所有顶点均运行一遍找环程序。顶点分配原则为四线程交替分配。有更好的分配方法,(不要预先给各个线程分配任务,这样可能导致任务分配不均匀。使用动态分配策略:维护一个队列,如果一个线程完成了一个任务,那么就去队列里去取下一个任务。),碍于时间有限,未能实现。
b、每次找环,均只找以该顶点为起点的环。
1、反向迭代三层,标记该顶点的负三邻域。迭代时只遍历结点号比自己大的结点。
2、正向迭代前四层正常逻辑,后三层只遍历有标记的结点。
3、找到环时将环变成字符串类型。且3、4、5、6、7各环存在不同的容器中,以保证环有序。
文件写入部分:(1936万环,0.8s)
1、建立mmap映射。
2、各环容器,各线程交替输出。可保证输出有序。
代码可维护性差,仅供参考。
方案一code
方案二code
其中方案一和二,算法思路一样。但实现方式略有不同。
四、复活赛其他组共享代码
1、ddd2020大佬
2、京津东北赛区 A 榜 rank1
3、粤港澳复赛A榜第2
4、2020华为软挑初赛上合赛区第一,复赛A榜总榜第一,B榜GG
5、2020华为软挑初赛武长赛区第一,复赛武长赛区A榜第二解决方案
6、最终成绩杭厦赛区第6
五、民间数据集
民间数据集
知乎评价




 京公网安备 11010802041100号
京公网安备 11010802041100号