作者:朱劭文_850 | 来源:互联网 | 2024-11-27 15:54
本文介绍了如何利用Python的Pandas库中的sort_values方法对DataFrame对象进行排序。首先通过Numpy库生成随机数据,然后详细解释了DataFrame的创建过程及其参数,并重点探讨了sort_values方法的使用技巧。
在数据分析中,数据排序是一项基本且重要的任务。本文将介绍如何使用Pandas库中的sort_values方法对数据进行排序。首先,我们使用Numpy库的randn函数生成一组随机数据,构建一个完整的DataFrame对象。
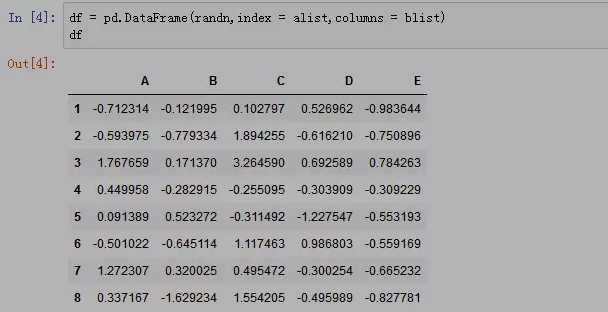
DataFrame是一个二维表格型数据结构,非常灵活。创建DataFrame时可以指定多个参数:
- data: 要转换成DataFrame的数据源,支持多种数据类型如列表、字典等。当数据源为字典时,字典的键通常作为列名。
- index: 数据的行标签。
- columns: 列标签。
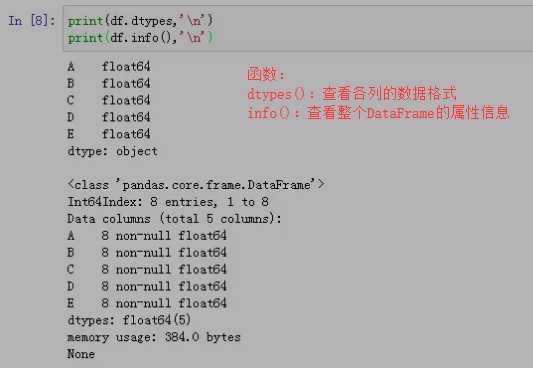
可以通过dtypes属性查看各列的数据类型,而info()方法则提供了关于整个DataFrame的详细信息,包括每列的数据类型、非空值数量等。
对于数据排序,sort_values方法非常强大。它允许用户指定某一列或多列作为排序依据,通过设置by参数实现。同时,ascending参数用于控制排序方向,默认为升序,设置为False可实现降序排列。
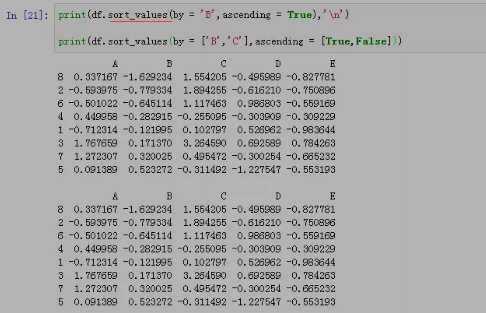
sort_values方法还提供了其他一些有用的参数:
- axis: 指定排序的方向,0表示按行排序,1表示按列排序。
- na_position: 控制缺失值在排序结果中的位置,'last'表示将缺失值放在最后。
- kind: 排序算法的选择,如'quicksort'、'mergesort'等,默认为'quicksort'。
- inplace: 是否在原地修改DataFrame,如果设置为True,则不会返回新的DataFrame,而是直接修改原有的DataFrame。











 京公网安备 11010802041100号
京公网安备 11010802041100号