作者:聆听最遥远的歌声 | 来源:互联网 | 2023-06-14 11:59
1、DataStream API(四):Data Sink1.1、Data Sink介绍sink是程序的数据输出,可以通过StreamExecutionEnvironment.addSink(sink
1、DataStream API(四):Data Sink
1.1、Data Sink介绍
- sink是程序的数据输出,可以通过StreamExecutionEnvironment.addSink(sinkFunction)来为程序添加一个sink。
- flink提供了大量的已经实现好的sink方法,也可以自定义sink
1.2、Data Sink类型
- writeAsText():将元素以字符串形式逐行写入,这些字符串通过调用每个元素的toString()方法来获取
- print() / printToErr():打印每个元素的toString()方法的值到标准输出或者标准错误输出流中
- 自定义输出addSink【kafka、redis】
1.3、Source容错性保证
| Sink | 语义保证 | 备注 |
|---|
| hdfs | exactly once | |
| elasticsearch | at least once | |
| kafka produce | at least once/exactly once | Kafka 0.9 and 0.10提供at least once Kafka 0.11提供exactly once |
| file | at least once | |
| redis | at least once | |
1.4、Flink内置Connectors
- A p a c h e K a f k a ( s o u r c e / s i n k ) \color{red}{Apache Kafka (source/sink)}ApacheKafka(source/sink)
- Apache Cassandra (sink)
- Elasticsearch (sink)
- Hadoop FileSystem (sink)
- RabbitMQ (source/sink)
- Apache ActiveMQ (source/sink)
- R e d i s ( s i n k ) \color{red}{Redis (sink)}Redis(sink)
2、自定义Sink
2.1、实现方法即依赖
- 实现自定义的sink
(1)、实现SinkFunction接口
(2)、或者继承RichSinkFunction - 参考org.apache.flink.streaming.connectors.redis.RedisSink
2.2、实例:Redis Sink
2.2.1、相关依赖
需要添加依赖
Maven仓库
搜索 flink-connector-redis 依赖:
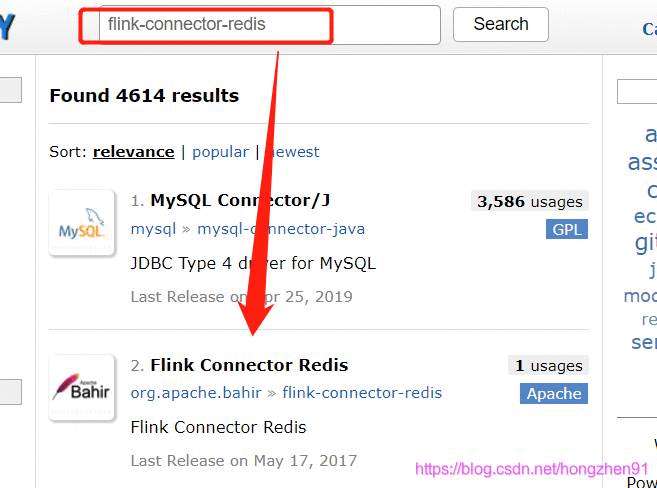
org.apache.bahir
flink-connector-redis_${scala.version}
1.0
2.2.2、Java代码实现
完整程序:
package com.Streaming.custormSink;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.redis.RedisSink;
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommand;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisCommandDescription;
import org.apache.flink.streaming.connectors.redis.common.mapper.RedisMapper;
/**
* @Author: Henry
* @Description: 接收socket数据,把数据保存到redis中(list格式)
* 保存到Redis中数据一般采用两种格式:list或hashmap
*
* lpush list_key value
* @Date: Create in 2019/5/12 22:29
**/
public class StreamingDemoToRedis {
public static void main(String[] args) throws Exception{
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource text = env.socketTextStream(
"master", 9000, "\n");
//input: l_words word , 其中 l_words 代表 list 类型
//对数据进行组装,把string转化为tuple2
DataStream> l_wordsData = text.map(
new MapFunction>() {
@Override
public Tuple2 map(String value) throws Exception {
return new Tuple2<>("l_words", value);
}
});
//创建redis的配置
FlinkJedisPoolConfig cOnf= new FlinkJedisPoolConfig.Builder()
.setHost("master").setPort(6379).build();
//创建redissink
RedisSink> redisSink = new RedisSink<>(
conf, new MyRedisMapper());
l_wordsData.addSink(redisSink);
env.execute("StreamingDemoToRedis");
}
public static class MyRedisMapper implements RedisMapper> {
//表示从接收的数据中获取需要操作的redis key
@Override
public String getKeyFromData(Tuple2 data) {
return data.f0;
}
//表示从接收的数据中获取需要操作的redis value
@Override
public String getValueFromData(Tuple2 data) {
return data.f1;
}
@Override
public RedisCommandDescription getCommandDescription() {
return new RedisCommandDescription(RedisCommand.LPUSH);
}
}
}
2.2.3、Scala代码实现
完整代码如下:
package cn.Streaming.custormSink
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.redis.RedisSink
import org.apache.flink.streaming.connectors.redis.common.config.FlinkJedisPoolConfig
import org.apache.flink.streaming.connectors.redis.common.mapper.{RedisCommand, RedisCommandDescription, RedisMapper}
/**
* @Author: Henry
* @Description:
* @Date: Create in 2019/5/14 22:37
**/
object StreamingDataToRedisScala {
def main(args: Array[String]): Unit = {
//获取socket端口号
val port = 9000
//获取运行环境
val env: StreamExecutiOnEnvironment= StreamExecutionEnvironment.getExecutionEnvironment
//链接socket获取输入数据
val text = env.socketTextStream("master",port,'\n')
//注意:必须要添加这一行隐式转行,否则下面的flatmap方法执行会报错
import org.apache.flink.api.scala._
val l_wordsData = text.map(line=>
("l_words_scala",line))
val cOnf= new FlinkJedisPoolConfig.Builder()
.setHost("master")
.setPort(6379)
.build()
val redisSink = new RedisSink[Tuple2[String,String]](conf,new MyRedisMapper)
l_wordsData.addSink(redisSink)
//执行任务
env.execute("Socket window count")
}
class MyRedisMapper extends RedisMapper[Tuple2[String,String]]{
override def getKeyFromData(data: (String, String)) = {
data._1
}
override def getValueFromData(data: (String, String)) = {
data._2
}
override def getCommandDescription = {
new RedisCommandDescription(RedisCommand.LPUSH) // 具体操作命令
}
}
}
2.2.4、运行结果
先在一个终端启动redis server服务:
./src/redis-server
再在另一个终端连接服务:
./src/redis-cli

开启socket终端:
nc -l 9000

在IDEA中点击“Run”运行代码:
通过 nc 终端输入数据,查询 redis 数据库:








 京公网安备 11010802041100号
京公网安备 11010802041100号