作者:佳佳的梦Aas | 来源:互联网 | 2023-05-18 22:08
Ambari 作为一个出色的集群管理软件,为第三方服务提供了丰富的功能。其中 Ambari Metrics System 为第三方服务以及集群机器提供了性能相关的监察功能。本文主要讲解 Ambari Metrics 框架的原理,以及如何集成该系统与第三方服务。
Ambari 现状
Ambari 最新的发行版已经到了 2.2.1 的版本,提供了更多的管理功能,例如在 2.2 的版本中支持了 Express Upgrade(AMBARI-13407)、User Timezones(Ambari-13293)以及 Export Metrics Widget Graph(AMBARI-13313)等功能。想要了解详细内容的读者,可以在 Apache Ambari 的 Feature 页面中查看。Ambari 从 2.1 的版本中支持了配置化扩展 Ambari Metrics 以及 Widget 的功能,这也是本文所要阐述的。
Ambari Metrics 原理
Ambari Metrics System 简称为 AMS,它主要为系统管理员提供了集群性能的监察功能。Metrics 一般分为 Cluster、Host 以及 Service 三个层级。Cluster 和 Host 级主要负责监察集群机器相关的性能,而 Service 级别则负责 Host Component 的性能。AMS 涉及的模块如下图所示:
图 1. Ambari Metrics 原理图
#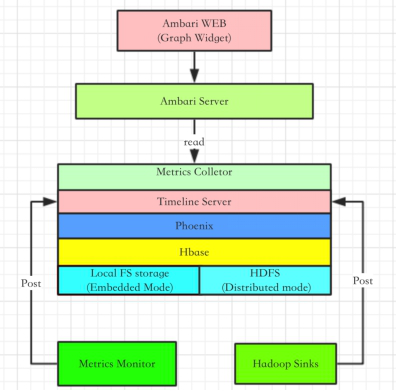
对于 AMS 本身来说,涉及的主要模块有 Metrics Monitor、Hadoop Sinks 以及 Metrics Collector。AMS 也是一个 Master-Slave 结构的框架。Master 模块便是 Metrics Collector,Slave 则是 Metrics Monitor 和 Hadoop Sinks。Salve 模块负责收集信息,并发送给 Collector。当然 Metrics Monitor 和 Hadoop Sinks 也有不同的职责,前者主要负责收集机器本身相关的指标,例如 CPU、Mem、Disk 等;后者则负责收集 Hadoop 相关 Service 模块的性能数据,例如该模块占用了多少 Mem,以及该模块的 CPU 占用率等。在 Ambari 2.1 之后的版本中(包含 2.1)支持了配置化 Widget 的功能。Widget 也就是 Ambari Web 中呈现 Metrics 的图控件,它会根据 Metrics 的数值,做出一个简单的聚合运算,最终呈现在图控件中。
AMS 会不断的收集集群相关的性能数据,并最终由 Metrics Collector 中的 Timeline Server 保存到 Hbase 数据库中(通过 Phoenix)。随着时间的推移,Metrics 数据会变得非常庞大,因此 Metrics Collector 支持两种存储模式,Embedded Mode(嵌入模式)和 Distributed Mode(分布式模式)。简单来说,对于在嵌入模式中,Hbase 会以本地文件系统作为存储层,而在分布式模式中,Hbase 则以 HDFS 作为存储层。这样就可以充分利用整个集群的物理存储了。不过目前 AMS 并不支持自动化的数据迁移,也就是说当用户从嵌入模式迁向分布式模式的时候,无法自动的完成 HBase 的数据导出导入。庆幸的是,我们可以通过简单的 HDFS CLI 命令,将整个 Hbase 数据目录从本地拷贝到 HDFS 中,从而完成 Metrics 数据迁移。这里我们还需要注意,如果 AMS 要以分布式模式运行,那么 Metrics Collector 所在的机器必须部署一个 HDFS 的 Data Node 模块。
Ambari Widget
Ambari Widget 的出现进一步提升了 Ambari 的易用性,以及可配置化。之前我们已经讲过 Widget 控件的用途,也就是显示 AMS 收集的 Metrics 属性。不过 Ambari 目前只支持在 Service Summary 页面定制化 Widget 组件。Ambari Widget 主要分为四类:Graph、Gauge、Number 以及 Template,其中前三者较为常用。
Graph 是一种线性或矩形图,它用于显示在某时间内 Service 的某个(可以是多个)Metrics 属性值。效果如下图(5 种 Graph 图):
图 2. Graph 效果图
#
Gauge 一般用于显示百分比,其数值来源于一个(可以是多个)Metrics 经过计算后的值(小于 1)。其效果如下图:
图 3. Gauge 示例图
#
Number 则用于直接的显示一个数值,并可以为其配置一个单位,例如 MB 等。其所显示的数值也是来源于一个或多个 Metrics 属性。
由于 Widget 只支持对 Service Summary 的定制,也就是说 Widget 只支持对 Service Component Metrics 属性的定制。然而同一个 Service 的 Component 可以由多个 Host Component 组成,那么 Widget 就必须经过某一种聚合运算才可以得到一个数值。Ambari 为 Widget 组件提供了 4 中聚合方式,分别是 max、min、avg、sum。简单来说:max 就是 Host Component 收集的同个 metrics 属性的最大值;min 是最小值;avg 是平均值;sum 则是求和。Widget 组件会以 avg 为默认的聚合方式。用户可以在 widget 的配置文件中重写该方式。
Ambari 中预定义的 Metrics 和 Widget
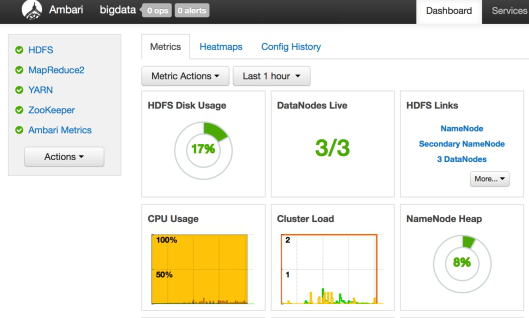
在详细介绍具体的预定义之前,我们先看下 Ambari Web 中相关的页面。首先便是 Cluster Dashboard 中所显示的 Metrics Widget 控件,这些便是所谓的 Cluster 级 Metrics,如图 4。
图 4. Cluster 级 Metrics
#
在机器的 Component 页面中,我们便可以看到该机器相关的 Metrics 信息。并且,用户可以在一部分 Service 的 Summary 页面中可以看到该 Service 相关的 Metrics 信息。目前,Ambari 只为 YARN、HDFS 以及 Ambari Metrics 等部分 Service 预定义了 Metrics 和 Widget 信息。这里我们就以 YARN 为例,看看如何为一个 Service 定义 Ambari 的 Metrics 和 Widgets。首先我们先看下 Ambari Server 上 HDFS 的目录结构,如图 5。
图 5. HDFS 的目录结构
#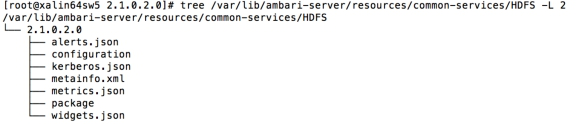
在目录结构中,我们可以看到 metrics.json 和 widgets.json 这两个文件。在 Ambari 的 Web 上部署一个 Service 的时候,Ambari Server 就会读取这两个 JSON 文件中的定义。对于 HDFS 来说,其 Metrics 和 Widget 的配置相当丰富和繁杂,因而这里我们只简单的看下这两个文件中的一小段。
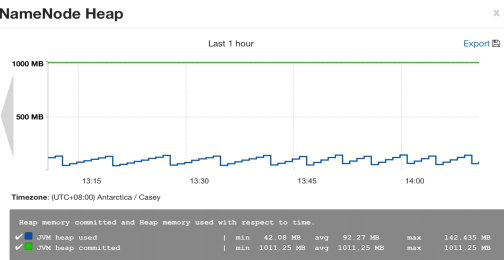
这里我们先在 Ambari Web 中打开 HDFS 的 Summary 页面,并观察名为 NameNode Heap 的控件,如图 6(这是一个摘要图,可以点击该图,进而查看详细图)。
图 6. NameNode Heap 摘要图
#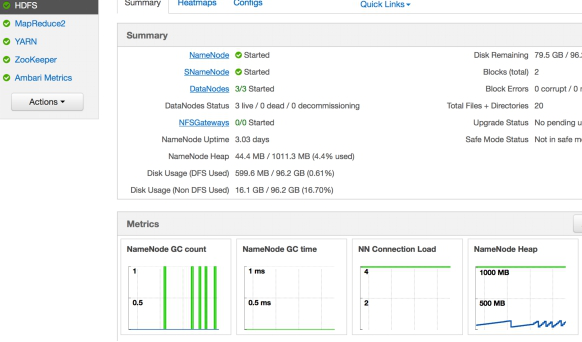
顾名思义,我们可以了解该图是为了记录 NameNode 进程堆内存的使用情况。那么在 AMS 系统中,就必然有一个模块负责收集该信息并发送给 Metrics Collector。最后便需要定义一个这样的图控件,来读取和显示收集到的 Metrics 信息。如下便是该 Widget 的定义内容:
清单 1.NameNode Heap 的定义(widget.json)
{
"widget_name": "NameNode Heap",
"description": "Heap memory committed and Heap memory used with respect to time.",
"widget_type": "GRAPH",
"is_visible": true,
"metrics": [
{
"name": "jvm.JvmMetrics.MemHeapCommittedM",
"metric_path": "metrics/jvm/memHeapCommittedM",
"service_name": "HDFS",
"component_name": "NAMENODE",
"host_component_criteria": "host_components/metrics/dfs/FSNamesystem/HAState=active"
},
{
"name": "jvm.JvmMetrics.MemHeapUsedM",
"metric_path": "metrics/jvm/memHeapUsedM",
"service_name": "HDFS",
"component_name": "NAMENODE",
"host_component_criteria": "host_components/metrics/dfs/FSNamesystem/HAState=active"
}
],
"values": [
{
"name": "JVM heap committed",
"value": "${jvm.JvmMetrics.MemHeapCommittedM}"
},
{
"name": "JVM heap used",
"value": "${jvm.JvmMetrics.MemHeapUsedM}"
}
],
"properties": {
"display_unit": "MB",
"graph_type": "LINE",
"time_range": "1"
}
}
如上的配置代码主要由 4 部分组成,分别是 widget 控件的描述内容、metrics 的匹配关系、value 的计算以及控件图的显示属性。例如最开始的几行中配置了该 widget 的名称为“NameNode Heap”以及 Description 信息。widget_type 则用于定义该图的类型,这里是 Graph。is_visible 用于配置该图是否可见。metrics 段就是配置 widget 组件所绑定的 metrics 属性。在如上的代码中,widget 绑定了 jvm.JvmMetrics.MemHeapCommittedM 和 jvm.JvmMetrics.MemHeapUsedM 两个 metrics 属性。values 段则定义如何使用绑定的 metrics 属性值。Name 用于显示图中该属性的名称,value 则是一个数学表达式,定义如何使用(计算,例如加减乘除)metric 值。如上代码中的定义,表示直接使用 metric 值,并未经过计算。properties 段则定义了该 Graph 图的属性。display_unit 定义了显示的单位(也可以用“%”等符号作为单位)。graph_type 定义了 Graph 图的类型,可以是 LINE(线形图)或 STACK(矩形图)。time_range 则为取样时间。下图则为 NameNode Heap 的示例图(详细图)。
图 7. NameNode Heap 详细图
#
在清单 1 中,我们讲解了 HDFS widget.json 的一段配置代码,下面来让我们再找到对应的 Metrics 配置代码。首先我们打开 HDFS 的 metrics.json,并分别搜索字符串“jvm.JvmMetrics.MemHeapUsedM”和“jvm.JvmMetrics.MemHeapCommittedM”找到如下的示例代码(我已将两段黏贴在一起):
清单 2.metrics.json
{
"NAMENODE": {
"Component": [
{
"type": "ganglia",
"metrics": {
"default": {
"metrics/jvm/memHeapUsedM": {
"metric": "jvm.JvmMetrics.MemHeapUsedM",
"unit": "MB",
"pointInTime": false,
"temporal": true
},
"metrics/jvm/memHeapCommittedM": {
"metric": "jvm.JvmMetrics.MemHeapCommittedM",
"unit": "MB",
"pointInTime": true,
"temporal": true
}
}
}
}]
}
}
我们可以从如上的代码中看到该 Metrics 的属性是为 HDFS 的 Namenode 配置的。在 type 一项,配置了该 metrics 请求的实现类型。了解过 ganglia 的读者,应该知道 ganglia 也是 Apache 下面的一个开源框架,其目的就是为了实现集群性能的监控,这里就不再赘述了。在 metrics 的字段中,则详细定义了每个 metrics 的属性。代码中“metrics/jvm/memHeapUsedM”和“metrics/jvm/memHeapCommittedM”都是 metrics 的 key,这个 key 对一个 service 来说是唯一的,用于唯一鉴别一个 metric 请求。metric 定义了名称,unit 则是单位。pointInTime 表示该 Metric 属性是否允许时间段的查询,如果为 false 则代表不允许,这样就会只取最后一次的值。Temporal 代表是否支持时间段的查询请求,这里一般都是 true。因为 Widget 配置有 time range 的属性,如果 temporal 是 false,widget 组件则无法显示任何数据。
更多详情见请继续阅读下一页的精彩内容: 2016-12/138147p2.htm







 京公网安备 11010802041100号
京公网安备 11010802041100号